Vous qui cherchez LA checklist ultime pour réaliser un audit seo technique en 2024, arrêtez de creuser, la voilà.
Cette checklist prend en compte les points les plus importants de l’audit seo en fonction des contraintes techniques et des exigences SEO actuelles.
Bien sûr, je m’adresse aux administrateurs de site mais aussi aux auditeurs externes qui trouveront ici toutes les étapes pour auditer le site d’un client.
Bonus: cliquez ici pour accéder à ma checklist d’audit SEO contenant 207 tests pour réaliser un audit SEO technique complet.
J’ai suivi un ordre logique pour valider les points de cette checklist,
et à chaque point est associé un outil et une méthode de vérification des éléments à passer en revue.
Quoi qu’il en soit, on utilisera beaucoup l’outil SEO Spider de la suite Screaming Frog, logiciel d’audit technique et d’analyse On-Page par excellence.
Il possède une version freemium qui permet d’analyser les sites qui ont jusqu’à 500 URLs.
Pour certaines fonctionnalités par contre, même en dessous de 500 URLs, c’est payant.
J’explorerai d’autres alternatives, mais qui peuvent être payantes également : par exemple j’utilise beaucoup SEMrush.
D’autres outils SEO ou astuces peuvent être employés pour votre audit, et même parfois de simples vérifications « à la main » (ou plutôt à l’œil).
Avant de s’attaquer au gros du sujet, un examen du site et un premier audit vous permettront de vous familiariser avec certaines problématiques.
Passez votre site en revue…
Et prenez des notes sur ce qui semble correspondre ou non à un site performant.
Les rapports des différents outils vous permettront ensuite de mieux comprendre ce que vous aurez remarqué.
L’audit de Site de Semrush trouve presque toutes les failles techniques de votre site en y analysant plus de 130 facteurs SEO.
Et il le fait par ordre d’importance.
Si vous avez un compte Semrush, ne passez pas à côté de l’audit…
… mais profitez-en également pour faire un tour sur d’autres rapports concernant votre site et vos concurrents pour en noter plus tard l’évolution.
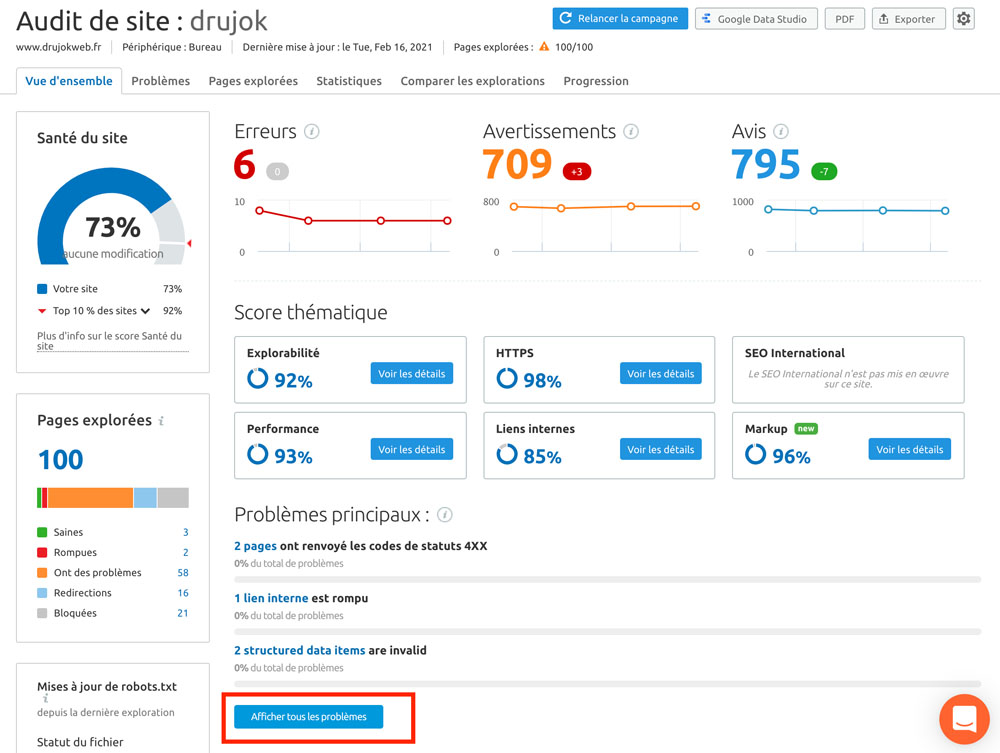
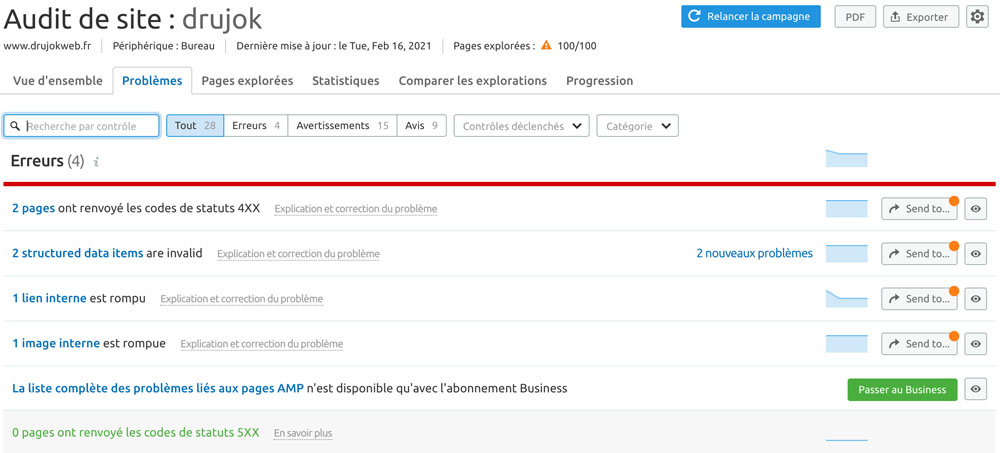
Réparez les erreurs les plus importantes avant de passer à un audit détaillé.
Un certain nombre d’erreurs techniques peuvent poser problème pour le référencement et les performances de votre site.
Mais la première chose à vérifier, c’est bien les réglages qui permettent son indexation pour qu’avant d’être performant, il soit effectivement accessible
-du moins pour les pages que vous souhaitez voir apparaître sur les SERPs -.
Utilisez l’opérateur de recherche site: (tel que site:drujokweb.fr) dans Google pour vérifier le nombre approximatif de pages indexées.
Normalement, la page d’accueil devrait être le premier résultat de cette recherche.
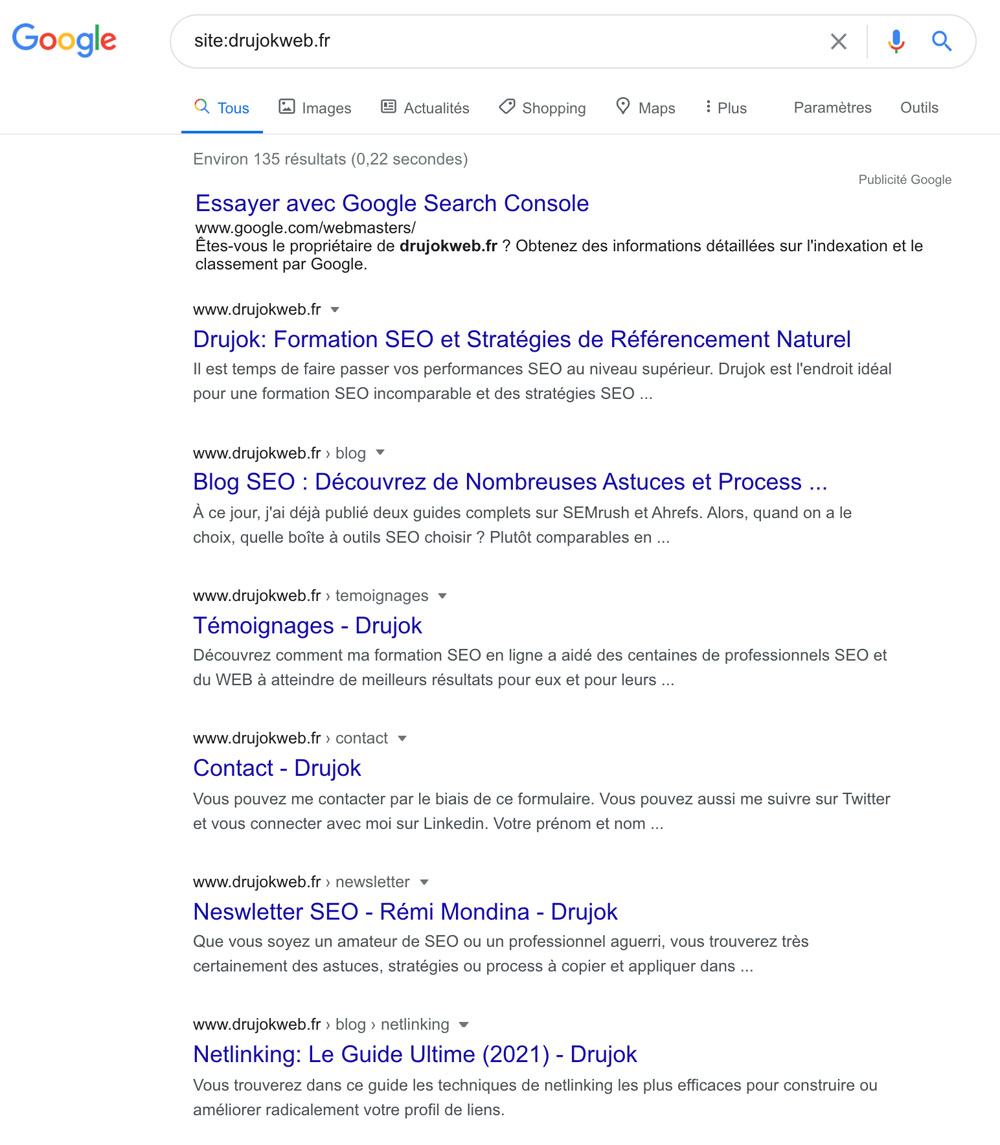
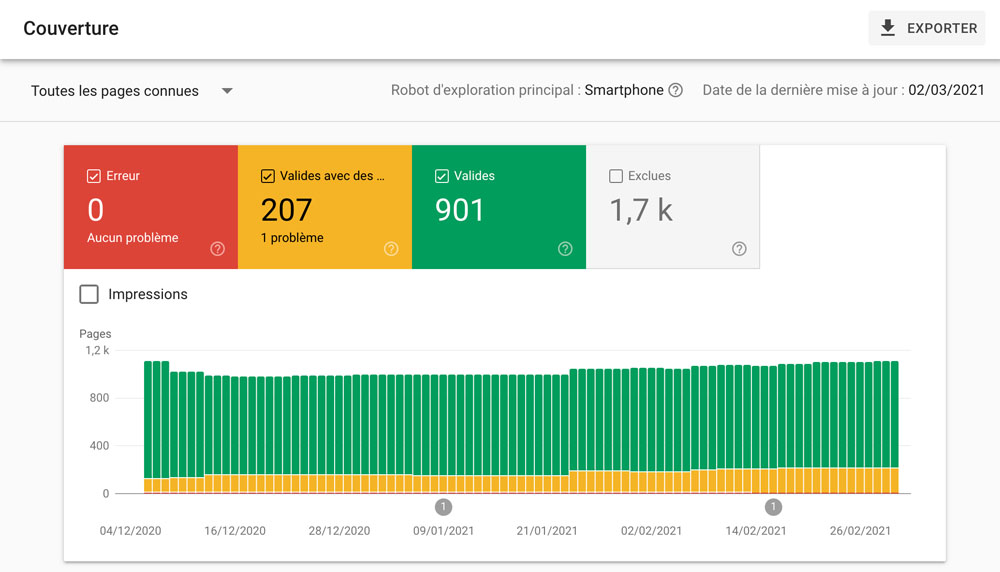
Assurez-vous que cela corresponde à peu près au nombre de pages canoniques (indexables) dans la Google Search Console :
Index > Couverture > Valides
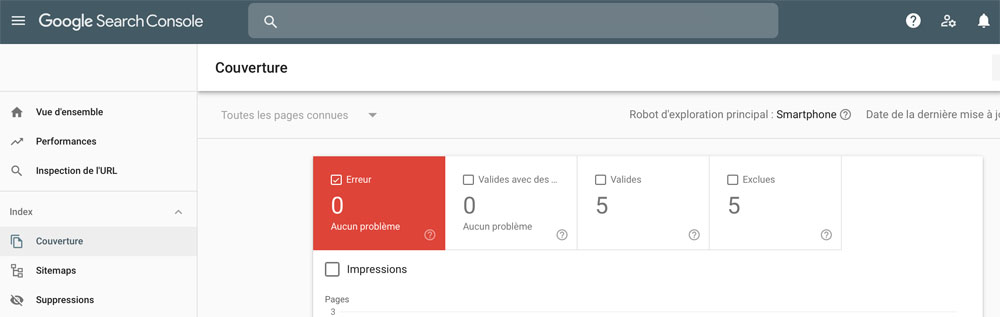
Une trop grande différence devrait attirer votre attention sur l’indexation de vos pages.
Pour cela, il faut que vous jetiez directement un œil aux résultats Google, au moins les 5 premières pages.
Utilisez le même opérateur de recherche site:
Plusieurs pages de résultats vous donneront un bon aperçu des pages que le moteur de recherche indexe.
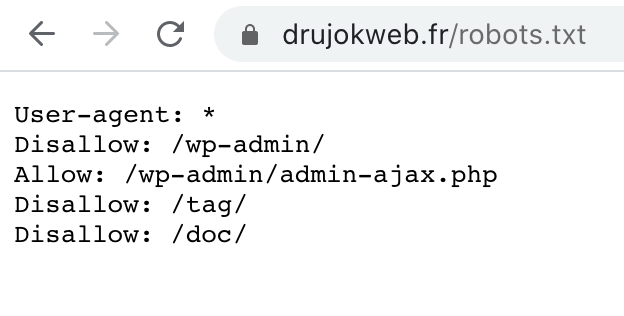
Il suffit d’aller à l’adresse http://votresite.com/robots.txt.
(Pour mon site ce serait http://drujokweb.fr/robots.txt)
Vous pouvez aussi utiliser l’outil gratuit SEOptimer qui vous fournira un audit avec repérage de fichier robots.txt.
Il arrive de faire des erreurs dans le contenu de son fichier robots.txt.
Cela peut conduire à une absence d’exploration par les robots de pages qui devraient figurer dans les moteurs de recherche.
Elles pourront être indexées, recevoir des liens… mais pas crawlées et donc pas bien positionnées.
Vous pouvez effectivement choisir de bloquer certaines ressources sans intérêt pour les moteurs de recherche.
C’est le cas des URLs avec paramètres, des pages au contenu faible, etc.
Même si le fichier robots.txt ne contient pas d’erreur de syntaxe, il peut y avoir d’autres types d’erreurs…
Comme des erreurs dans le nom d’un répertoire bloqué.
Cette balise située dans l’élément <head> d’une page indique aux robots si la page doit être indexée ou non.
Une valeur "noindex" bloque l’indexation de la page.
La présence de valeur « noindex » sur certaines pages se vérifie dans Overview > Crawl Data > Directives > Noindex.
Pour tout comprendre rapidement sur cette balise, voici un article très clair.
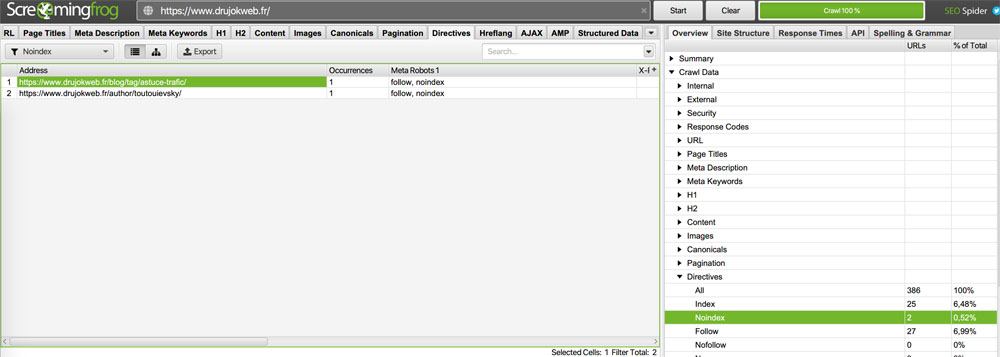
Passez en revue vos pages au contenu pauvre pour voir si votre site ne profiterait pas de leur blocage par la balise meta robots.
L’indexation d’une page web peut aussi être bloquée à travers une entête HTTP X-Robots-Tag.
Vous dénicherez la présence d’une instruction « noindex » dans la même section Directives de Screaming Frog, colonne X-Robots-Tag 1 (visible en défilant vers la droite).
Si cela arrive, c’est l’instruction la plus restrictive qui s’appliquera (résultant probablement dans une restriction d’indexation).
Aujourd’hui, ces pages ont un rôle à jouer dans le calcul de votre E-A-T.
Expertise – Authoritativeness – Trustworthiness signifie Expertise, Autorité et Fiabilité.
Il va de soi que la transparence de vos politiques et conditions sont une preuve de votre fiabilité pour Google
Il s’agit d’une ligne à ajouter dans le fichier robots.txt pour indiquer l’emplacement de votre fichier sitemap.xml (si vous en avez un).
Elle peut être située n’importe où et ressemble à ça :
Sitemap: http://www.votresite.fr/sitemap.xml
Quoi qu’il en soit, indiquer l’emplacement du sitemap dans le robots.txt ne devient important que si l’adresse n’est pas standard ou qu’il y a plusieurs sitemaps.
Dans ce dernier cas de figure, ajoutez simplement une nouvelle ligne Sitemap: pour chaque adresse différente.
Ne pas avoir de fichier sitemap peut affecter l’accession des moteurs de recherche au site, et en particulier aux pages profondes.
Rendez-vous dans Index > Sitemaps.
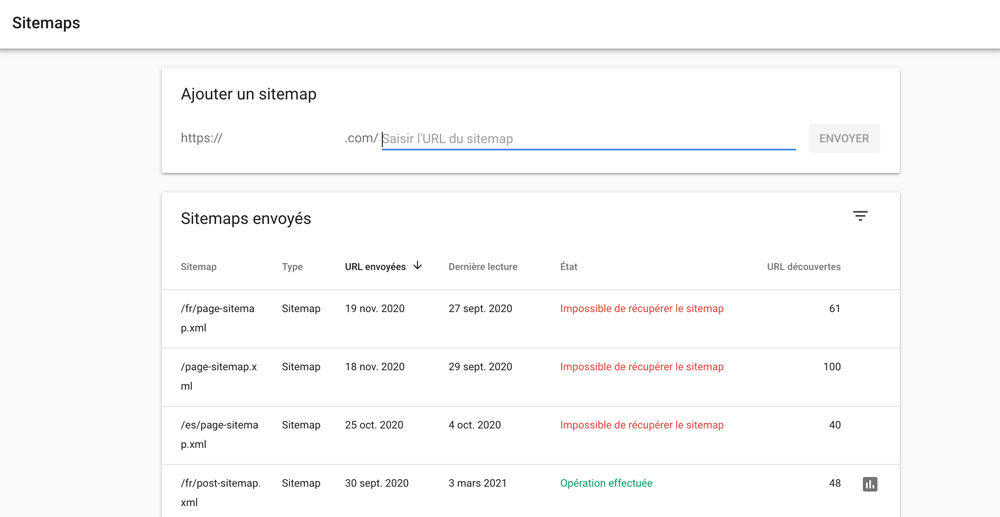
Si un sitemap a un problème, vous pouvez cliquer dessus pour l’examiner.
Google vous renseigne sur les sitemaps dans cet article de sa documentation.
Vous pouvez vérifier l’existence d’un sitemap de plusieurs autres façons :
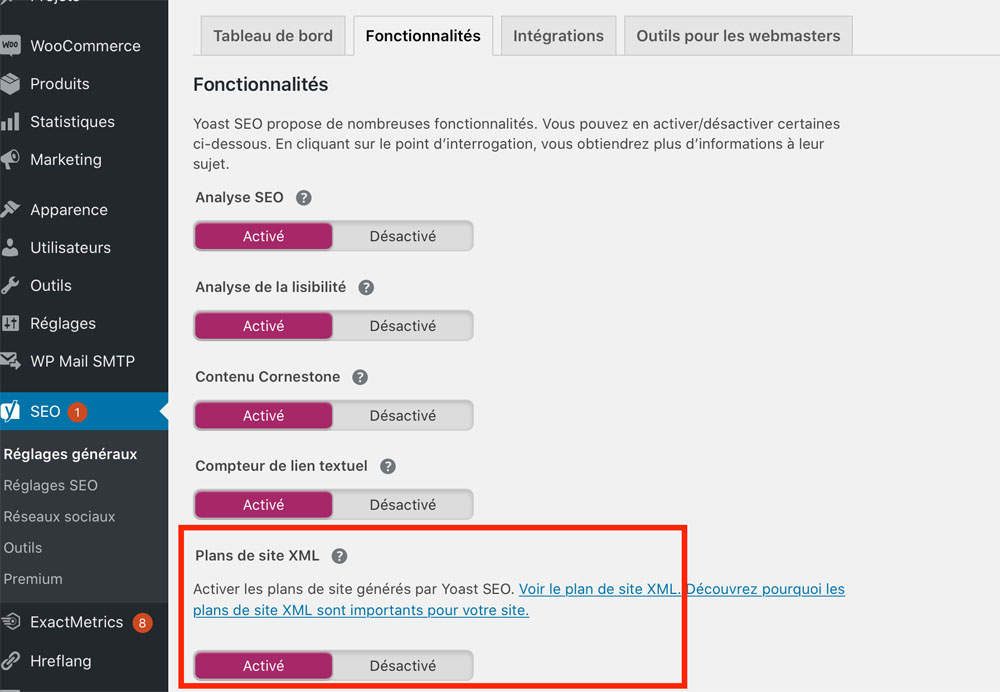
Ici le plan de site est activable et consultable avec l’extension Yoast SEO.
En toute logique, un plan de site devrait contenir toutes les pages indexables et canoniques d’un site.
Mais il arrive qu’il y ait des erreurs.
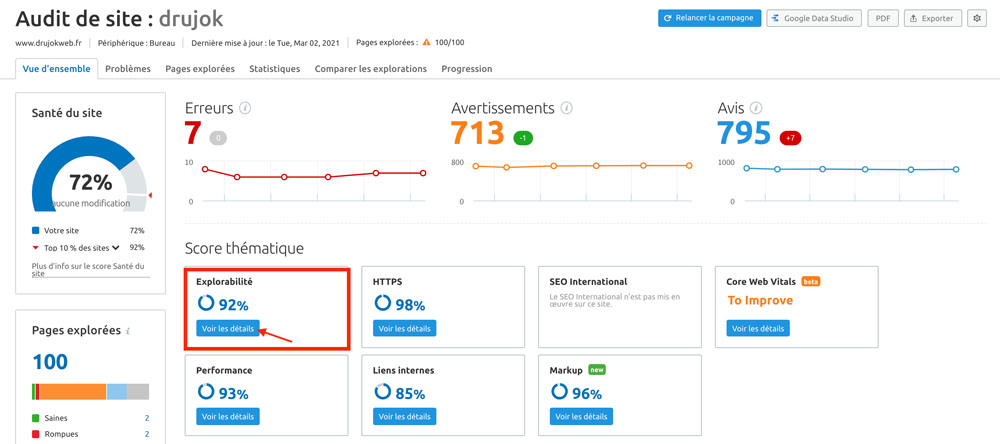
Pour configurer l’audit des sitemaps avec Screaming Frog, il faut la version payante.
Ici je continue avec SEMrush (version payante nécessaire également pour crawler plus de 100 pages).
Le chemin : Site Audit > Vue d’ensemble > Explorabilité puis Pages dans sitemap.
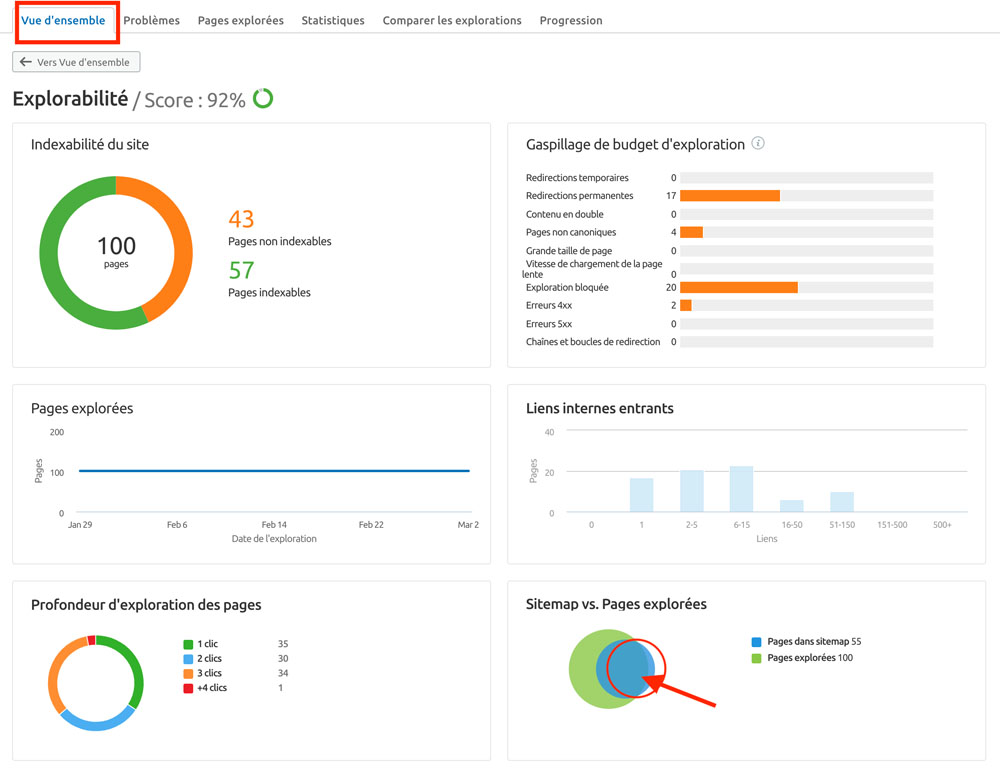
Cela vous donne une vue des pages explorées avec un filtre (non accessible autrement) : « Présent dans sitemap ».
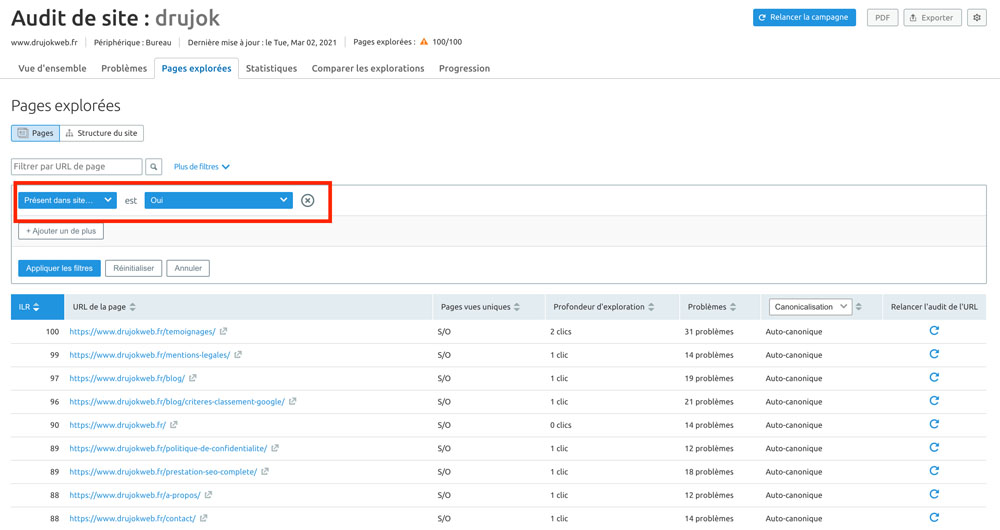
Cela se fait directement dans le fichier.
Un sitemap images liste toutes les URLs des images du site – en plus des URLs sur lesquelles elles apparaissent -.
Il commence à avoir de l’intérêt lorsque le site a beaucoup d’images importantes et qu’il gagne du trafic grâce à Google Images.
Ce sitemap peut être combiné avec le sitemap standard ou être créé à part.
La deuxième option est la plus viable pour un suivi facile sur la Google Search Console.
Par contre, ce sitemap n’a de raison d’être que si le site héberge ses vidéos sur son propre serveur.
Pour que vos sous-domaines soient correctement indexés, ils doivent bien sûr être ouverts à l’exploration des robots et avoir leurs propres fichiers robots.txt et sitemap.xml.
Votre site est bien indexé : félicitations !
Avec une architecture optimisée et rationalisée, il sera d’autant plus accessible par les utilisateurs et les moteurs de recherche.
Toutes les pages ne doivent pas être accessibles en un clic à partir de la page d’accueil.
Vous pouvez utiliser les Visualisations disponibles dans la barre de menu supérieure de Screaming Frog SEO Spider.

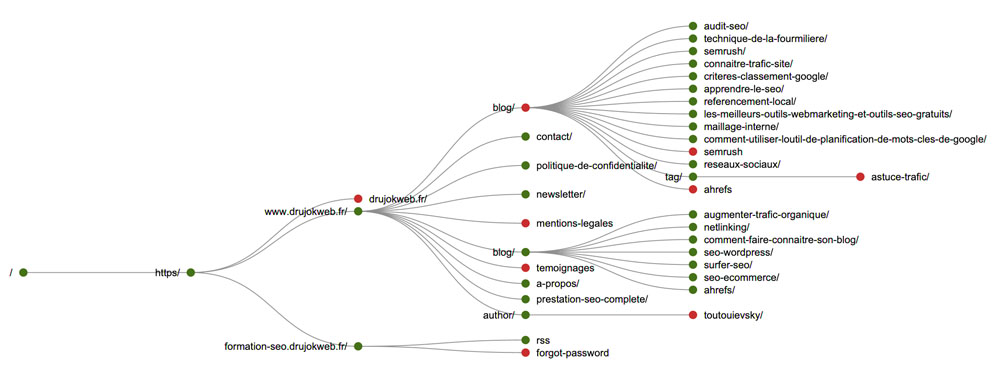
Pour une analyse approfondie, vous pourrez utiliser l’outil Gephi.
Une structure trop profonde, ce sont des pages à 4 ou 5 clics de profondeur et beaucoup de pages orphelines.
Sur les très gros sites web, c’est vraiment indispensable.
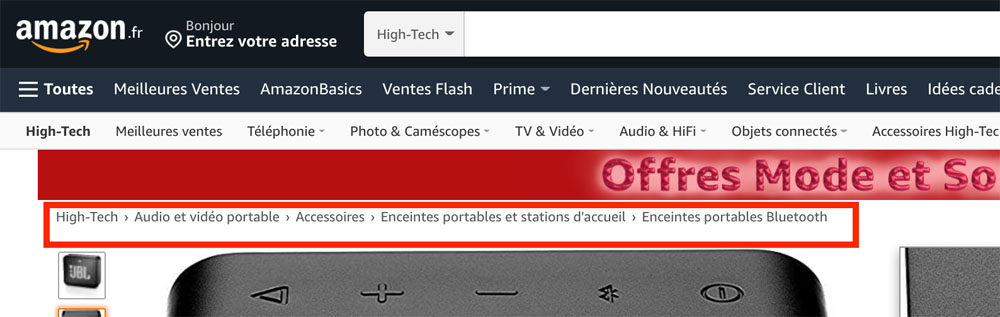
Consultez ce document de Google pour plus d’information sur le fil d’Ariane.
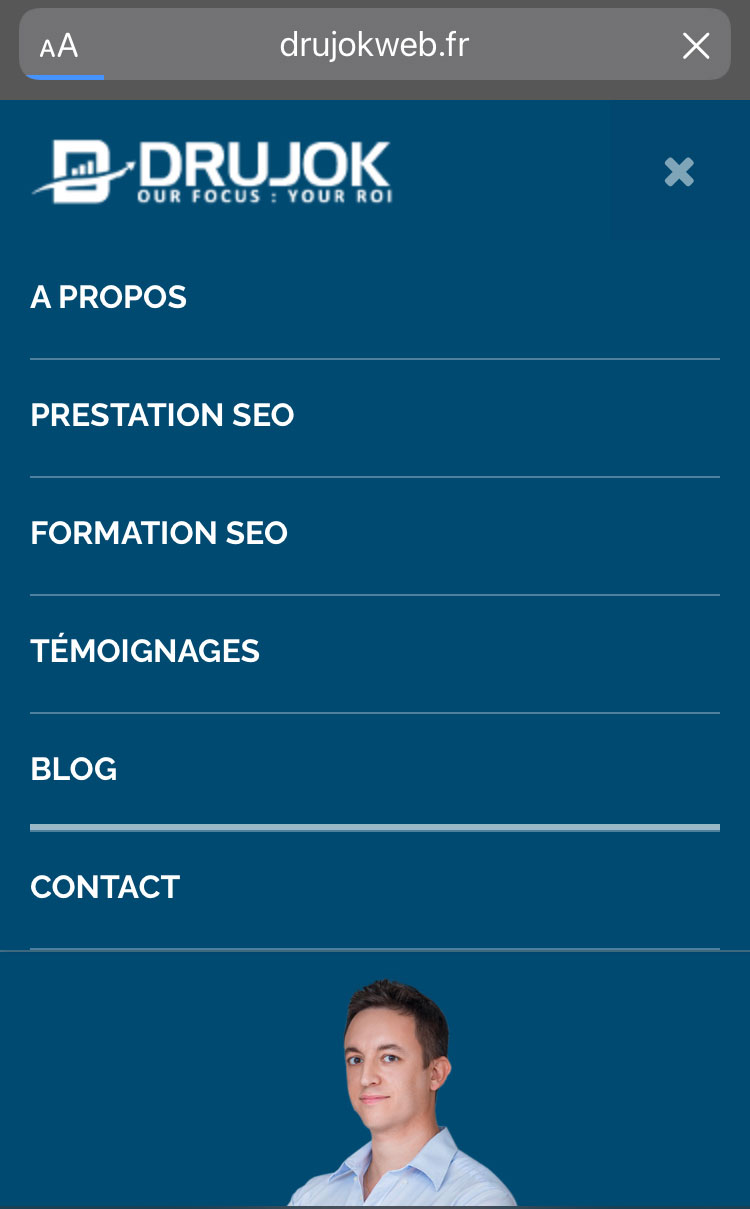
La page d’accueil doit avoir des liens vers les principales plateformes / pages catégories, ainsi que vers les pages d’information et de contact.

La navigation en HTML assure une expérience plus accessible.
Rien n’interdit d’utiliser des élements de navigation en JavaScript mais simplement, ils ne doivent pas constituer la navigation principale.
Le footer permet d’intégrer des élements de menu qui n’ont pas pu être implémentés dans le menu principal parce qu’ils sont moins primordiaux au premier abord.
Ça n’empêche pas qu’ils soient indispensables au final…
Vos utilisateurs vont y chercher des informations cruciales.
Par conséquent, votre pied de page ne doit pas être un fourre-tout qui sert à caser des mots-clés.
Les liens de navigation doivent être construits avec des balises liste.
C’est important pour les sites qui contiennent beaucoup de JavaScript.
Pour faire cela, comparez le code source au rendu HTML dans votre navigateur.
Faites cela directement sur la version mobile de votre site.
Les menus s’ouvrent-ils correctement, les liens aboutissent-ils ?
Est-ce bien un nouvel onglet ou une nouvelle page qui s’ouvre ?
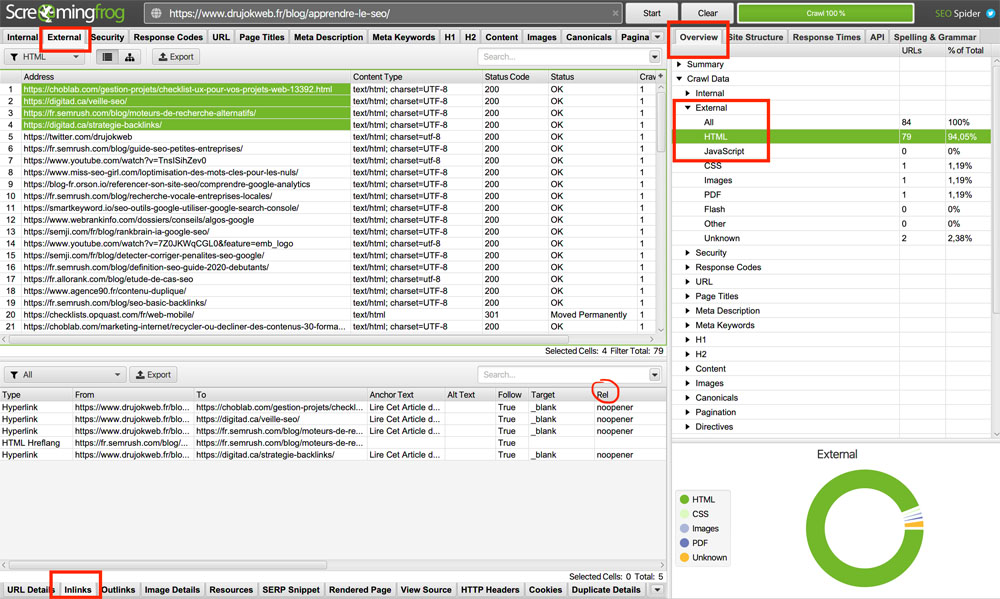
Les liens sponsorisés doivent être marqués rel="sponsored" tandis que que les liens outbound qui n’ont pas besoin de transmettre de jus de lien ont l’attribut rel="nofollow".
Vous pouvez utiliser Screaming Frog pour jeter un œil sur les liens externes des pages qui en possèdent beaucoup.
Allez dans l’onglet External et sélectionnez les liens trouvés pour en connaître les détails.
Un seul et même lien distribué sur l’ensemble d’un site (en footer par exemple) peut éventuellement être revu manuellement et être la cause d’une pénalité Google.
Une bonne règle à appliquer est l’insertion d’une balise canonique dans toutes les pages canoniques du site web.
Vérifiez que toutes vos pages importantes soient indiquées comme canoniques.
Rendez-vous dans Overview > Crawl Data > Canonicals > All
Vérifiez qu’aucune page authentique ne soit canonisée (renvoyant vers une autre URL comme la page d’accueil).
En effet, une balise canonique est une indication plus qu’un ordre.
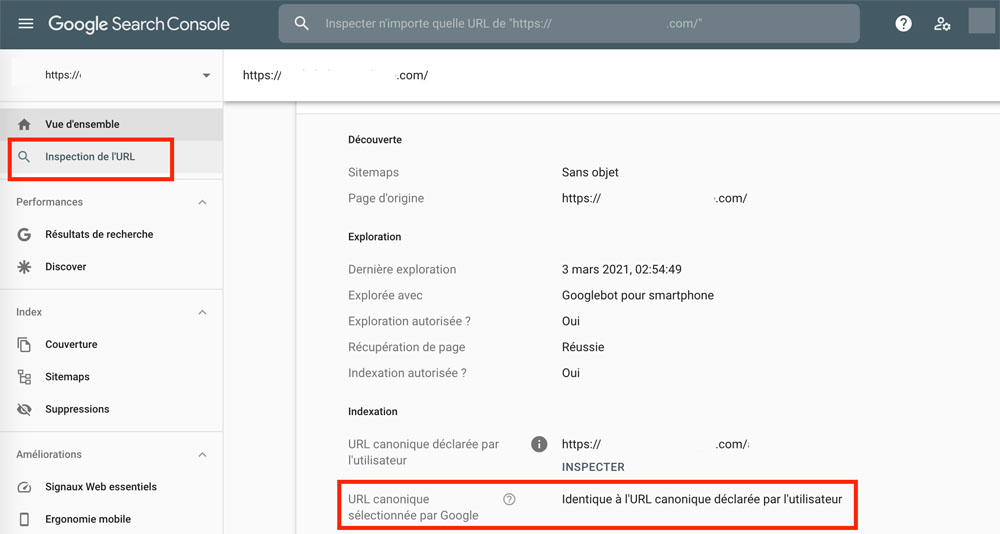
Cela se vérifie dans l’outil d’inspection d’URL de la Search Console.
Pour vérifier toutes vos URLs canonisées, vous pouvez les regrouper en choisissant de classer vos URLs en fonction de leur indexabilité sur Screaming Frog.
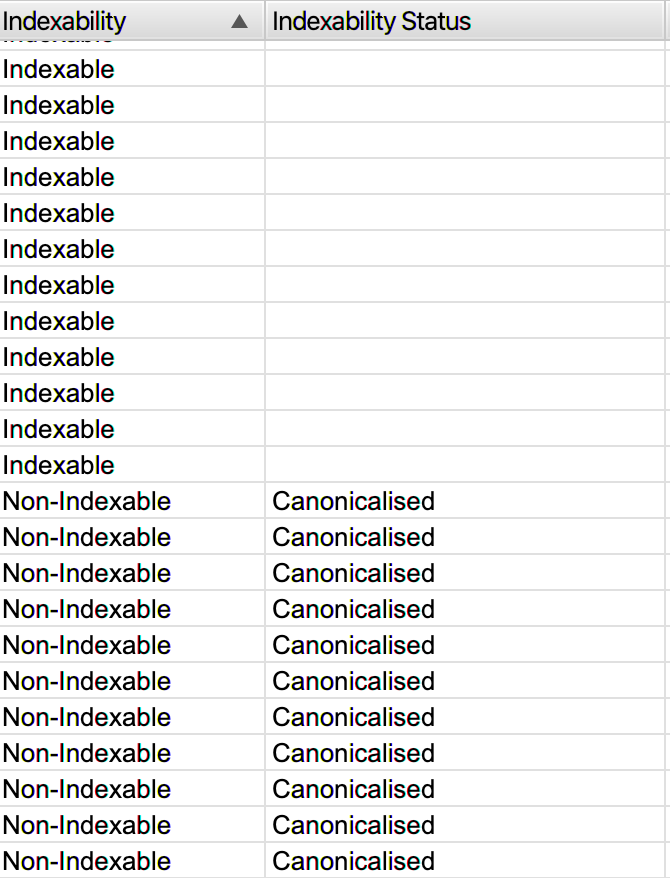
Copiez ensuite le lien de l’URL de votre choix pour l’analyser avec la console :
L’analyse On-Site et On-Page va assurer que les informations que renvoient votre site soient aussi claires que possible,
notamment pour que Google puisse juger de la pertinence et de la richesse du contenu.
Utilisez Screaming Frog pour analyser des URLs par lots.
Ne portez pas atteinte à votre taux de clics pour une bête question d’URL qui n’inspire pas confiance.
La base c’est donc d’avoir un maximum d’URLs propres (composées de mots), courtes, mémorables voire partageables.
Si des URLs ne modifient pas le contenu, elles doivent posséder un lien canonique vers leur version sans paramètre.
L’ex ingénieur Google Matt Cutts a laissé entendre que les mots-clés dans l’URL sont effectivement SEO-friendly.
Dans tous les cas, il faut considérer qu’une URL qui affiche un mot-clé est certainement plus user-friendly qu’une suite de chiffres et de caractères.
Pour une question de pertinence affectant à la fois les utilisateurs et les moteurs de recherche, les URLs doivent être dans la même langue que les pages associées.
Ils rendent l’adresse plus lisible.
Encore une fois, cela fait autant plaisir aux utilisateurs qu’aux robots.
Comme la plupart des balises importantes (et peut-être encore plus que toutes les autres), la balise
<title>
renseigne Google sur le sujet de la page.
Pensez-donc à écrire un contenu unique s’il en manque.
Vous trouverez le contenu manquant dans Overview > Craw Data > Page Titles > Missing.
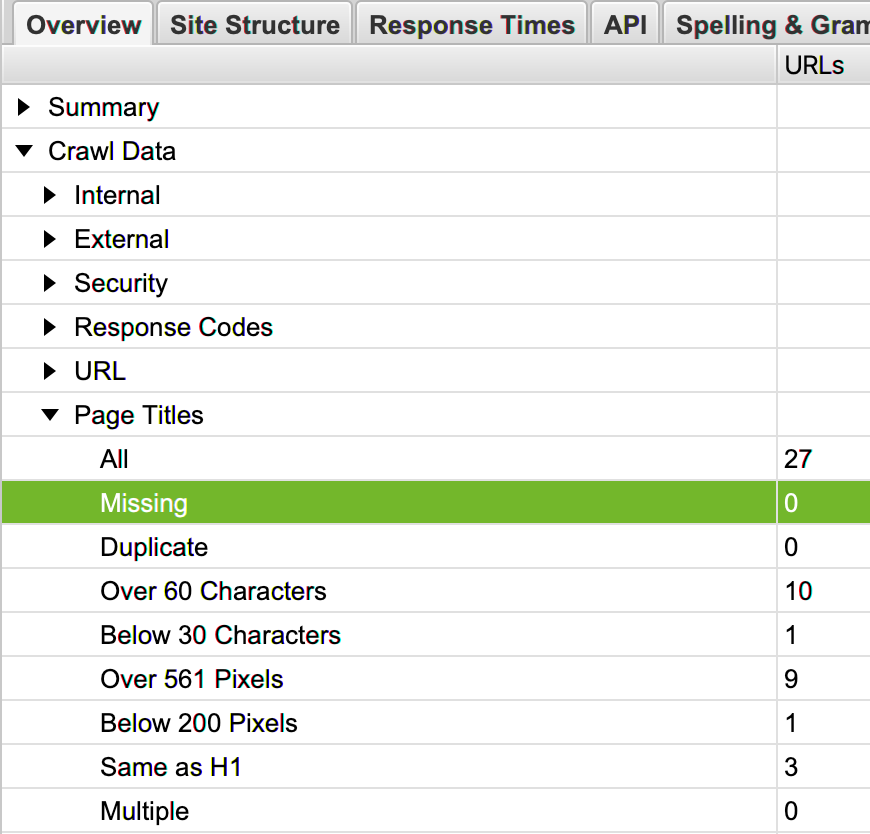
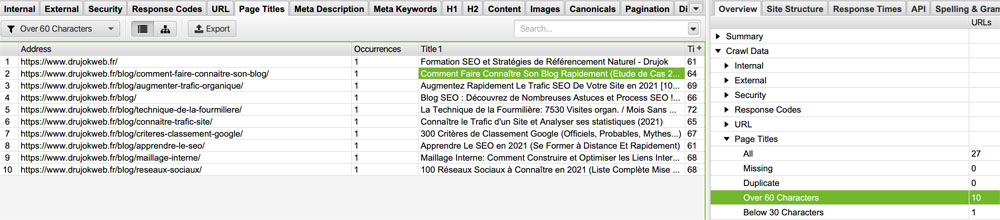
Checkez les lignes « Over 60 Characters » et « Below 30 Characters ».
C’est tout simplement une question d’apparence dans les SERPs.
Si vous avez un doute sur ce que ça donne, allez voir directement sur Google.
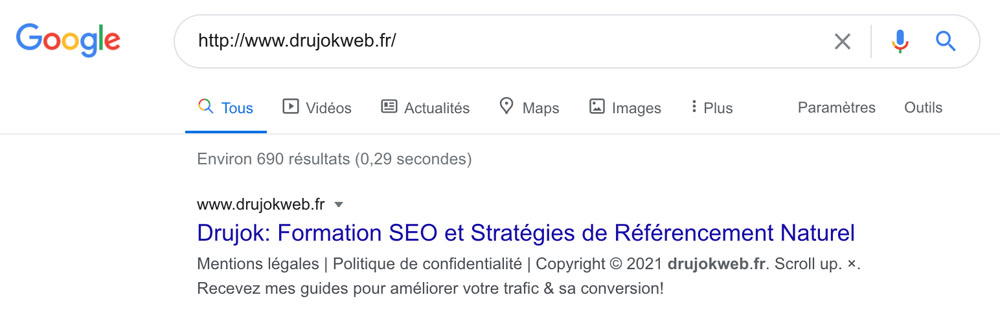
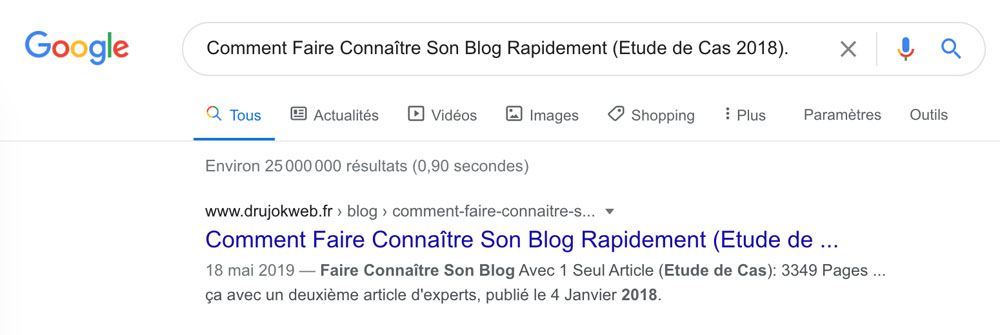
La première, ça va…
La seconde, pas vraiment !
Remontez juste un peu sur la ligne « Duplicate » pour vous assurer que vos Balises titre soient toutes uniques.
Overview > Craw Data > Meta Description > Missing

S’il n’y en n’a pas, Google en générera une automatiquement.
Vous pouvez voir à quoi elle ressemble en la cherchant dans les SERPs :
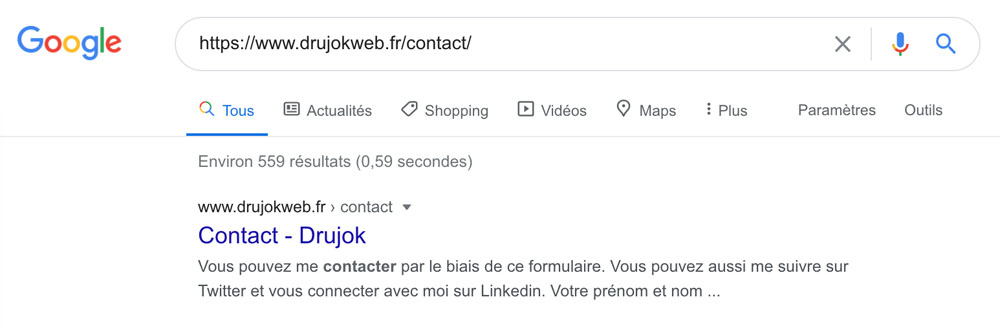
Écrire votre propre meta description, outre l’insertion d’un mot-clé, vous donne la possibilité d’inclure un Call to Action : pensez-y.
Si vous l’avez écrite vous-même, il serait dommage que votre meta description soit coupée ou trop courte (et donc carrément remplacée).

Il vous suffit de cliquer sur la ligne au-dessus de la précédente.
Remarquez une chose : il est mieux de n’avoir pas de meta description personnalisée (et donc une créée par Google), que d’avoir plusieurs fois la même.
Allez dans Overview > Craw Data > H1 > Missing et passez en revue les pages qui n’ont pas de H1.
Toutes vos pages (ou presque) doivent avoir UN en-tête H1 pour donner aux moteurs de recherche des informations indispensables sur le contenu.
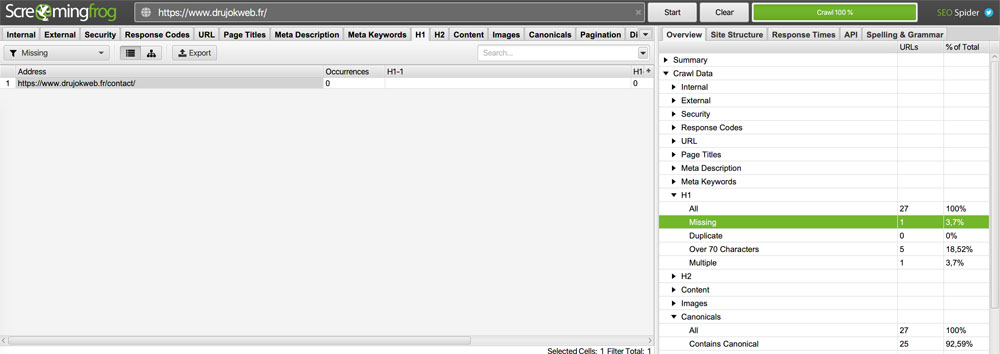
Une seule balise H1 aura un meilleur impact que plusieurs.
Allez dans Overview > Craw Data > H1 > Multiple pour vérifier cela.
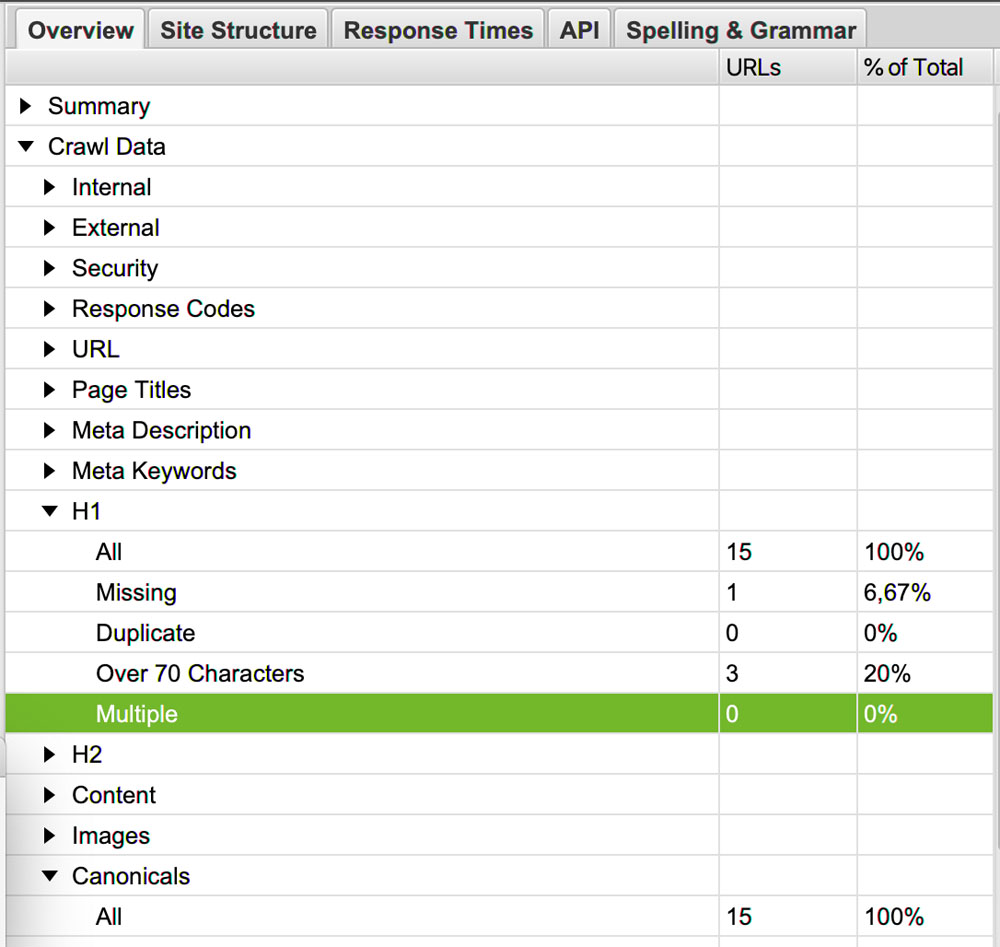
Des balises d’en-tête de plusieurs niveaux amélioreront la clarté de votre contenu pour les moteurs.
Une extension Chrome comme Detailed SEO vous donne un visuel clair sur la structure d’une page individuelle.
Allez dans l’onglet Headings pour avoir cet aperçu.
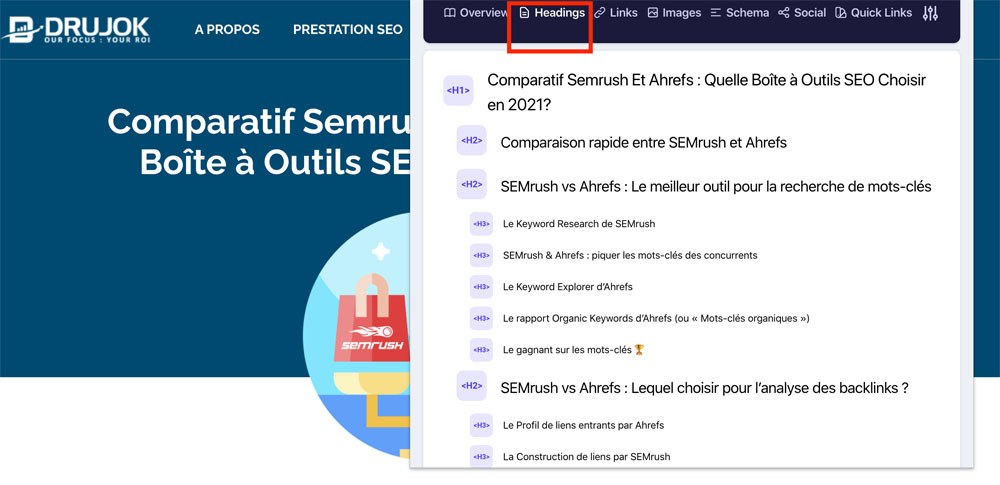
Les headings doivent être utilisés pour ajouter de la clarté,
il est inutile de les utiliser excessivement et de brouiller le message de la page.
La hiérarchie de vos en-têtes doit correspondre à une certaine hiérarchie dans votre contenu.
L’idée c’est que votre propos en général soit bien construit…
Cela impacte votre SEO.
Overview > Crawl Data > Content > Exact Duplicates et Near Duplicates.
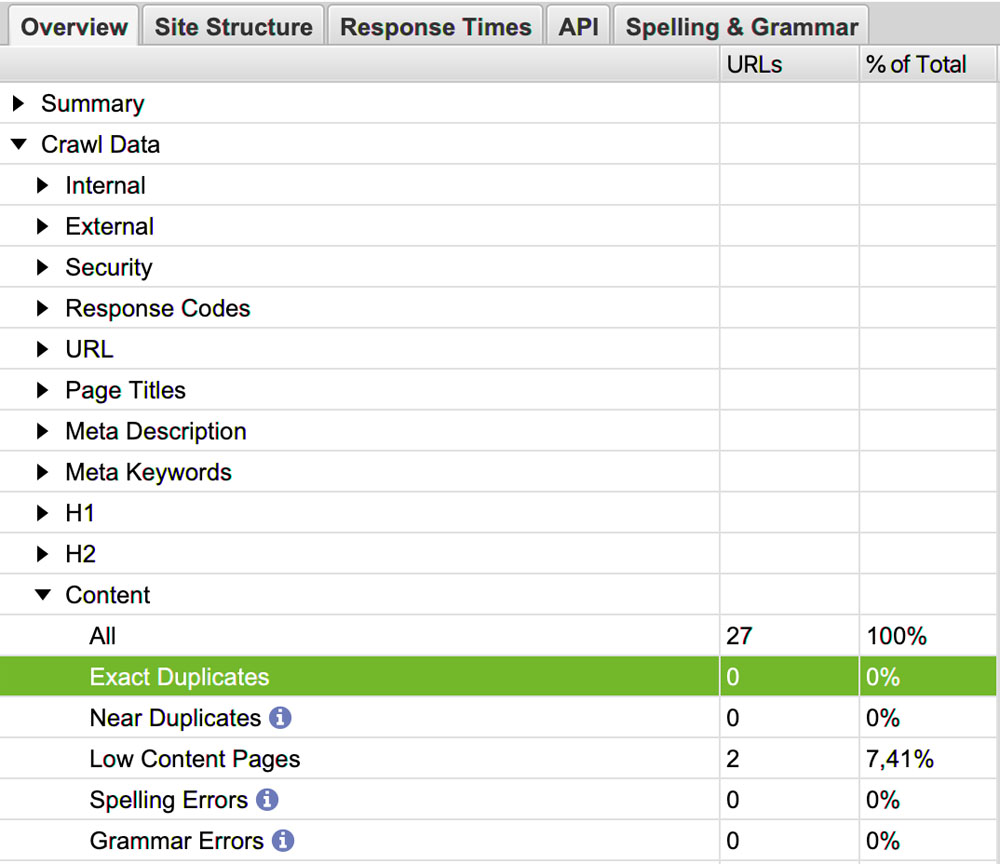
Contenu copié, trop similaire, etc. : votre contenu pauvre ou plagié peut être pénalisé.
Vérifiez son originalité sur la base d’URLs individuelles avec l’outil Copyscape.
Sur la ligne juste en dessous : Low content pages.
La longueur et la richesse du contenu sont, on le sait, un facteur de référencement.
Il va de soi que pour certaines pages comme la page de Contact, il n’y a pas de problème !
C’est votre page la plus importante, elle doit contenir les informations primordiales et être parfaitement structurée.
Revoyez son contenu en direct et profitez-en pour faire marcher l’extension Detailed SEO sur les en-têtes.
Dans votre contenu, il peut être intéressant de mettre certains termes en exergue, en particulier vos mots-clés.
La balise recommandée dans ce cas-là est la balise (plutôt que la balise pour « bold »).
Faites cela par un examen visuel du code sur vos pages les plus importantes.
Les données structurées sont un langage normalisé qui permet d’apporter à Google un éventail d’informations sur certains types de contenus.
C’est un peu une manière de les ranger dans des cases de manière à les mettre en valeur, ou les sortir plus facilement de leurs boîtes.
Dans le SEO Spider, il vous faudra configurer vos données structurées avec la version payante.
Configuration > Spider > Extraction, « Structured Data »
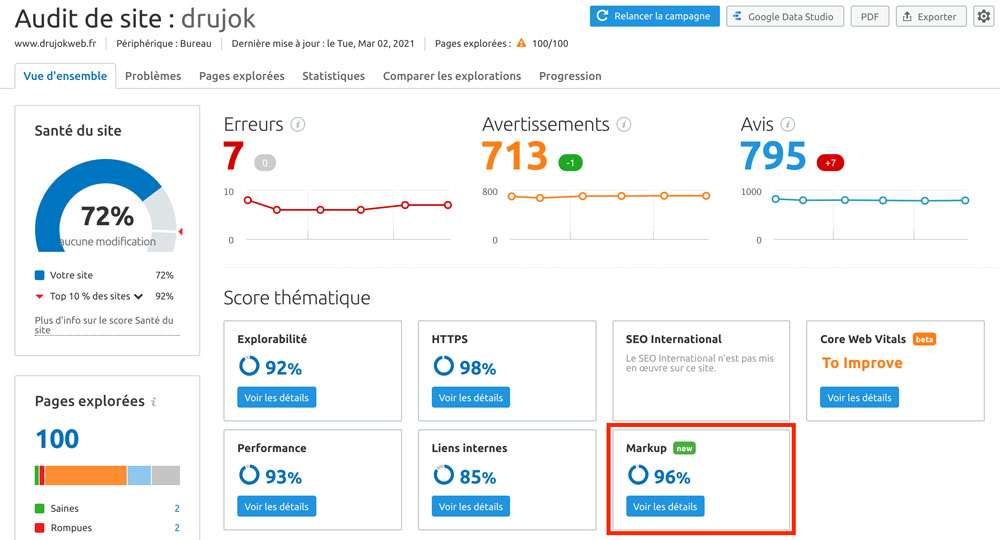
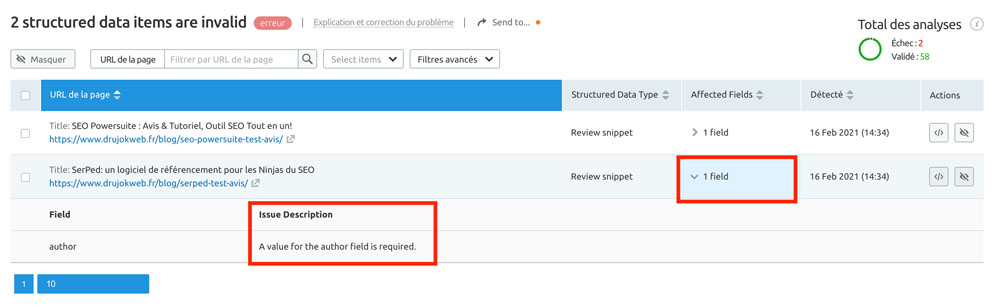
Je fais mon propre audit de données structurées avec SEMrush, en allant dans SEO > On Page et Tech SEO > Audit de Site.
Dans la Vue d’Ensemble, il y a une nouvelle case : Markup, qui correspond au langage Schema Markup.
Sur la page associée je peux voir quelles données structurées j’utilise, sur quelles pages, et voir si certaines sont invalides et donc à corriger.
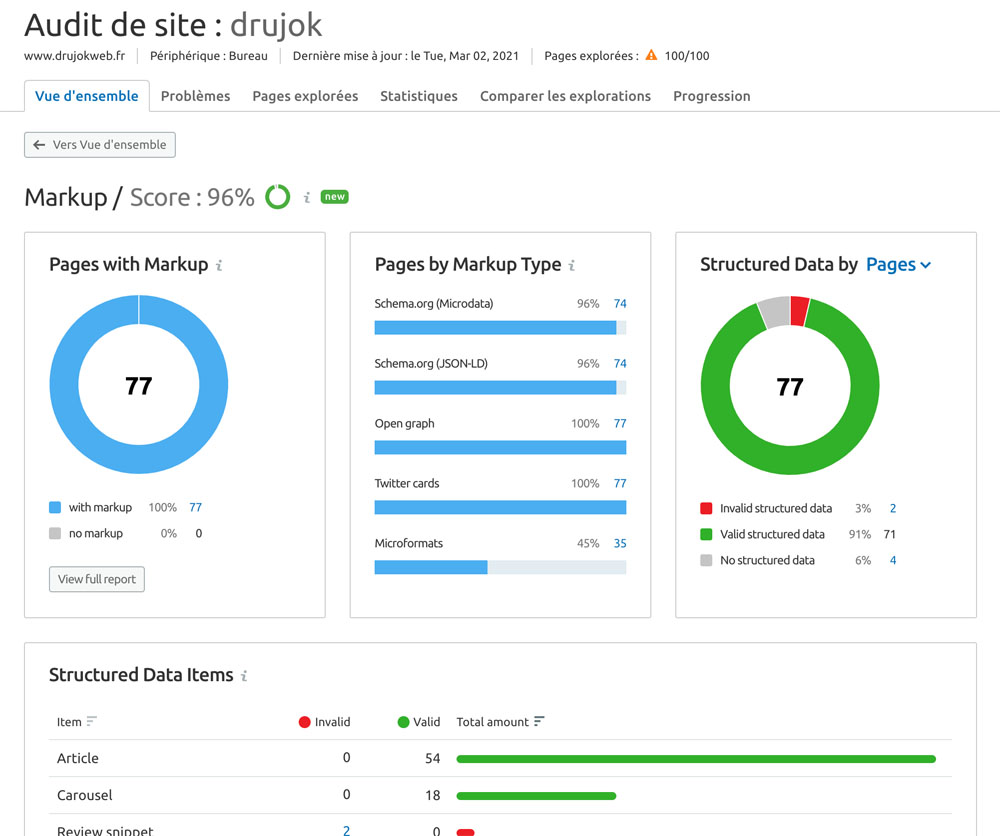
Cliquez sur le bouton « View invalid items » pour ouvrir le rapport sur les données structurées à corriger.
Passez en revue les pages les plus importantes pour voir s’il est possible de leur ajouter certaines données structurées.
Elles pourraient alors apparaître dans différents types de résultats enrichis sur Google.
Pour vérifier rapidement quelles données structurées chacune de ces pages utilise, utilisez l’onglet « Schema » de l’extension Detailed SEO.
Si vous utilisez WordPress, vous pouvez apprendre à utiliser RankMath pour mettre en place différents Rich Snippets en commençant par l’étape 15 de ma checklist sur le SEO dans WordPress.
Screaming Frog sera encore votre allié du côté des images.
Rendez-vous dans Overview > Craw Data > Images.
Une image intégrée avec CSS ne sera pas traitée comme du contenu par Google.
Ces dernières font partie du style, de la mise en page du site mais ne représentent pas du contenu à proprement parler.
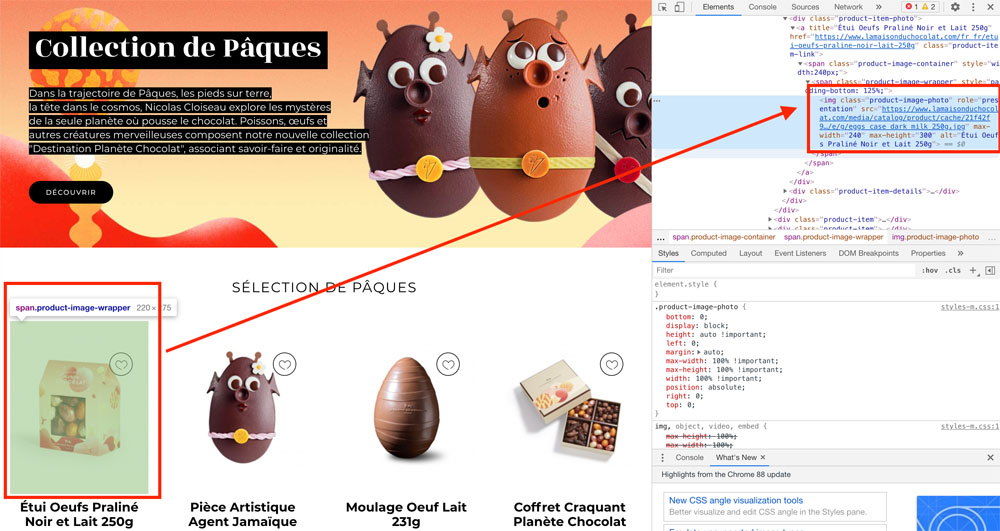
Pour vérifier comment une image est intégrée, faites un clic droit dessus et cliquez sur « Inspecter ».
Elle doit contenir la balise <img> et idéalement une balise <alt>.
Le mieux est que les attributs alt des images soient uniques et représentatifs.
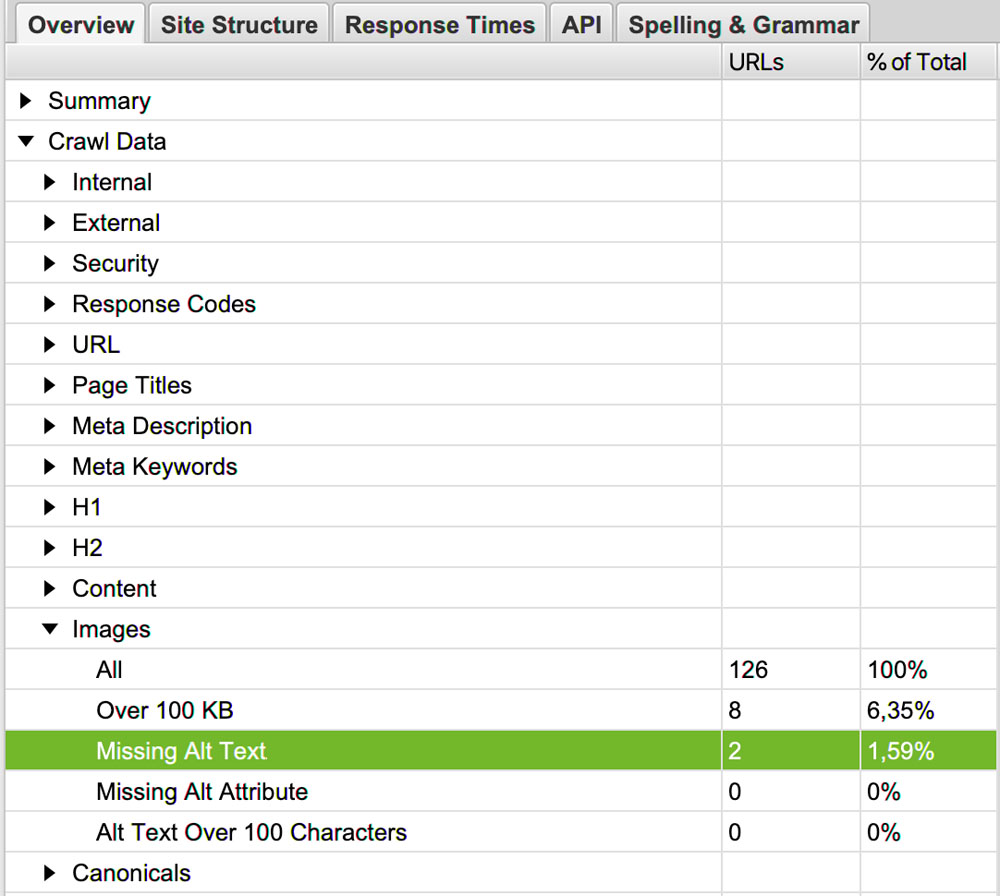
Pour trouver les attributs alt manquants, rendez-vous dans Overview > Craw Data > Images > Missing alt text.
Théoriquement, alt text et alt attribute sont la même chose mais ici missing alt text inclut les images qui ont un alt attribute mais où celui-ci est vide de texte.
Un peu comme cela : <img src= »screamingfrog-logo.jpg » alt= » » />
Cliquez ensuite sur chaque image dans la liste à gauche pour voir sur quelle page elle apparaît et y modifier l’attribut alternatif.
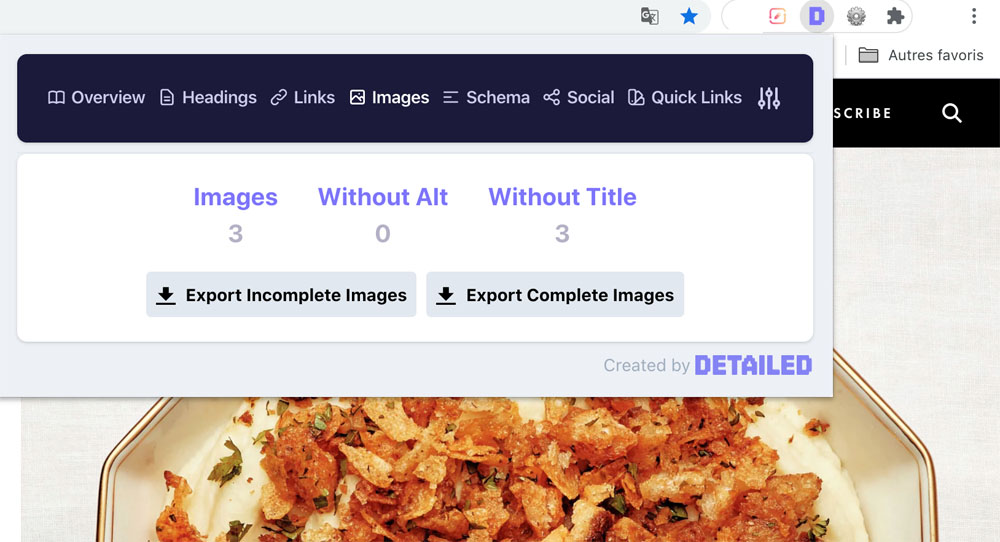
(Si vous voulez vérifier la présence d’attributs alt sur une seule page, vous pouvez aussi utiliser Detailed SEO).
Ce n’est pas aussi important que les attributs alternatifs, mais indiquer de quoi « parle » l’image reste un point positif si on ne fait pas de bourrage de mot-clé.
Vous trouverez ces noms de fichiers directement à la fin de l’adresse URL de vos images.

Comme GTMetrix, PageSpeed Insights peut vous donner des conseils sur la compression de certaines images qui ralentissent le chargement de vos pages.
Sur WordPress, certains plugins comme Smush peuvent vous aider à optimiser de multiples images à la fois.
Cette section ne s’applique que si votre site s’adresse à plusieurs pays ou plusieurs langues (multirégional et / ou multilingue).
Le ccTLD (country code Top Level Domain) est un gage de confiance pour l’internaute qui comprend que le site est géré depuis son pays d’origine.
C’est donc une option intéressante si tous les noms de domaine avec les ccTLDs des pays que l’on vise sont disponibles.
Le ciblage international est un ancien rapport qui n’a pas été adapté pour la nouvelle version de la console mais est toujours accessible et fonctionnel sous son ancienne version.
Il faut donc se rendre dans Anciens outils et rapports et Ciblage International.
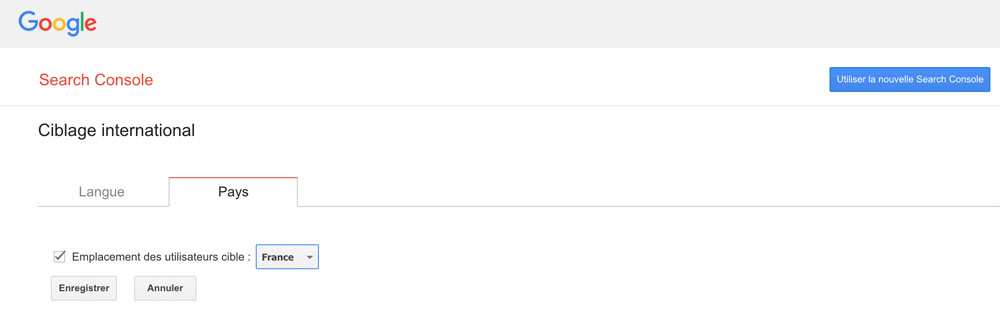
Une nouvelle page s’ouvre et dans l’onglet Pays, on peut choisir le pays cible.
Si les langages ne sont pas délimités clairement, il peut rapidement y avoir un problème d’indexation.
Par exemple, il est possible qu’une seule version de page soit indexée (alors qu’il en existe une pour chaque langue)…
et que d’autres pages ne soient indexées que dans une autre langue.
Pour éviter cela, il est préférable que chaque version ait son propre répertoire (de type .com/fr), ou même son sous-domaine.
L’idéal également c’est d’avoir un menu déroulant ou un bouton rendant chaque autre langue / répertoire / sous-domaine accessible.
Enfin, utilisez des balises hreflang.
D’une part, les balises hreflang servent à Google à trouver les différentes versions d’une page.
D’autre part, elles peuvent aussi servir à écarter tout soupçon de contenu dupliqué pour des pages quasi identiques qui sont dans la même langue mais destinées à une région différente.
Accédez à vos balises hreflang dans Overview > Crawl Data > Hreflang > Contain hreflang.
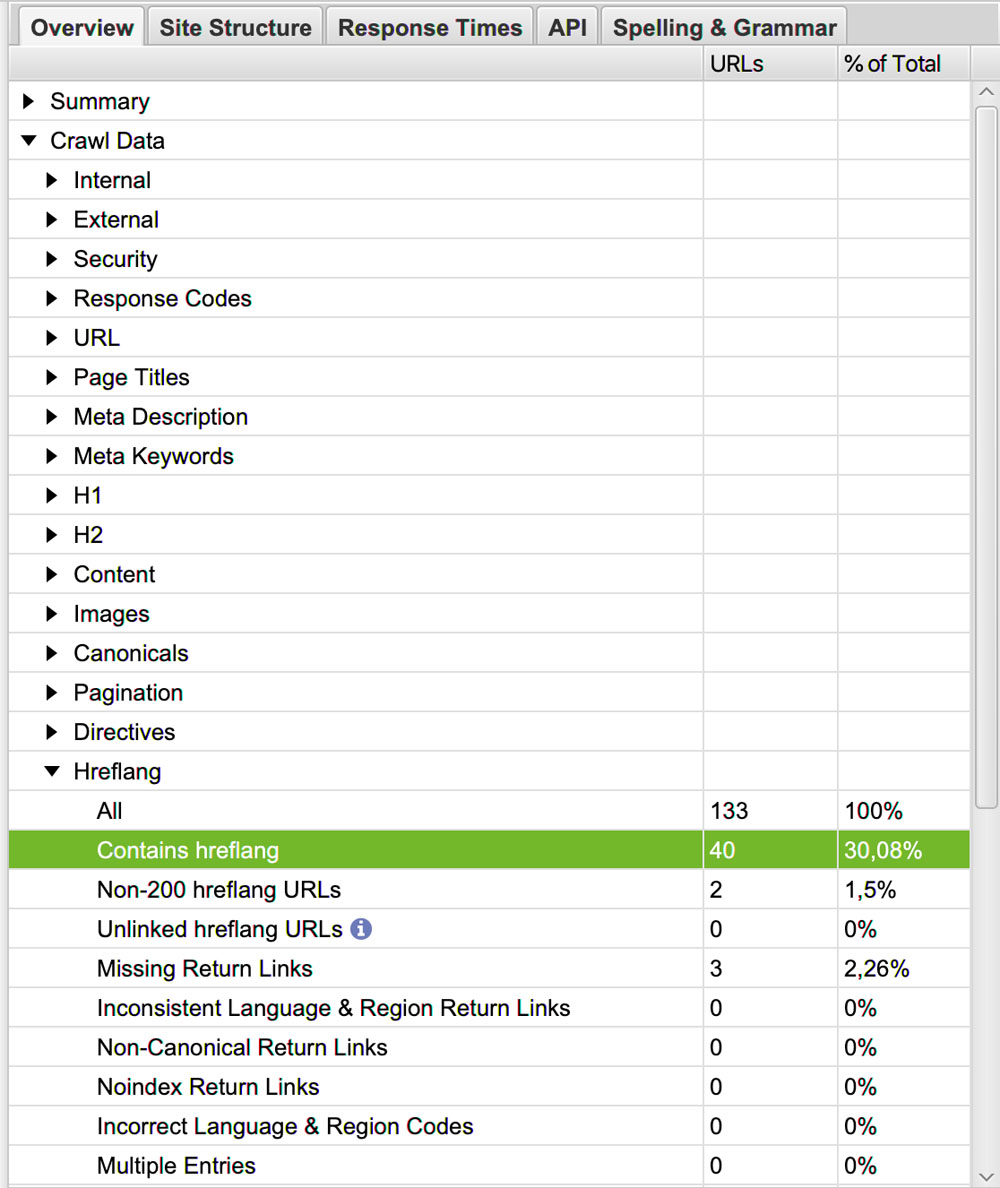
Restez dans la section All pour voir également les pages qui n’en n’ont pas mais qui pourraient en avoir.
Dans la section Contain hreflang de Screaming Frog, passez en revue chaque page pour voir quelles URLs lui sont associées.
Pour chaque page (chaque ligne), vous devez faire défiler la section vers la droite et inspecter chaque colonne « HTML hreflang 2 URL » etc., pour voir quelles URLs sont associées dans les autres langues.
Les liens retour hreflang manquants se trouvent dans la section Missing Return Links.
Cette section détecte les pages vers lesquelles il existe des balises hreflang type
el-alternate-hreflang mais qui n’en n’ont pas en retour.
Elles doivent en posséder pour que toutes ces valeurs se confirment les unes les autres.
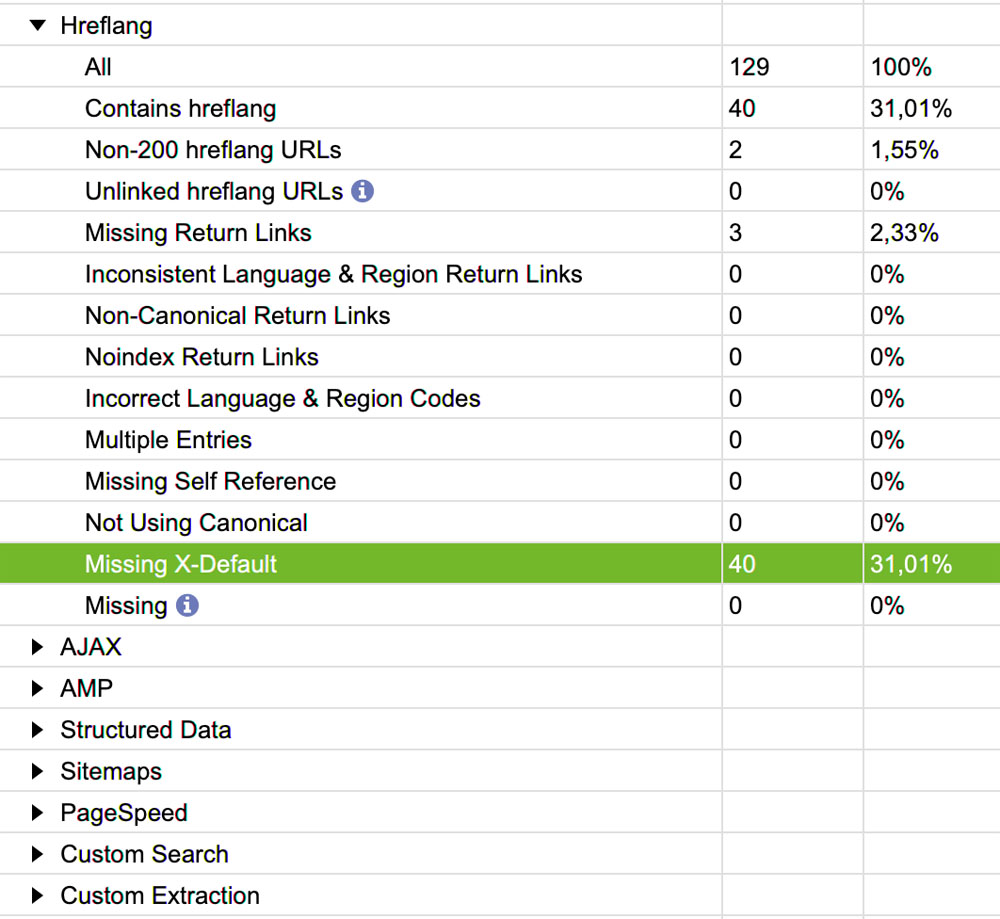
L’attribut X-Default indique quelles pages du site sont considérées comme les pages « par défaut », ne ciblant aucune région en particulier.
Il doit donc être utilisé sur des sites internationaux, qui ont effectivement un chemin « par défaut » et non une offre différente pour chaque région.
Toutes les pages qui ont des balises hreflang sans balise x-default sont indiquées dans la section Missing X-Default.
Pour vendre vos produits dans plusieurs devises, vous pouvez mettre en place une configuration multi-boutiques ou choisir un simple affichage dans la devise locale correspondant au taux de conversion actuel.
Trop de liens sur la page d’accueil pourrait être le signe de quelque chose de louche.
Si vous en avez 100 ou plus, vous devriez commencer à vous poser des questions.
Allez voir dans Overview > Crawl Data > Internal > HTML, et cliquez sur le lien de la page d’accueil qui a priori devrait être le premier de la liste.
Regardez ses Outlinks (menu inférieur), et le chiffre sous le tableau.
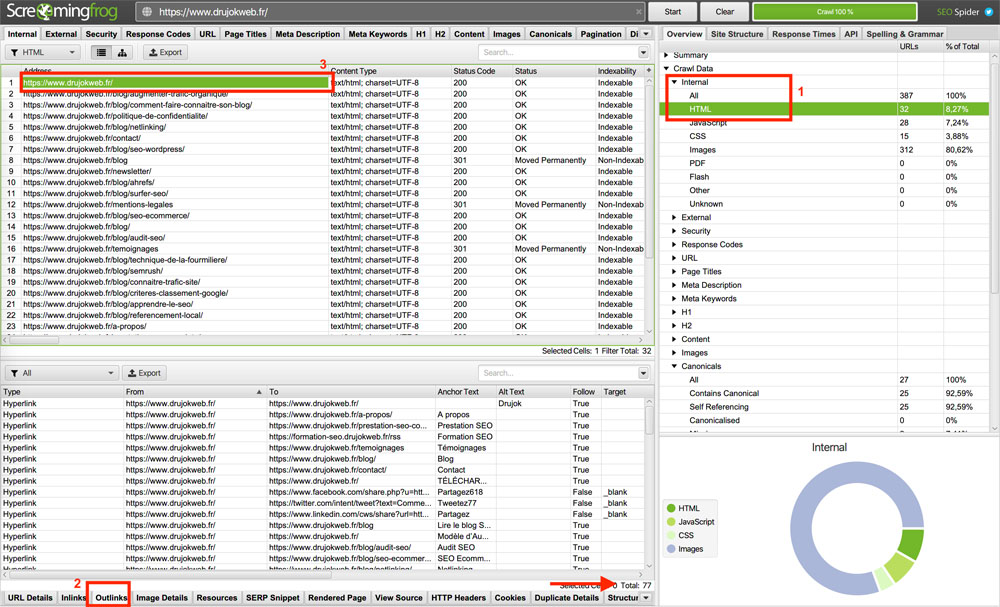
Toutes les pages devraient avoir un lien vers la page d’accueil.
La plupart du temps, il se situe sur le logo du site et / ou sur un bouton « Accueil » du menu supérieur.
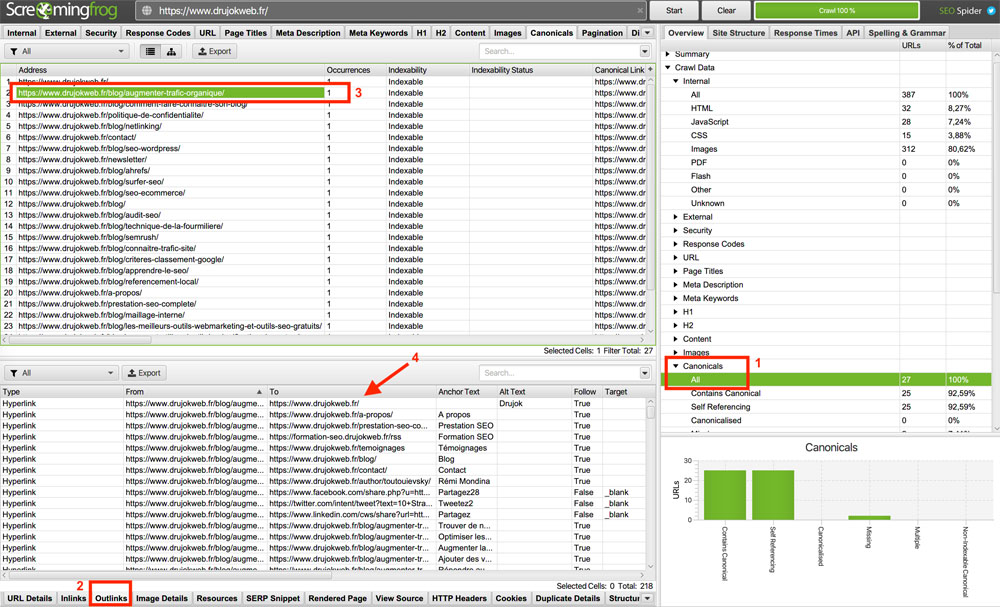
Pour confirmer la présence de ce lien, allez dans Overview > Crawl Data > Canonicals > All.
Sélectionnez les URLs une par une (en les faisant défiler) et regardez leurs Outlinks (menu inférieur).
Le premier Outlink devrait toujours être un lien vers la page d’accueil.
Des liens vers des ressources inaccessibles sont synonymes de mauvaise expérience utilisateur.
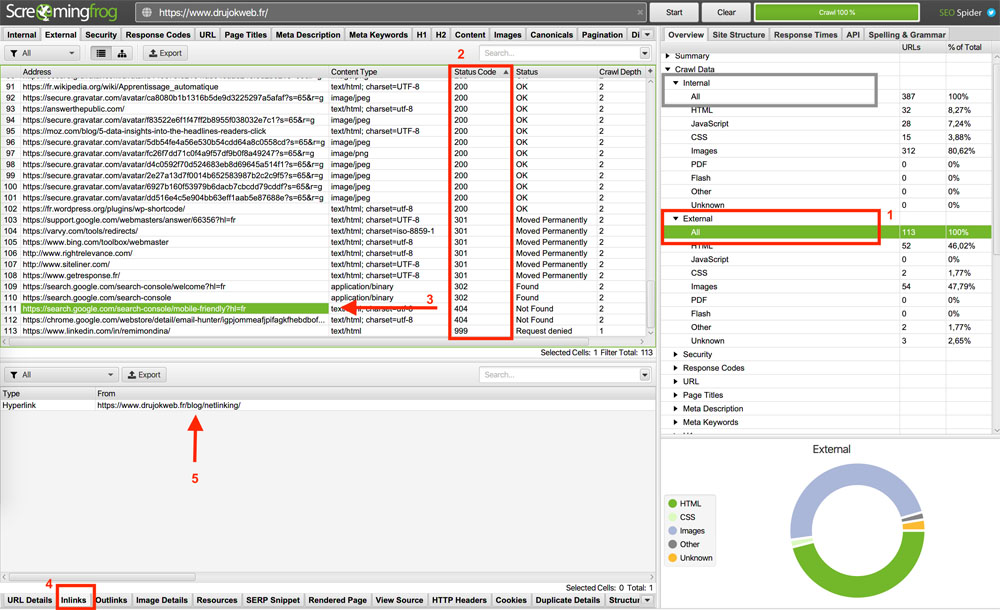
Pour trouver ces liens « cassés », inspectez tous les liens à la fois dans Overview > Internal et External.
Organisez les listes qui s’affichent par « Status Code » pour regrouper les liens au code de statut problématique, comme 401, 403, 404 et même 999.
Vous trouverez ensuite la ou les pages où sont placés ces liens en cliquant sur l’onglet Inlinks dans le menu inférieur.
Un bon moyen de ne pas laisser les liens cassés s’installer trop longtemps :
(et si vous avez WordPress)
Utilisez le plugin Broken Link Checker.
Celui-ci crawle régulièrement votre contenu à la recherche de liens internes et externes cassés.
Et quand il en trouve, il vous envoie une notification.
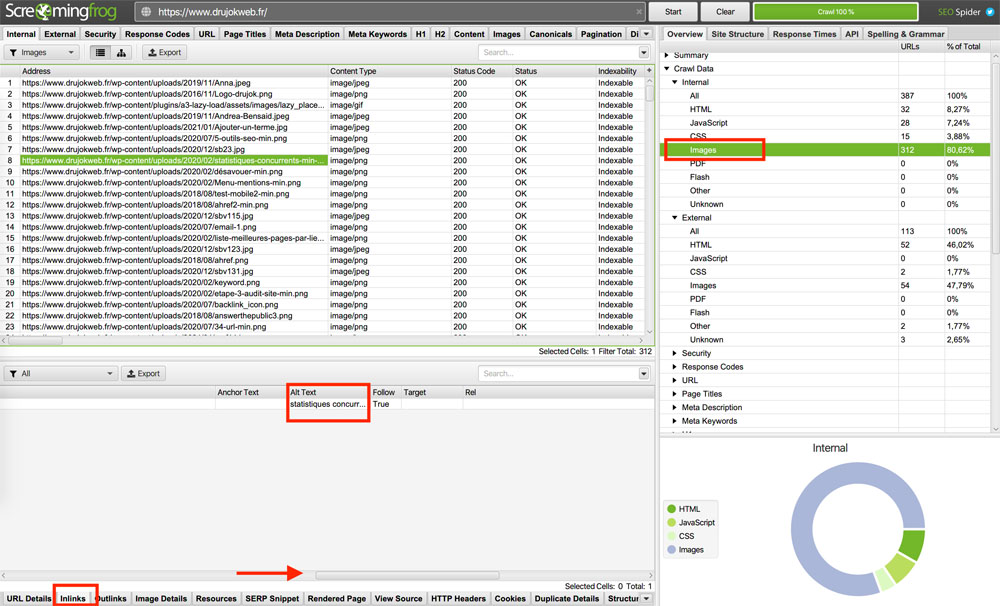
Si certains de vos liens sont sous forme d’image, il serait particulièrement dommage en SEO que cette image n’ait pas de texte alternatif.
Pour inspecter ces textes alternatifs et voir s’il serait cohérent d’en ajouter là où il n’y en a pas,
rendez-vous dans Overview > Internal puis External et > Images.
Ensuite, dans le menu inférieur Inlinks faites défiler la barre de fenêtre vers la droite pour trouver les textes alternatifs.
Vous avez accès à une fonction basique d’audit des backlinks dès la version freemium de SEMrush.
Dans SEO > Construction de liens > Analyse de backlinks, allez sur l’onglet « Backlinks »,
et sélectionnez le filtre « NoFollow ».
Vous pourrez ainsi inspecter les liens qui sont marqués de cet attribut pour éventuellement « réclamer » un DoFollow auprès des sites qui pointent vers vous.
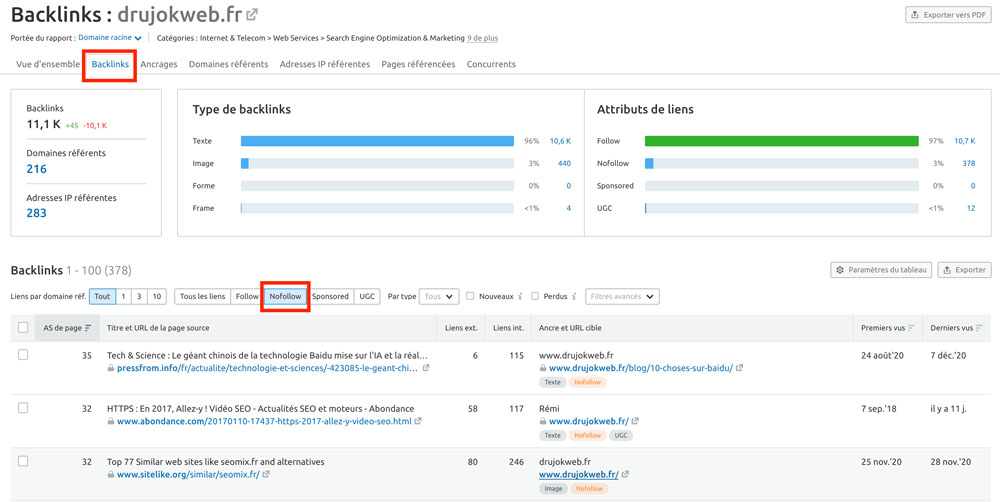
Pics soudains, pertes brutales… toute évolution non naturelle devrait éveiller votre attention.
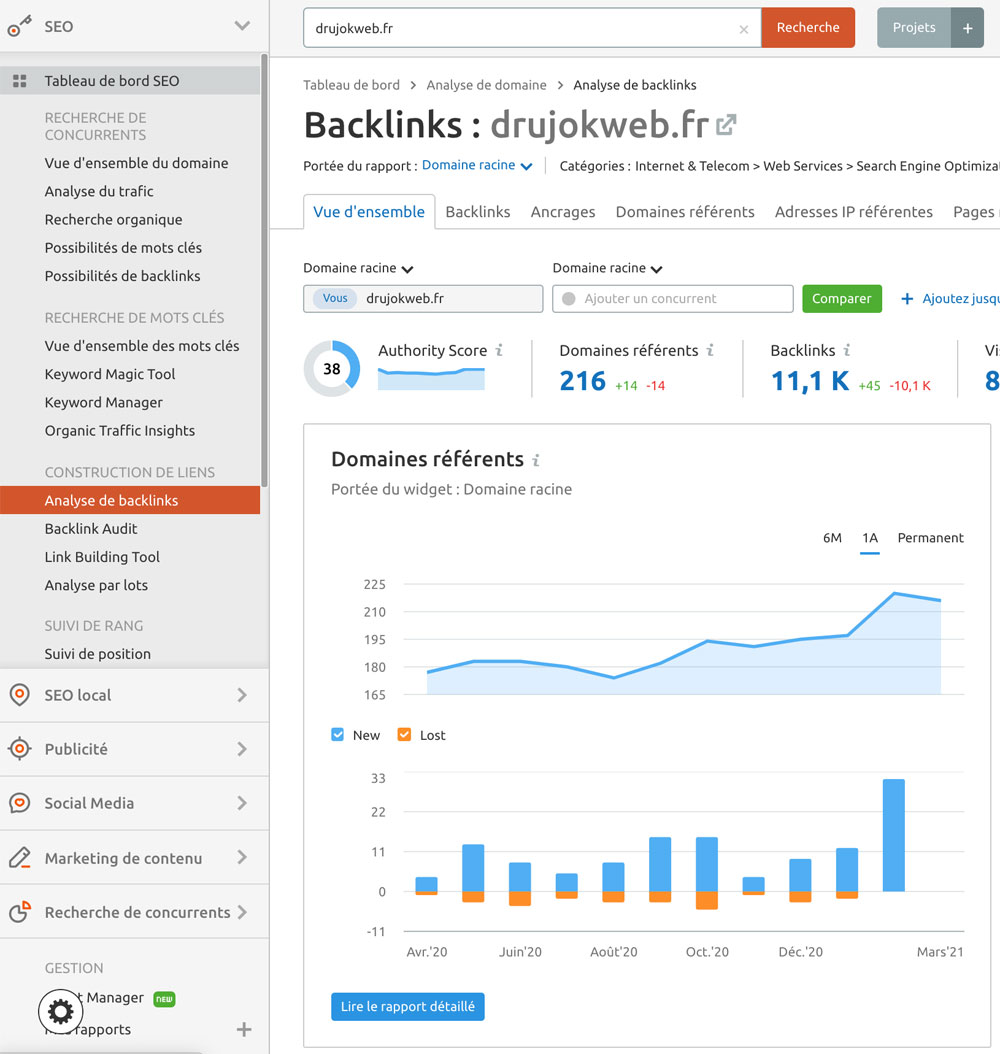
Restons sur SEMrush (et la possibilité d’utiliser sa version freemium) pour une analyse rapide des mouvements de backlinks.
SEO > Construction de liens > Analyse de backlinks, graph des Domaines référents.
L’outil de désaveu des liens toxiques est séparé des autres outils d’analyse car il doit être utilisé avec prudence.
Vous pouvez le trouver en le googlant ou directement via ce lien.
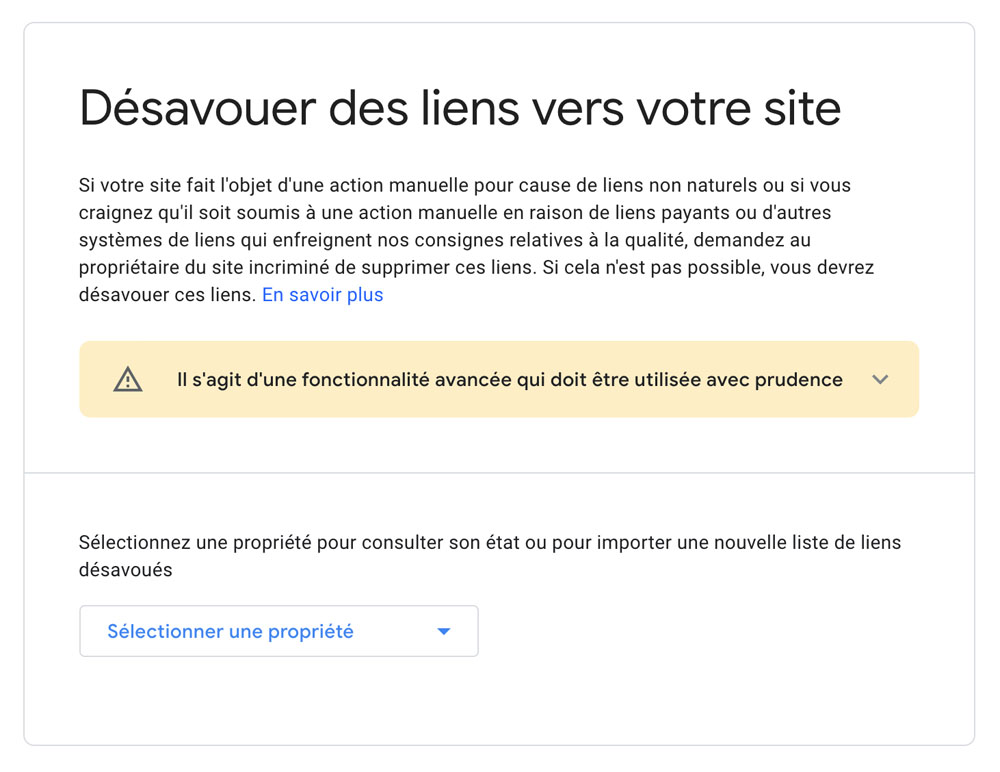
Inspectez les liens qui y sont soumis, s’il y en a.
Vous devriez l’avoir déjà utilisée pour votre audit.
Mais si ce n’est pas fait, il y a urgence !
Sélectionnez la période sur les 12 derniers mois.
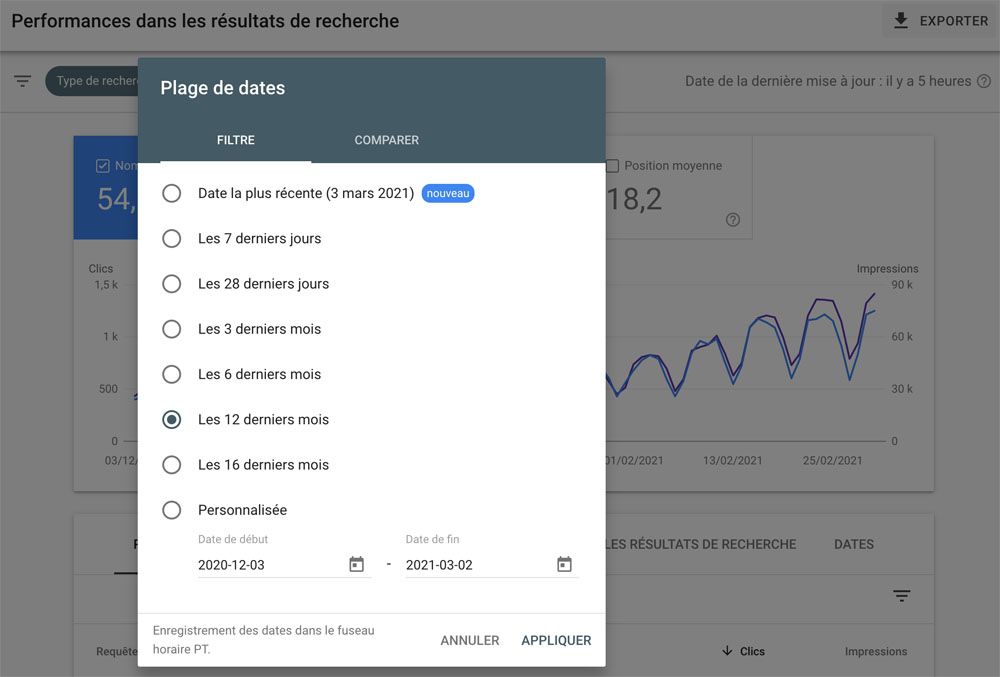
Et prenez note des différentes métriques et de leur évolution :
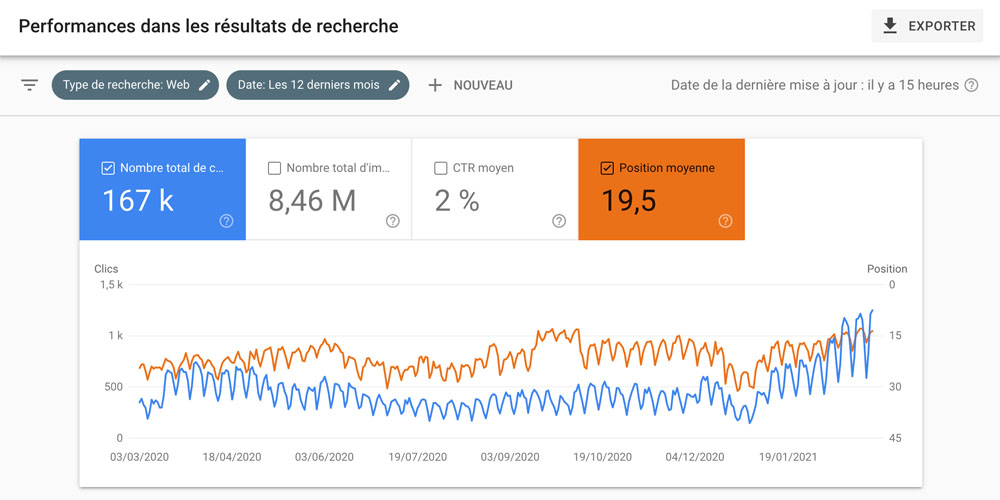
Ce rapport important vous montrera :
Pendant que vous êtes dans le rapport, vérifiez que le robot d’exploration principal soit conforme au Mobile First Indexing qui rentre en vigueur cette année.
Le robot doit donc être le Googlebot pour Smartphone.

Rendez-vous dans le menu inférieur pour savoir si quelqu’un a demandé la suppression d’un contenu de votre site.
Il se trouve juste en dessous du menu Sitemaps.
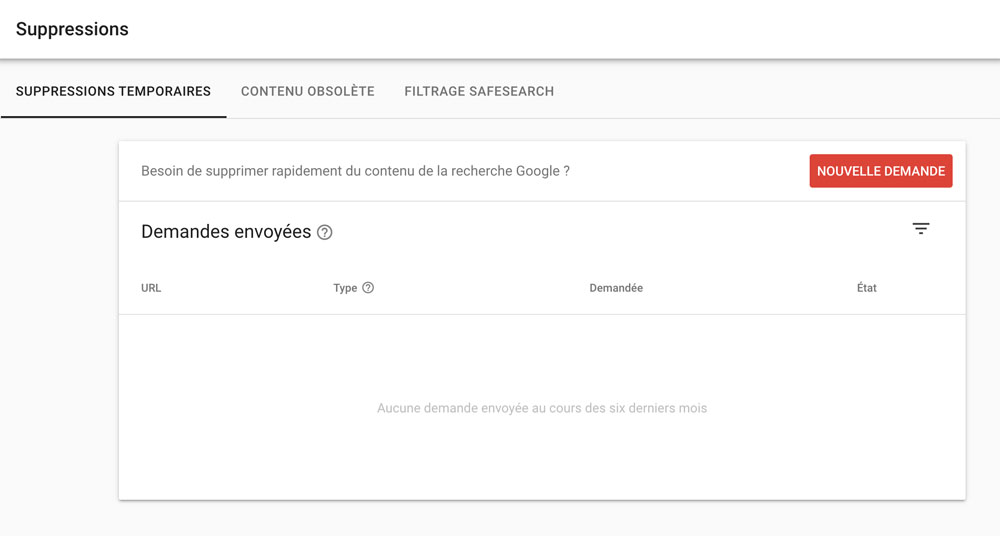
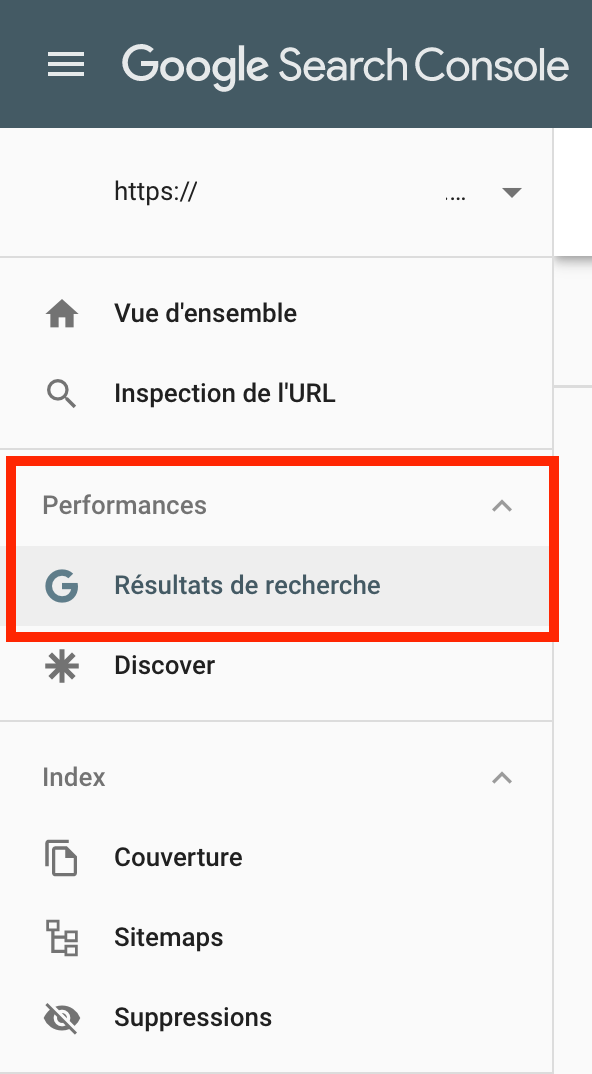
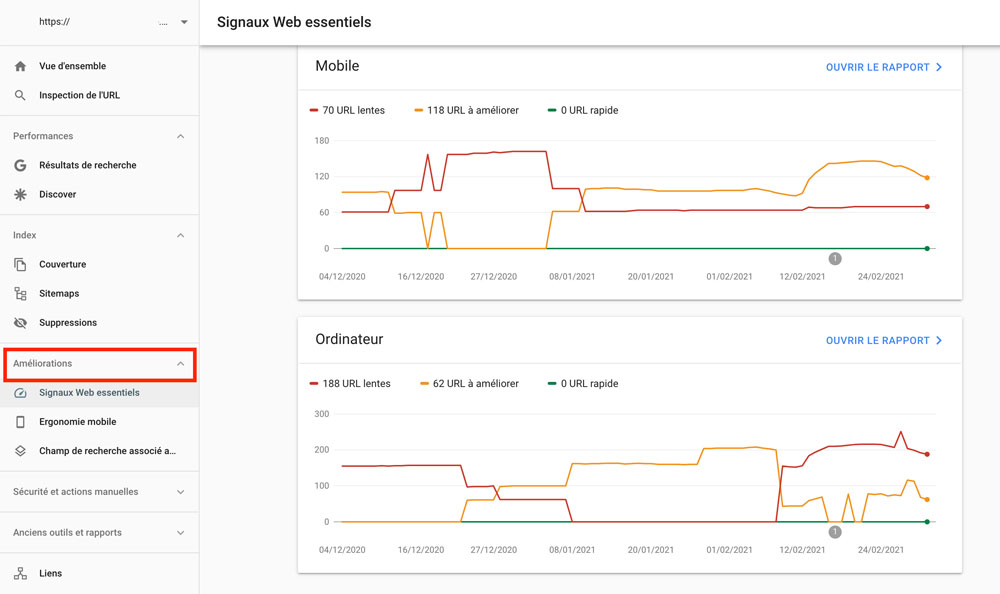
Vous pouvez vous contenter de jeter un coup d’œil, puisque vous examinerez notamment les signaux web essentiels (Core Web Vitals) plus tard dans cet audit.
Pour vérifier qu’un agent de Google n’ait pas exercé de pénalité sur votre site,
Allez dans Sécurité et actions manuelles > Actions manuelles.
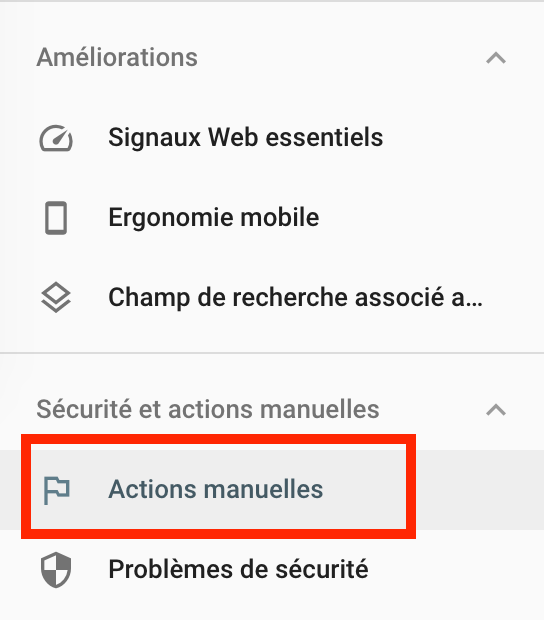

Ces actions manuelles se font plus rares mais existent encore.
À surveiller donc.
S’il existe une pénalité, dans ce cas, il faut :
Il s’agit juste d’une vérification rapide.
Cela se fait dans le menu Anciens outils et rapports > Liens.
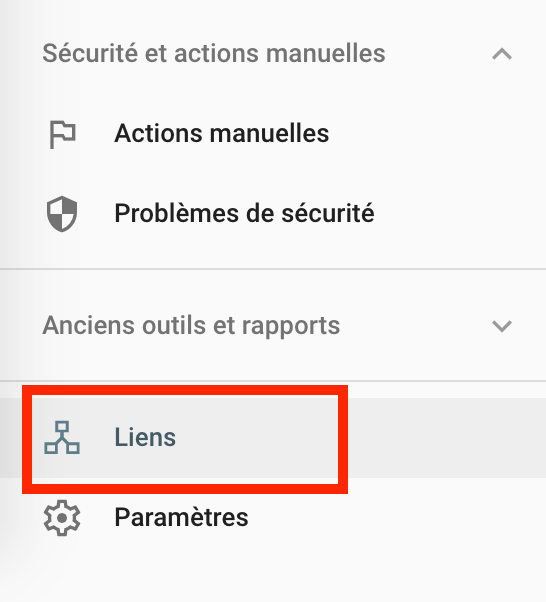
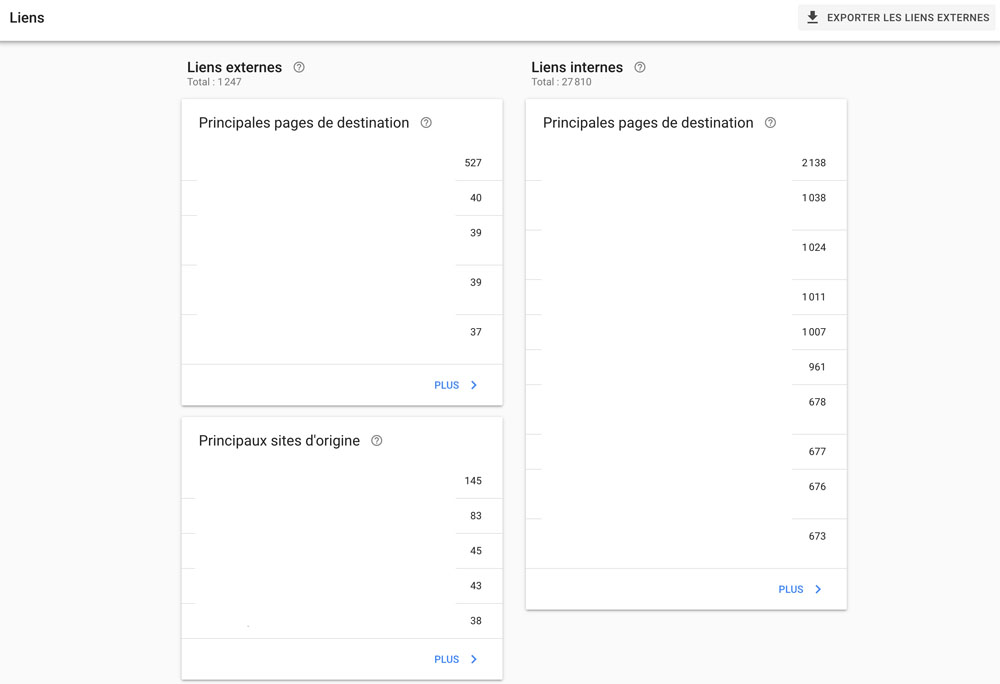
Ce rapport est disponible dans les Paramètres > Statistiques sur l’exploration
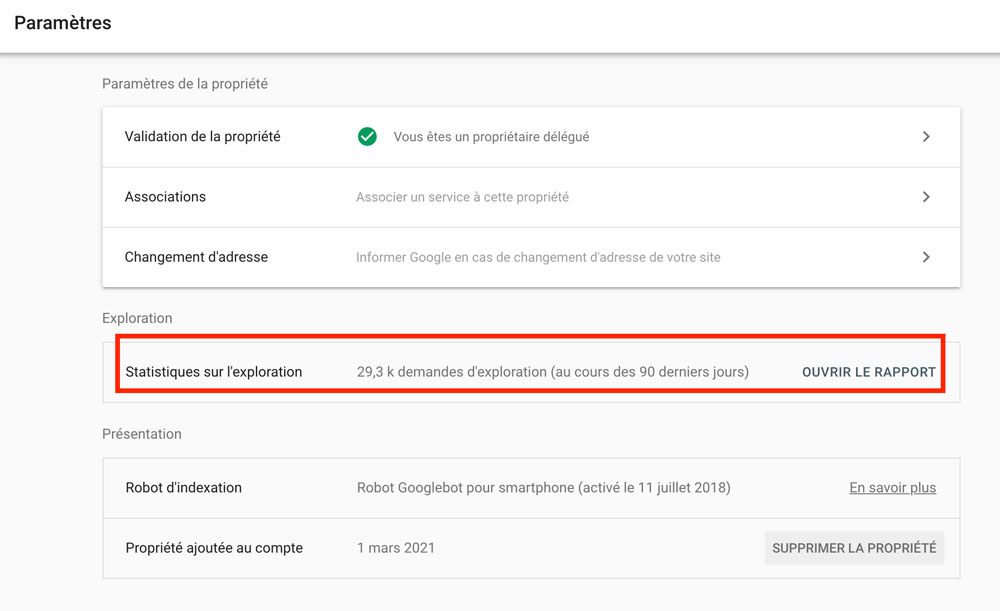
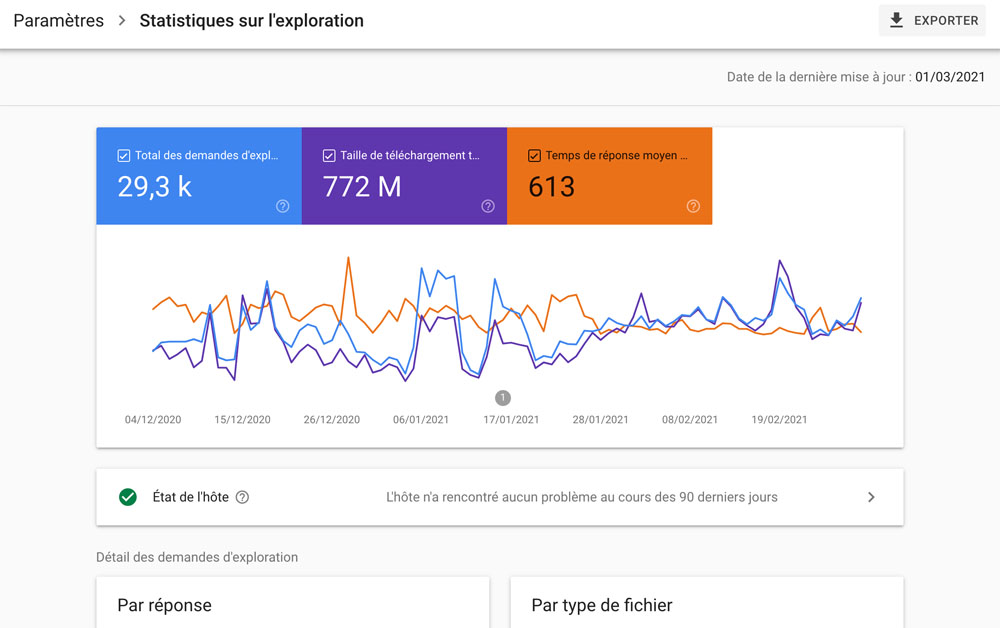
Il vous donne un aperçu de la manière dont Google explore le site.
Vous aurez des informations sur la santé de vos hôtes, sur les ressources que Google explore le plus, sur les codes renvoyés par le serveur, etc.
L’association des deux comptes se fait à partir de la Search Console, dans les Paramètres.
Cliquez sur Associations.
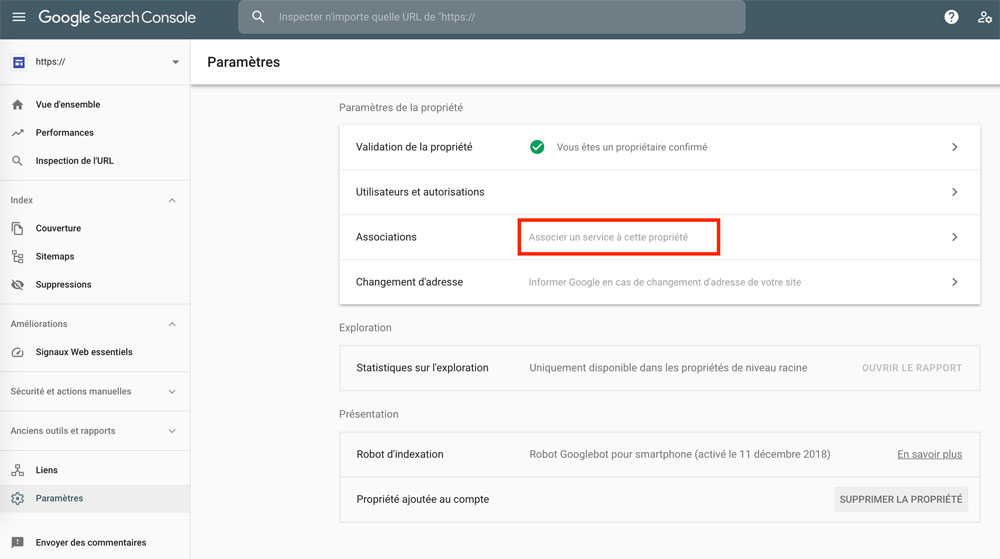
Puis associez la ou une des propriétés liée(s) au compte Google.

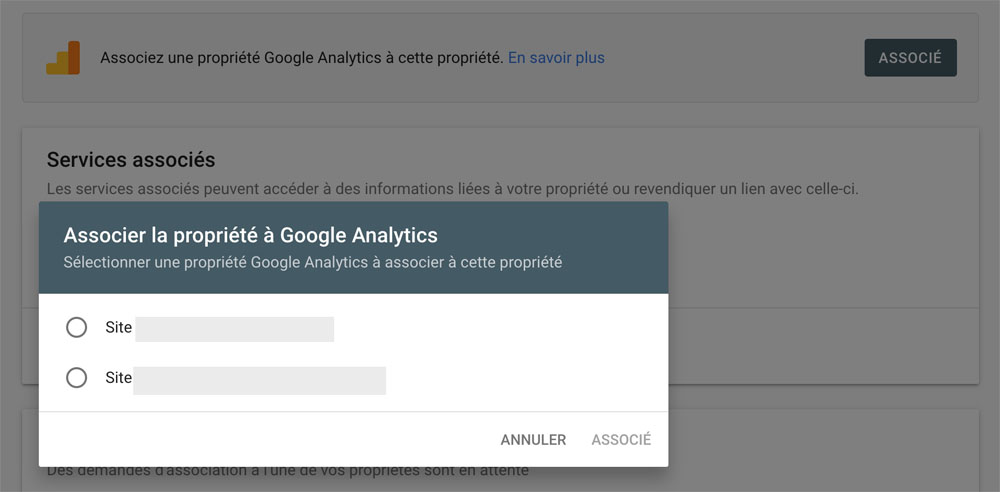
Pour une analyse plus précise, vos données de trafic et d’utilisateurs seront liées aux performances techniques et à tout ce qui concerne l’indexation de votre site.
JavaScript est un langage soumis aux erreurs syntaxiques (erreurs dues au développeur) et aux bugs (erreurs dues au serveur, au navigateur…).
À une époque le trafic généré par les robots (qui est énorme) n’apparaissait pas dans les statistiques Analytics, car ceux-ci ne généraient pas de JavaScript.
Le filtrage des robots d’indexation est toujours automatique, mais malheureusement le trafic lié à d’autres robots moins désirables peut apparaître.
Pour éliminer ces derniers de vos données (et ne pas les prendre pour des humains générant de vraies décisions marketing), rendez-vous dans :
Aministration > Vue >
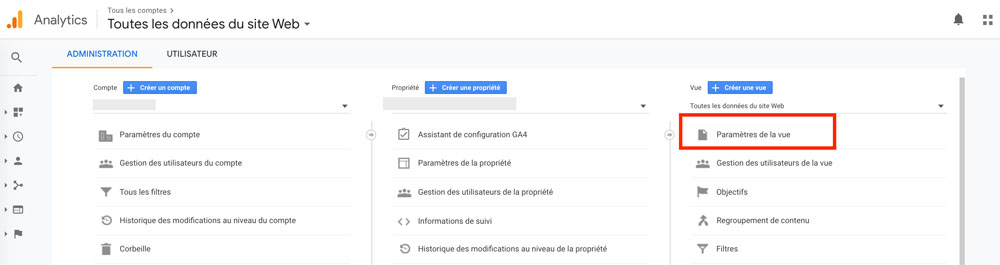
Paramètres de la vue
Puis cochez la case « Exclure tous les appels provenants de robots connus ».
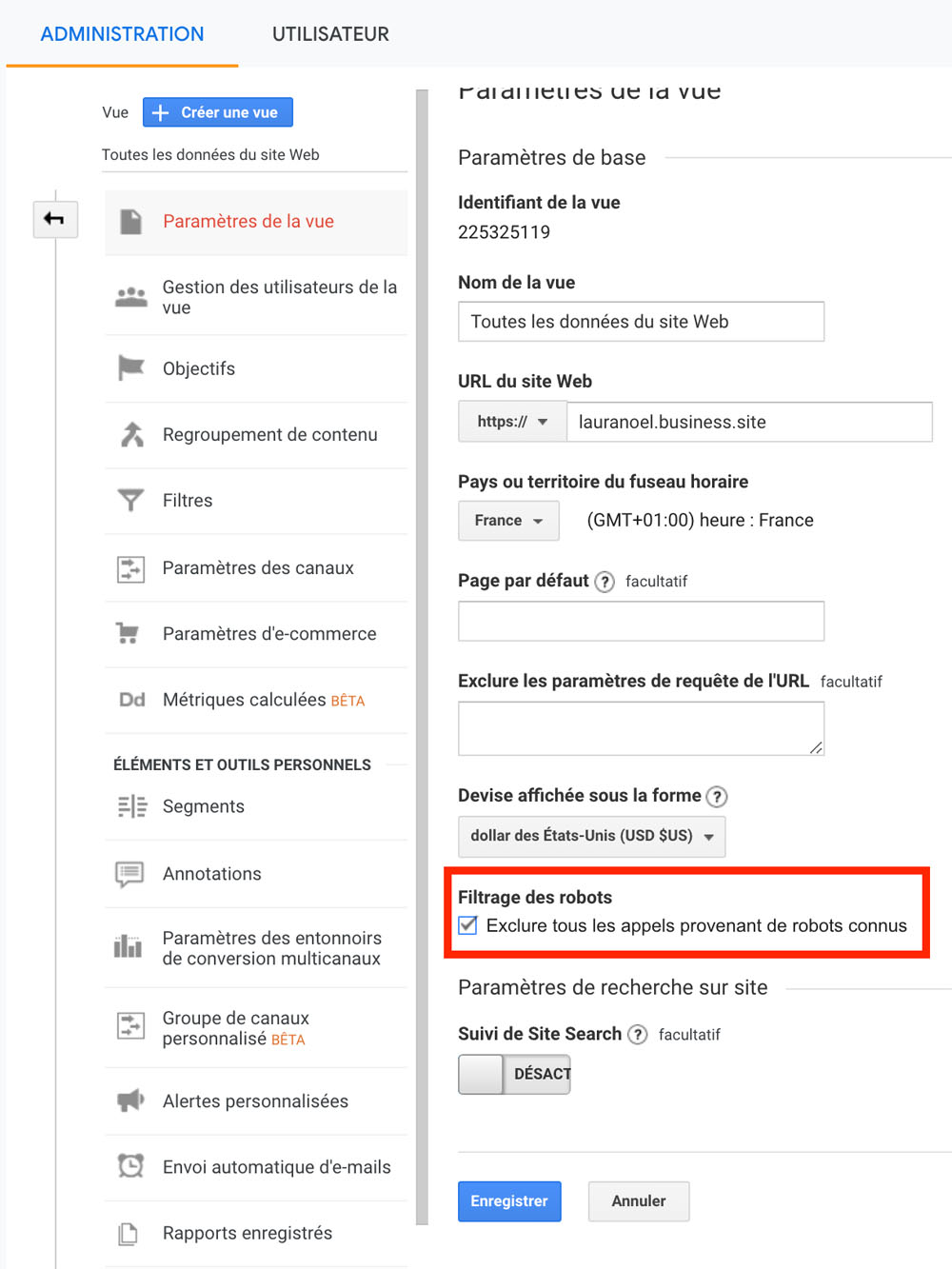
Pour d’autres robots inconnus (et encore moins bienveillants), il faudra apprendre à les repérer et mettre en place des filtres plus avancés.
Avec le suivi ecommerce, vous pouvez suivre des données concernant les ventes, les commandes, leur montant moyen, la localisation des facturations, etc.
Ces données sont corrélées avec celles de l’utilisation générale du site pour analyser les performances de vos landing pages, de vos campagnes marketing…
La mise en place de ce tracking peut être un peu fastidieuse et nécessiter l’action d’un développeur.
Toutefois il existe quelques tutoriels en ligne (souvent adaptés aux différentes plateformes ecommerces).
Il vous faudra entre autres :
La plupart de vos visiteurs devraient arriver sur votre site à travers votre nom de domaine, sous-domaine, etc.
D’autres noms d’hôtes signifient qu’il ne s’agit pas de véritables utilisateurs mais de services extérieurs (comme des caches, Google translate…).
Vous devrez donc filtrer ces hôtes au moins pour la vue affinée destinée à analyser votre audience – la vraie.
Regarez donc s’il existe des noms d’hôte étranges.
Audience > Technologie > Réseau, filtre « Nom d’hôte » dans le tableau.
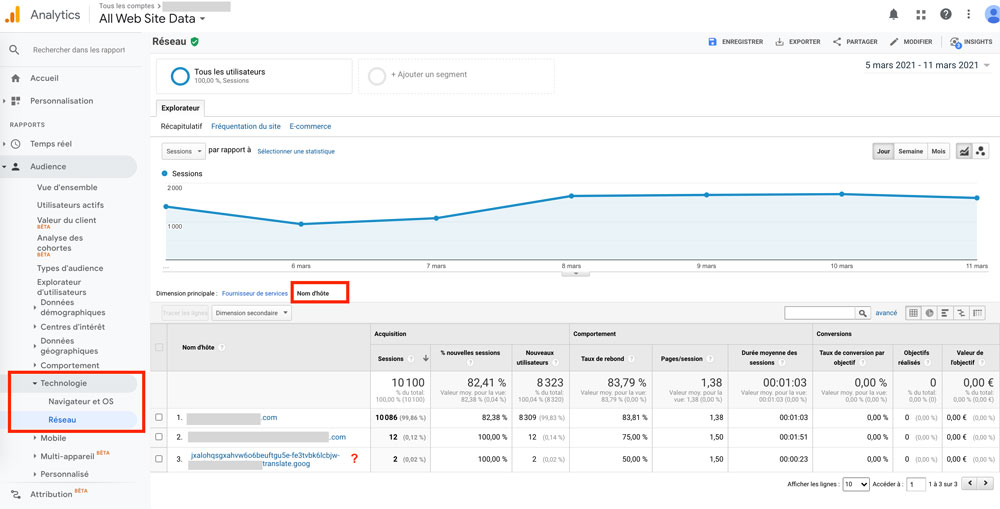
Et filtrez les noms d’hôtes indésirables / spammy dans votre Administration :
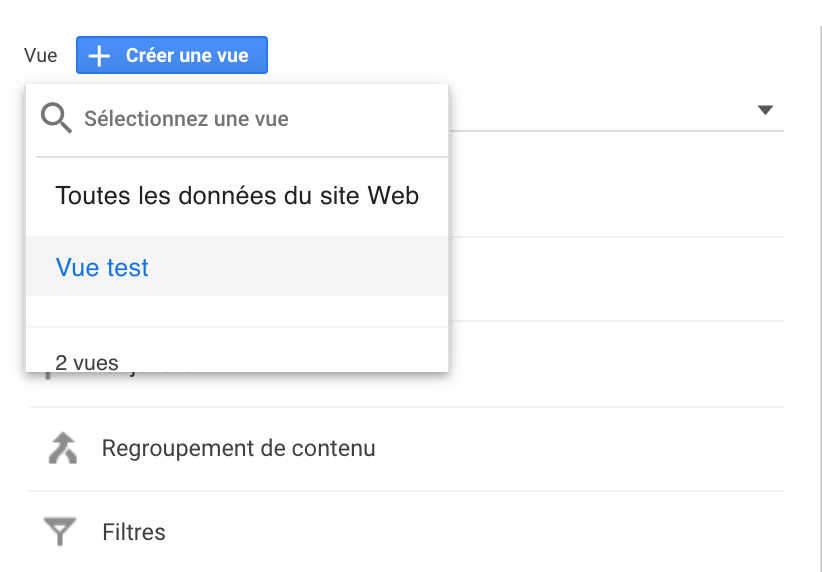
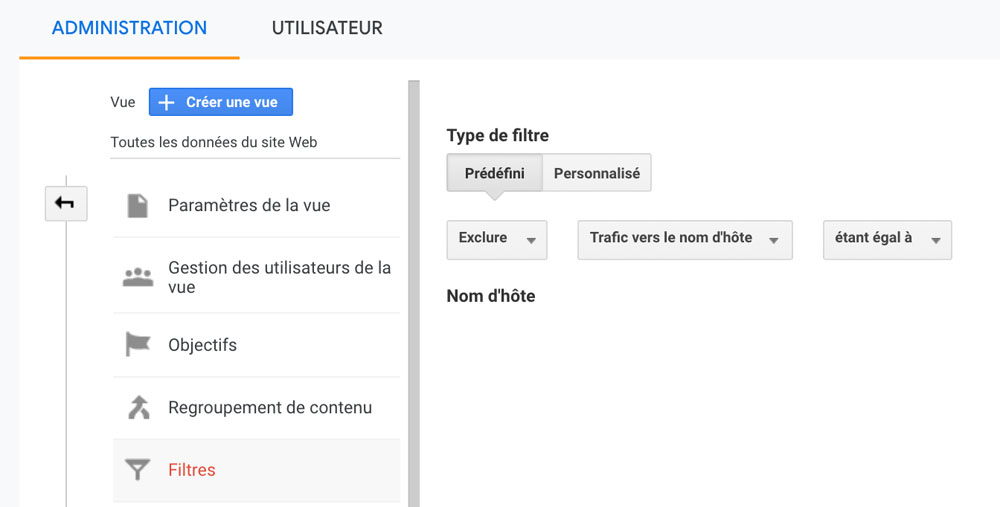
Colonne Vue, Sélectionnez votre vue puis Filtres et « exclure trafic vers le nom d’hôte ».
Le referrer, ou encore referral spam, peut complètement fausser vos données Analytics.
Il s’agit, pour le crawl referral, de sites faussement référents dont les robots viennent visiter votre site ;
ou dans le cas du ghost referral de simples protocoles s’attaquent à votre identifiant Analytics dans le but d’attiser votre curiosité, et vos visites.
Il existe des techniques pour repérer ce type de spam dans la ligne Referral du tableau des Canaux (menu Acquisition).
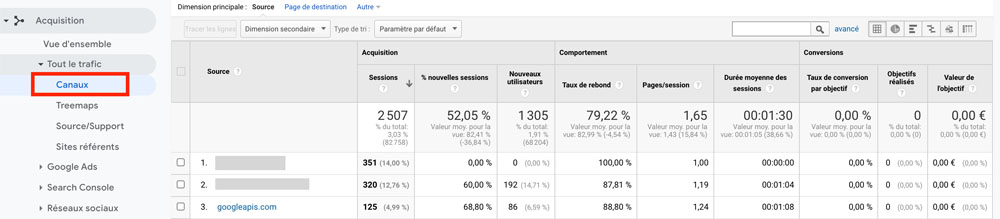
Par exemple pour repérer le ghost referrer spam, il faut donner comme dimension secondaire : « Nom d’hôte », et repérer les « (not set) ».
Le spam qui est sous la forme d’un nom de domaine peut être bloqué dans la fichier .Htaccess du répertoire racine du site, ou à travers un filtre dans une nouvelle vue Analytics :
(ou la même que celle créée pour filtrer des noms d’hôtes)
Type de filtre : Personnalisé, Cocher Exclure,
Champ de filtrage = Source de la campagne,
Règle de filtrage = entrer les termes du nom de domaine spammy séparés par \-|
L’outil d’analyse de Bing a quelques fonctionnalités intéressantes qui valent le détour.
Bing reste 2e derrière Google, et même si ce n’est que pour 4,5% de part de marché (principalement sur desktop), cela reste un gros chiffre en termes de recherche.
Optimiser son site pour Yandex a du sens à partir du moment où l’on vise le marché russe.
Donc si ça a du sens pour vous, c’est peut-être le moment de vous créer un compte.
Les 2 vrais points positifs de ce moteur de recherche :
Même chose que pour Yandex, sauf que Baidu s’applique au marché chinois.
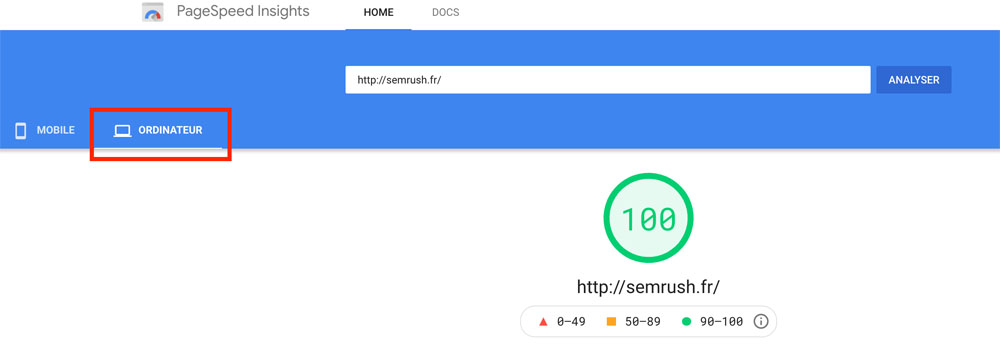
Vous allez voir que nous entrons de plus en plus dans l’audit de performance du site.
Changez d’onglet sur l’audit de PageSpeed Insight, qui est réglé par défaut sur mobile.
NB : vous pouvez aussi utiliser GTMetrix ou l’API de PageSpeed Insights disponible dans la version payante de Screaming Frog.
Cela représente des opportunités d’optimisation assez simples à saisir.
Ce plugin de cache va stocker des informations sur le serveur.
Celles-ci n’auront pas à être chargées de manière dynamique à chaque ouverture de page.
Vous pourrez trouver le détail de sa mise en place dans le chapitre 16 de ma checklist SEO wordpress.
Les outils SEOptimer sont gratuits pour un nombre limité d’utilisation par jour.
Le Webpage W3C Validator de SEOptimer vous fournit une appréciation de vos balisages web par rapport aux standards du consortium international W3C.
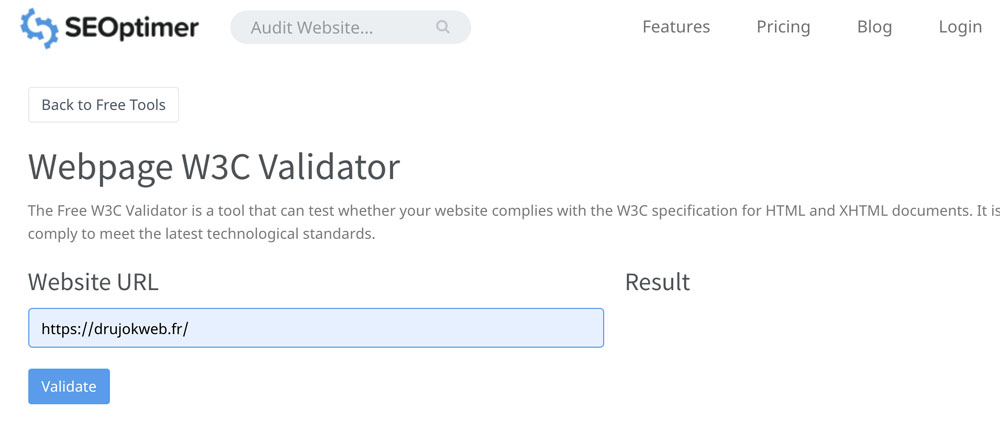
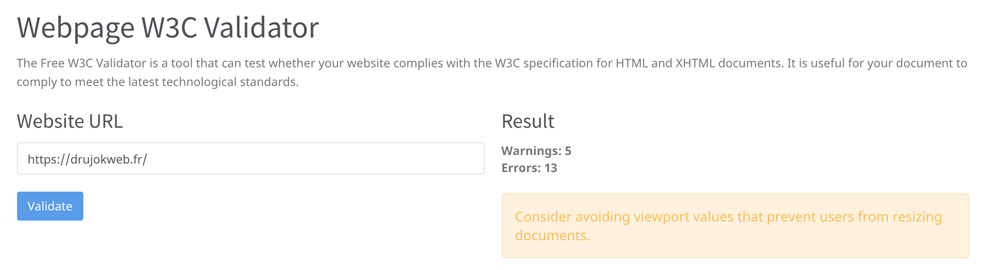
Utilisez le Deprecated HTML Tags Checker de SEOptimer pour faire cette vérification rapide.

Ce test s’effectue page par page avec Webpage Javascript Error Checking Tool.

La vérification se fait dans la section Performance de l’Audit Results.
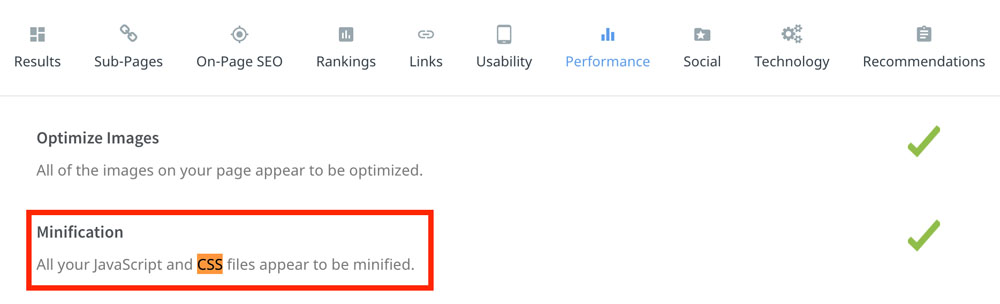
Si vous souhaitez procéder à cette minification (faire des raccourcis CSS pour alléger le poids de ces fichiers), utilisez l’outil CSS Minifier.

La vérification est faite, et pour l’outil de minification c’est JS Minifier !
Le style CSS « en ligne » met directement en forme une balise HTML spécifique grâce à l’attribut <style>.
Il est rarement utilisé, c’est une exception et ne doit pas être la règle
Vous trouverez encore ce rapport dans la section Performance de l’audit de site fait par SEOptimer.
Et vérifiez ainsi sa compatibilité pour la recherche sur mobile.
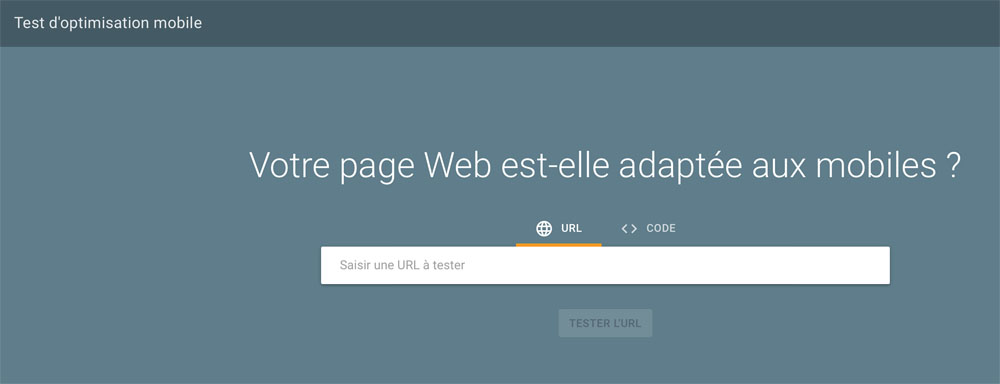
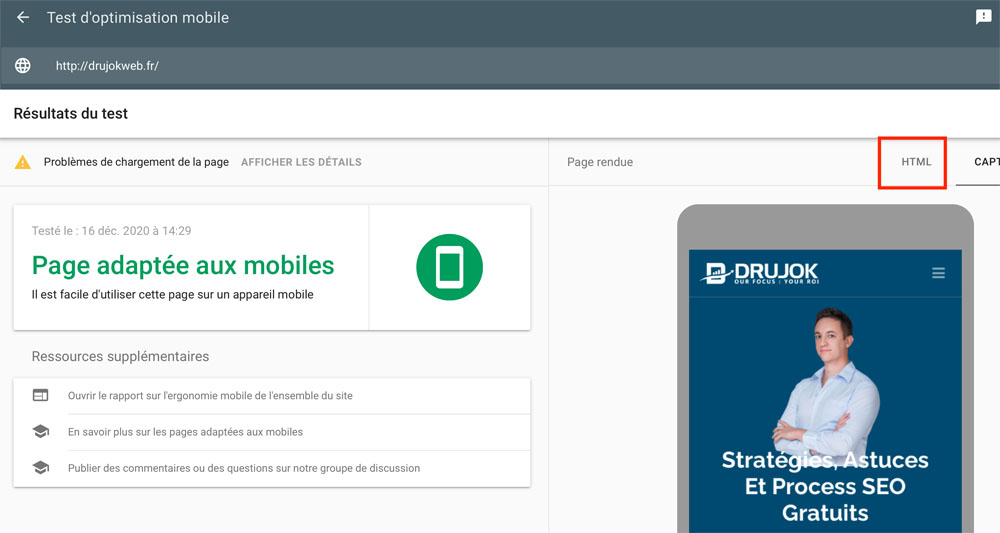

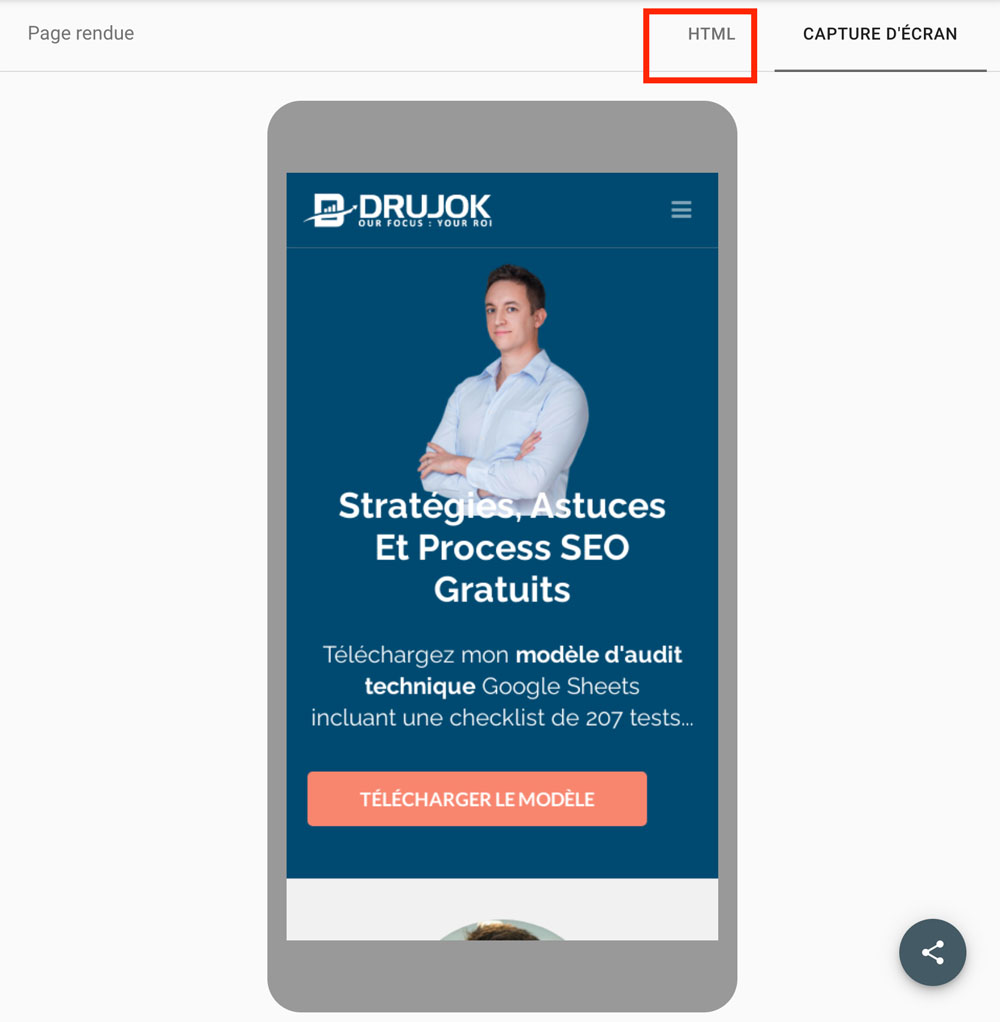
Comparez le HTML de la capture d’écran du test d’optimisation mobile avec ce que vous obtenez dans le navigateur.
Assurez-vous que les liens et les contenus les plus importants soient bien présents dans le code HTML.

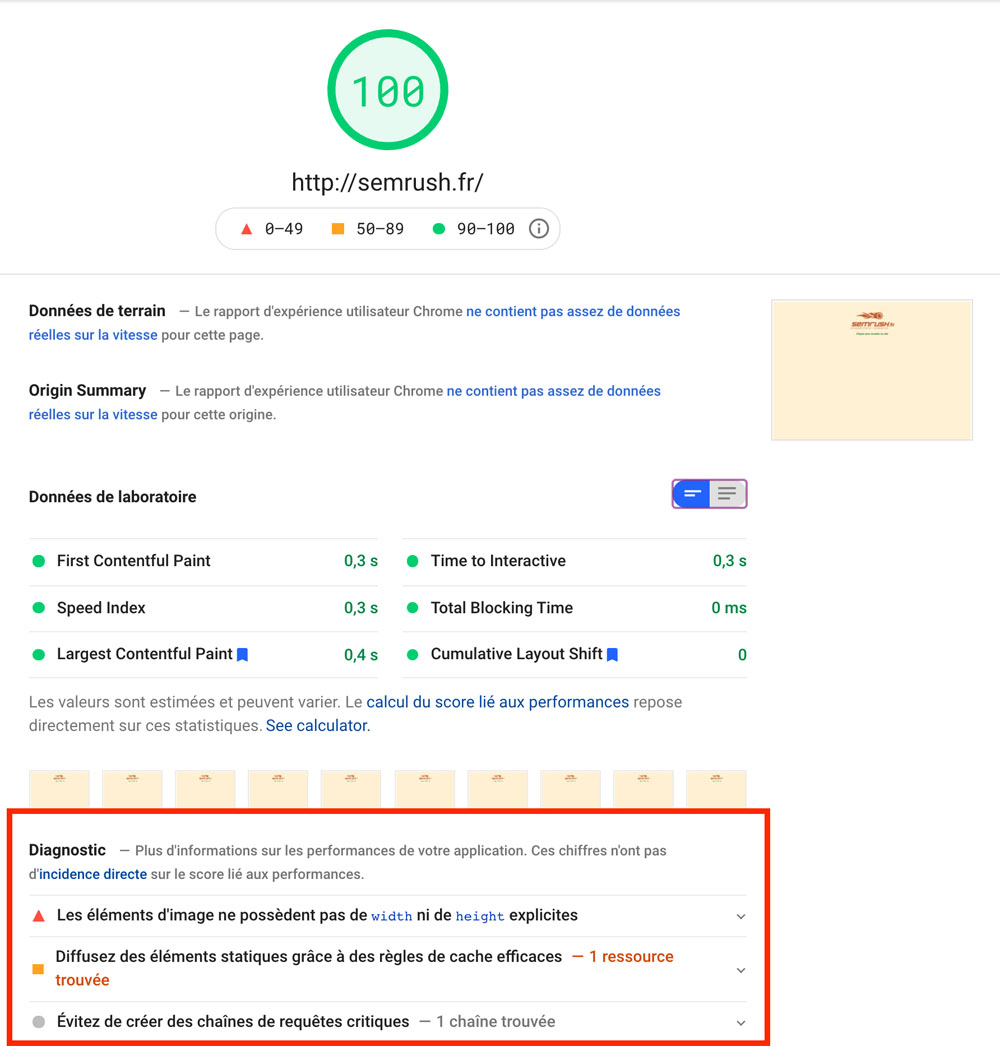
Cet outil de Google vous donne un score global de vitesse (il faut viser au-dessus de 80).
Il fournit aussi des conseils sur l’amélioration de la vitesse de la page analysée,
en commençant par les éléments dont le score est inférieur à 50.
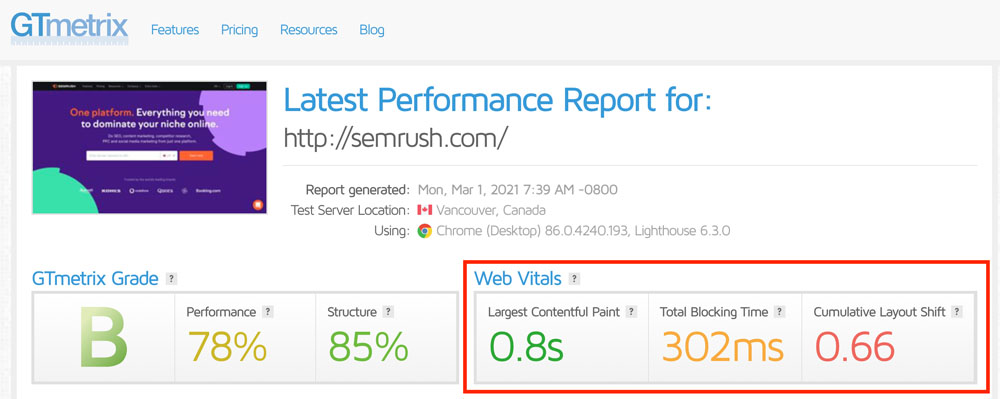
L’outil a une interface qui permet d’avoir un aperçu au premier plan des Core Web Vitals (ou Page Experience).
Ceux-ci sont focalisés sur trois critères : rapidité de chargement, interactivité, et stabilité visuelle.
Ils sont représentés par ces trois mesures :
Sous les temps de chargement, vous avez également une représentation visuelle du chargement des différents éléments.
Sur le PageSpeed Insights, les Core Web Vitals sont signalés par un petit marque page.
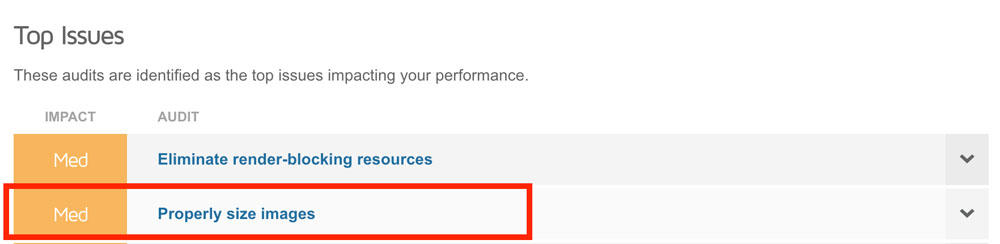
Développez le menu pour voir quelles images devraient être redimensionnées / compressées.
Pensez à adopter des formats d’images nouvelle génération (comme JPEG2000 ou WebP) pour optimiser leur compression.
Avant de toucher au site dans son ensemble, faites-en toujours une sauvegarde.
Celle-ci doit être située ailleurs que les fichiers originaux.
Sur WordPress, il existe des plugin pour cela comme BackWPup.
Cette exploration est importante pour les sites de taille conséquente.
Les fichiers logs ou « journaux » répertorient toutes les requêtes effectuées sur le serveur (par les humains et les moteurs de recherche) et les données qui leur sont associées.
L’outil Log File Analyzer de SEMrush analyse ces fichiers pour vous aider à comprendre comment les moteurs de recherche interagissent avec votre site.
Il aide à voir votre site à travers les yeux du Googlebot et autres robots.
Vous pourrez ainsi mettre au jour des problèmes comme une déperdition du budget de crawl.
La marche à suivre pour obtenir ces fichiers logs est indiquée sur la page d’accueil de l’outil.
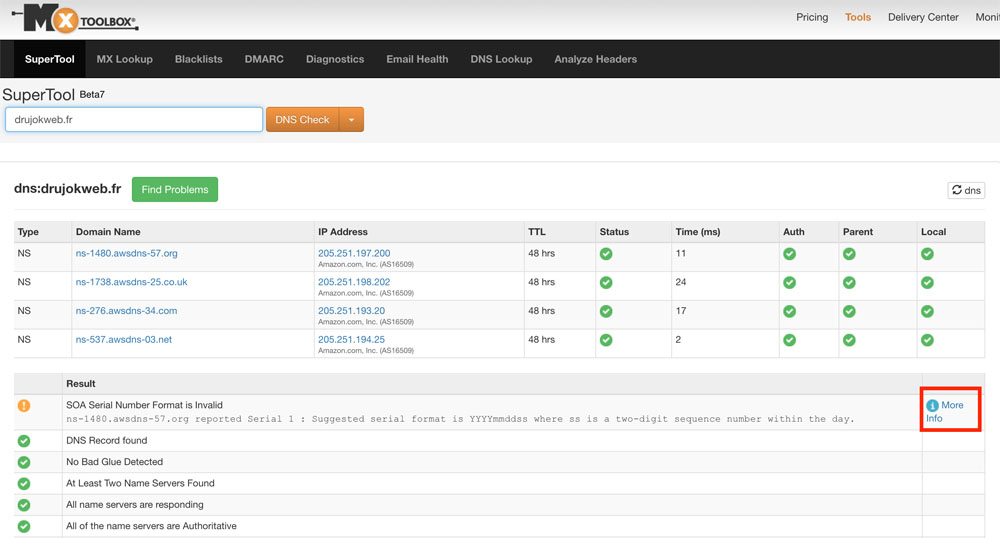
Tous les problèmes qui peuvent être rencontrés avec votre serveur DNS (qui traduit votre nom de domaine en adresse IP) peuvent être trouvés avec l’outil Super Tool de MxToolBox.com.
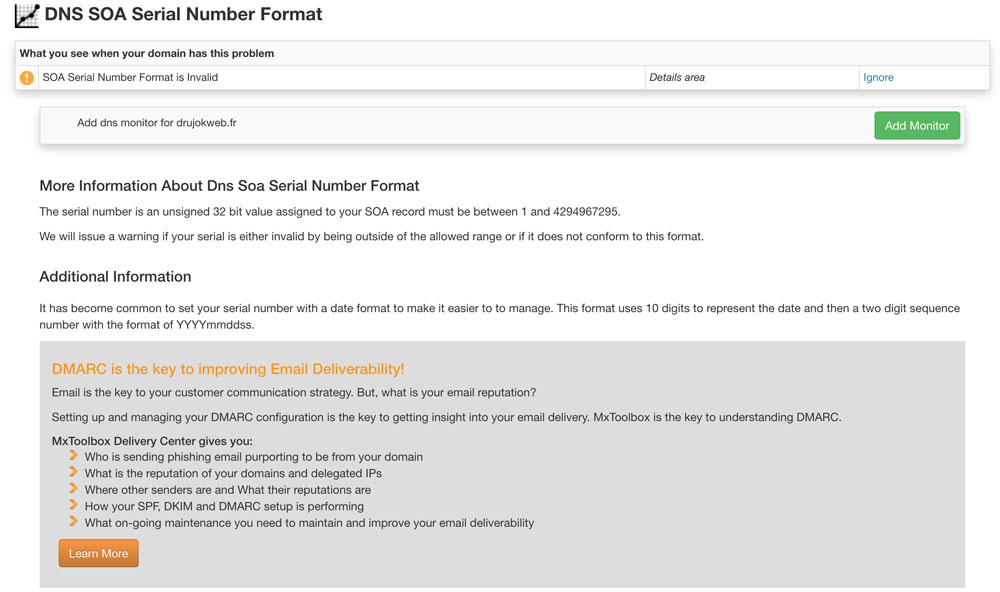
En cliquant sur More Info, et en créant un compte gratuit, vous aurez tous les détails sur chaque erreur et la possibilité de les résoudre.
Si votre site est hebergé à une adresse IP proche de nombreux sites spammy, cela pose des questions sur sa fiabilité.
Cela peut entacher votre réputation auprès de Google.
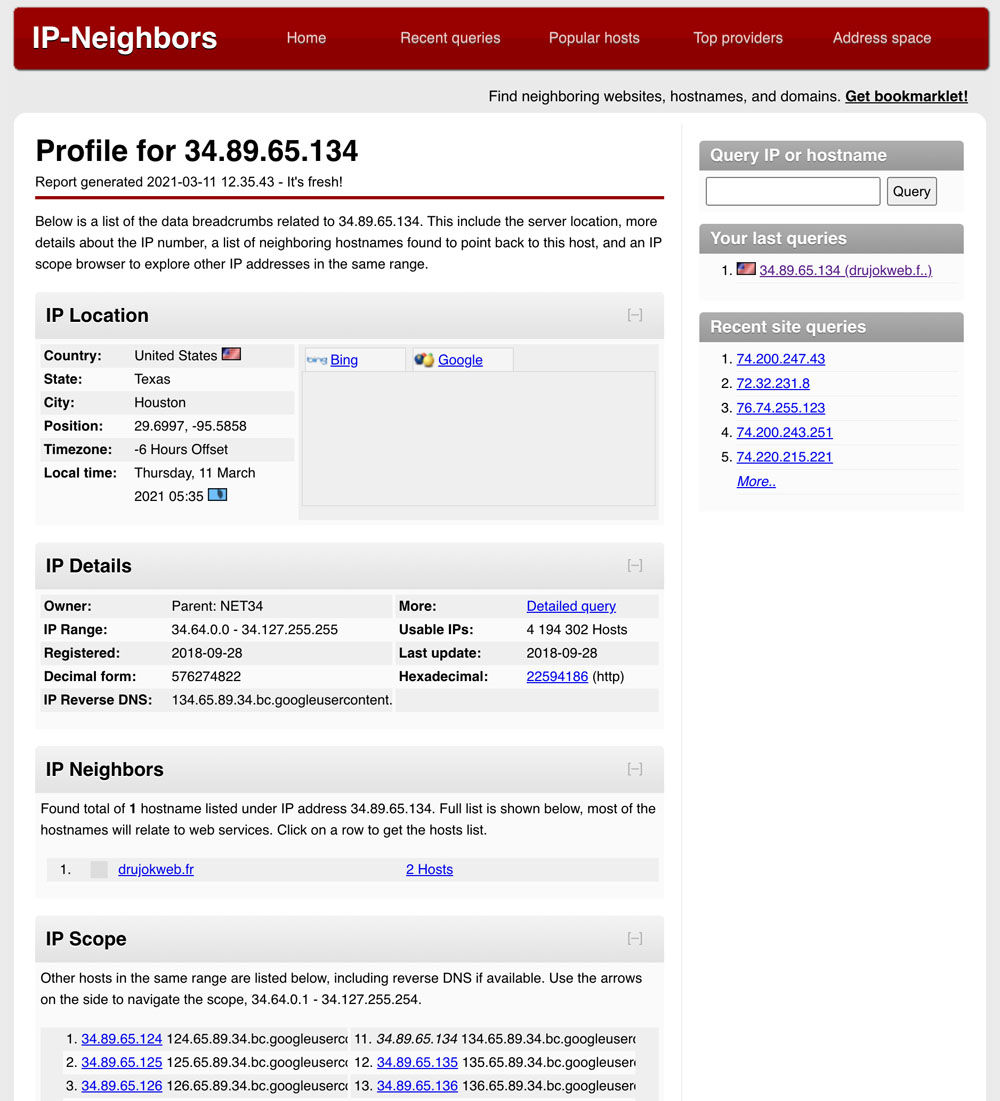
Vérifiez qui sont vos voisins d’IP (si vous en avez) et de plage IP avec l’outil IP Neighbour.
La migration vers le protocole HTTPS peut entraîner des problèmes de duplication.
Pour voir si votre site possède deux versions (HTTP et HTTPS) dommageables pour le référencement, vous pouvez simplement le rechercher avec l’opérateur de recherche suivant :
site:votresite.com
Et vérifiez si la même page apparaît deux fois.
Le site ne doit pas être accessible dans ces deux versions car il serait dupliqué.
L’une des deux doit être choisie comme canonique, et l’autre avoir une redirection 301.
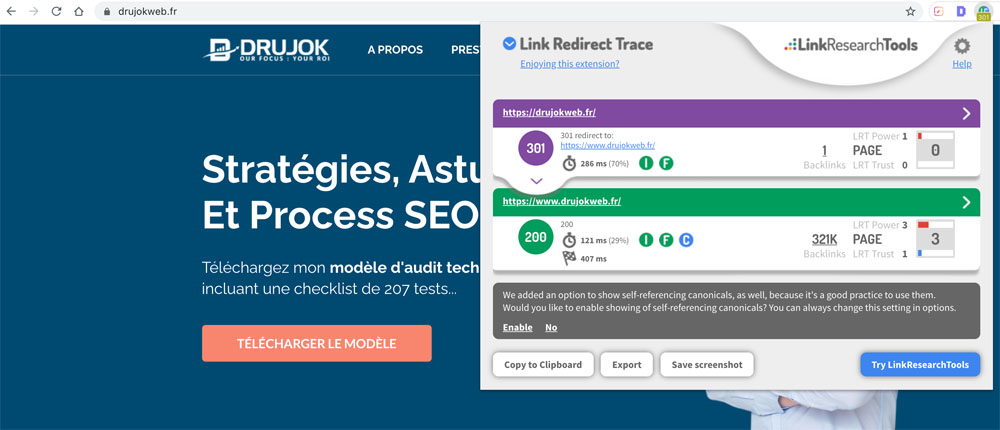
Vous pouvez vérifier cela avec l’extension Chrome Link Redirect Trace.
Ici j’ai entré la version non-www de mon site dans mon navigateur :
Si jamais votre site est hébergé sur un serveur doté d’un système d’exploitation sensible à la casse, alors vous avez deux options :
C’est le rapport Problèmes de sécurité juste en dessous des Actions manuelles.

Parmi les problèmes que votre site peut rencontrer… :
Pendant que vous y êtes, parez aux éventuels problèmes de sécurité en mettant à jour votre CMS ainsi que ses plugins.
L’utilisation du protocole HTTPS est un facteur de classement Google en place depuis 2014.
Si vous n’avez pas déjà cette information, vous pouvez aller dans :
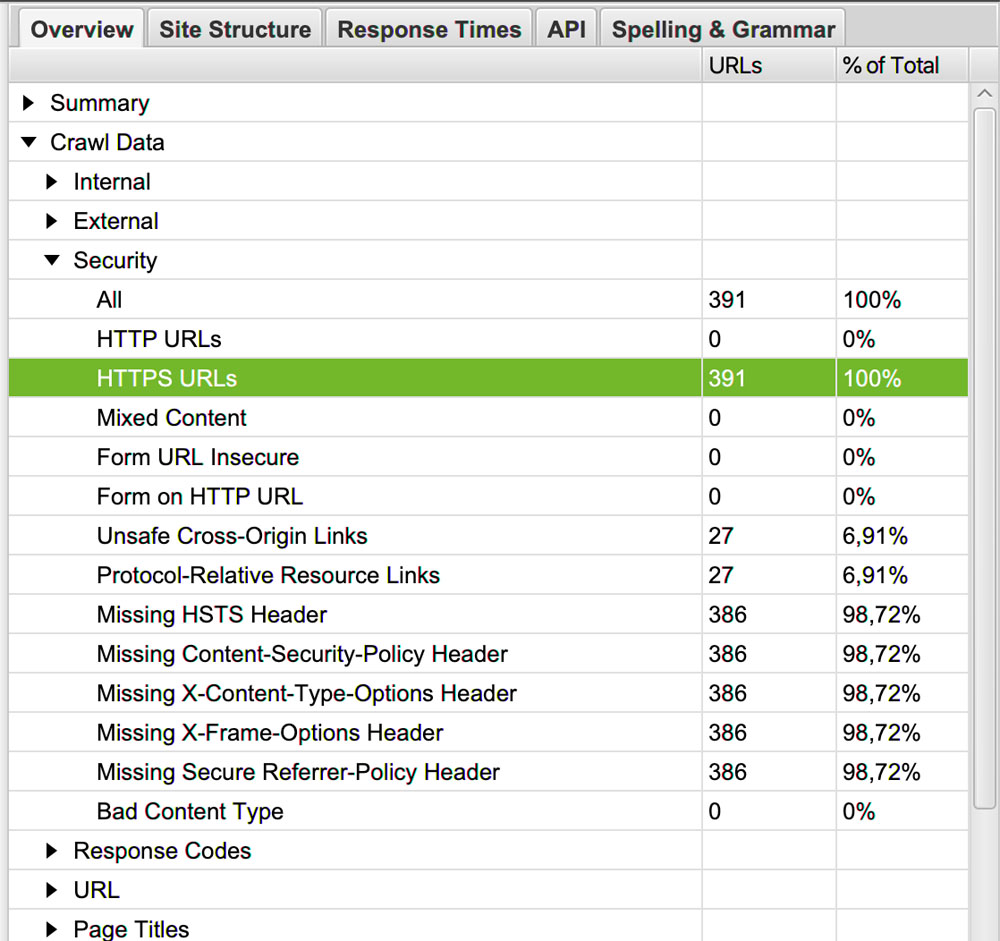
Overview > Crawl Data > Security > HTTPS URLs
Si vous n’avez pas de certificat SSL, installez-en un au plus vite sur votre serveur.
Vérifiez les URLs HTTP (voir ci-dessus) dans Screaming Frog et assurez-vous que les redirections soient bien permanentes (code 301).
Même pourvu d’un certificat SSL, le site peut toujours charger une partie de son contenu à partir d’un endroit non protégé par la clé de sécurité.
Cela arrive parfois sur des images, fichiers audio / vidéo, sur la JavaScript…
Descendez sur la ligne Mixed Content du menu Security de Screaming Frog pour vérifier qu’il ne reste pas de contenu non sécurisé.
Pour pallier à ce problème, vous pouvez sécuriser ces ressources par lot (avec un plugin WordPress par exemple comme SSL Insecure Content Fixer),
ou bloquer le contenu mixte (chose que Chrome fait automatiquement dorénavant) avec une directive CSP sur le serveur.
Les sites WordPress sont particulièrement sensibles aux attaques.
Vous pouvez y parer en installant un plugin tel que Wordfence… et ne plus y penser.
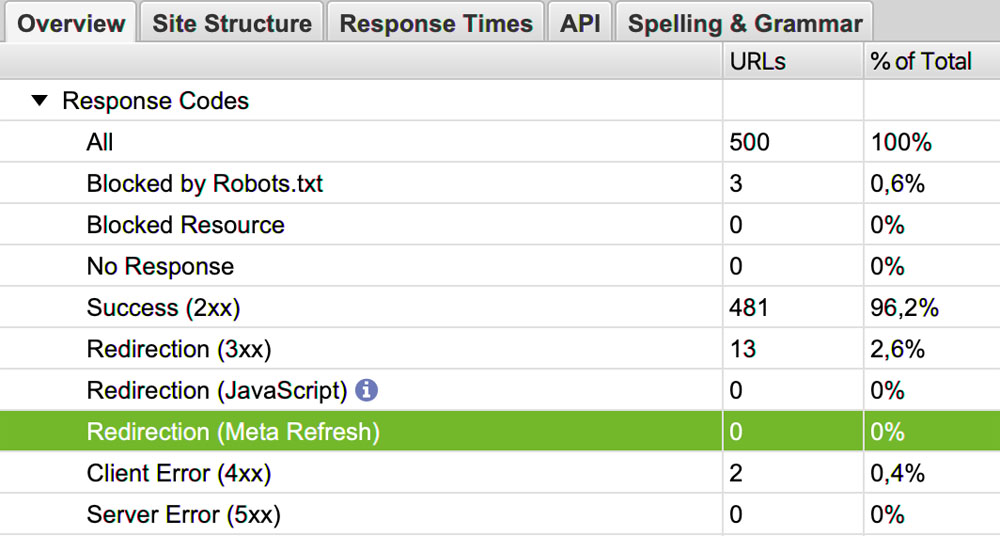
Les codes HTTP représentent la réponse du serveur à la demande formulée par le navigateur.
Les codes en 200 indiquent un bon fonctionnement, ceux en 300 des redirections,
ceux en 500 des problèmes divers de serveur,
et en 400 : des erreurs.
Si de nombreuses pages renvoient un code d’erreur (xx, c’est qu’il peut y avoir des problèmes de serveur.
Il est possible qu’il soit surchargé ou qu’il y ait besoin d’une configuration.
Si de nombreuses pages renvoient un code 404 (not found) ou un code 401, cela peut affecter l’UX négativement.
Et cela vaut pour les liens internes COMME externes.
Si des backlinks pointent vers vos pages 404, Google ne prendra pas en compte ces liens.
Le mieux est de les rediriger en 301 vers des pages (pertinentes) qui fonctionnent.
Les liens internes vers ces pages-là doivent être supprimés, ou remplacés par des liens vers des pages existantes.
Une page « soft 404 » est une page qui est inexistante mais qui renvoie tout de même un code 2xx.
Dans ce cas, elle va continuer à être indexée par Google et les utilisateurs vont se retrouver dans une impasse.
Avec l’outil Headers (https://headers.cloxy.net/), obtenez immédiatement la réponse du serveur pour n’importe quelle URL.
Une page d’erreur rudimentaire a un aspect un peu brut.
L’expérience utilisateur en est affectée.
Une page d’erreur doit avant tout être claire sur le fait que la page recherchée n’existe pas ou plus.
Personnalisée et dans le ton de votre marque, elle incite davantage l’utilisateur à rester sur le site.
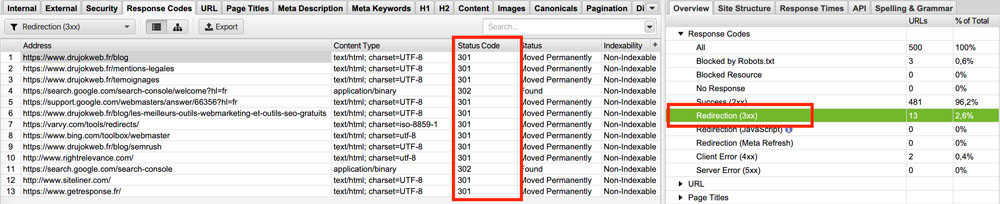
Le rapport Screaming Frog sur les chaînes de redirection se trouve dans le menu Reports de la barre de l’ordinateur.
Il se télécharge directement en .csv.
Ce qu’il faut savoir, c’est qu’après 2 ou 3 redirections, Google arrête l’exploration d’une page.

La plupart du temps, vous devez utiliser des redirections 301 (c’est-à-dire permanentes).
Les redirections 302 indiquent des changements temporaires.
Il faut donc faire en sorte qu’il n’y ait pas de redirection 302 laissée par erreur.
Overview > Response Codes > Redirection (3xx) -> Status Code.
Ces redirections indiquent au navigateur de rediriger vers une autre page après une durée de chargement définie.
Cette redirection a été utilisée abusivement (vers des pages satellites) mais surtout elle affecte l’expérience utilisateur.
Par exemple, elle garde dans l’historique de navigation la page initiale.
Vous trouverez ces éventuelles redirections dans le menu Response Codes sur la ligne Redirection (Meta Refresh).
Si le site dispose d’un certificat SSL (indispensable), toutes les versions qui ne sont pas en HTTPS doivent rediriger de façon permanente vers les URLs en HTTPS.
Et bien sûr, sans chaîne de redirection.
Les plugin WordPress sont très, très pratiques, mais à force d’en installer :
Passez-les donc en revue pour éliminer ceux qui contribuent (pour rien) à alourdir le chargement du site.
Bonus: cliquez ici pour accéder au Modèle Google Sheets avec 207 tests pour réaliser un audit SEO technique complet.
On ne peut pas dire que l’audit SEO technique d’un site soit une partie de plaisir.
Mais ce qui est sûr, c’est que ces tâches deviennent un peu moins ingrates avec un peu d’organisation, et quand on a sous la main les solutions pour les faciliter.
J’espère que cette checklist vous a aidé à y voir clair, et que vous l’utiliserez sans modération…
Y a-t-il des vérifications qui manquent, selon vous ?
Donnez-moi votre avis dans les commentaires.
Formation SEO et stratégies de référencement
naturel avancées


Merci Remi pour cet article, cela va beaucoup m’aider dans mon SEO.
Avec plaisir, ravi que ça puisse vous aider!
Article très très complet pour du free ! Bravo.
Merci ! En espérant ça que ça aide 🙂