
Connaissez-vous les critères qu’utilise Google pour classer les milliards de documents qu’il indexe ?
Dans cet article, j’ai compilé un MAXIMUM de facteurs en réunissant les informations les plus à jour.
Pour cela je me suis basé sur :
Vous verrez que certains critères de positionnements sont indiscutables.
D’autres sont plus probables ou spéculatifs.
Tandis que certains n’en sont pas le moins du monde malgré leur réputation tenace…
Tous ces critères sont rangés en fonction de plusieurs caractéristiques présents dans le système de filtres ci-dessous.
Bonne découverte !
Bonus: cliquez ici pour recevoir mon outil de projection du trafic pour connaitre le potentiel de trafic organique de votre site pour les 12 prochains mois.
 Domaine
Domaine
 On Site
On Site
 Positif
Positif
 Très certainement
Très certainement
Les domaines récents peuvent recevoir un coup de pouce temporaire.
Domaine
On Site
Positif
Très certainement
Cela peut paraître contre-intuitif mais l’ancienneté d’un domaine présente ses propres avantages.
Un domaine ancien génère une certaine dose de confiance.
Domaine
On Site
Positif
Très certainement
Un fort bonus est appliqué sur les noms de domaines qui matchent exactement un mot-clé et la requête Google correspondant à ce mot-clé.
L’intention, c’est d’abord que cela bénéficie aux marques, pour qu’elles se classent en 1ère position sur leur propre nom.
Cet avantage a perdu en force dans certaines circonstances puisqu’il a été très exploité, et il n’est pas valable pour les sites de mauvaise qualité.
Domaine
On Site
Positif
Très certainement
Un nom de domaine qui commence par le mot-clé cible est avantagé par rapport à un domaine qui n’a pas ce mot-clé, ou qui l’intègre après d’autres mots.
Domaine
On Site
Positif
Officiel
Un bonus de classement est attribué au site quand un mot ou une phrase clé est intégré(e) au nom de domaine.
C’est un peu moins déterminant qu’un match exact, mais tout de même plus important qu’un mot-clé qui n’apparaît que plus tard dans l’URL.
Domaine
On Site
Positif
Probablement
Un brevet Google stipule que les « domaines estimables (légitimes) sont souvent achetés pour plusieurs années, tandis que les domaines satellites (illégitimes) sont rarement utilisés plus d’un an.
Par conséquent, la date à laquelle un domaine va expirer peut servir à prédire sa légitimité. »
Domaine
On Site
Positif
Très certainement
Un nom de sous-domaine qui reprend un mot-clé reçoit un coup de boost significatif.
Selon le très autoritaire Moz, cela surpasse par ailleurs un mot-clé qui serait une extension de domaine (comme .info, .shopping, .agency, etc).
Domaine
On Site
Positif
Incertain
Dans la logique où une donnée WhoIs rendue privée a un effet négatif, on peut en déduire qu’un WhoIs public est un facteur au moins neutre, si ce n’est positif.
Domaine
On Site
Positif
Très certainement
Un domaine enregistré il y a longtemps est signe d’une certaine légitimité.
À l’inverse, les domaines dédiés au spam ont une durée de vie (et donc d’action) très courte.
À ce sujet, voir notamment ce brevet Google sur l’historique des domaines.
Domaine
On Site
Positif
Officiel
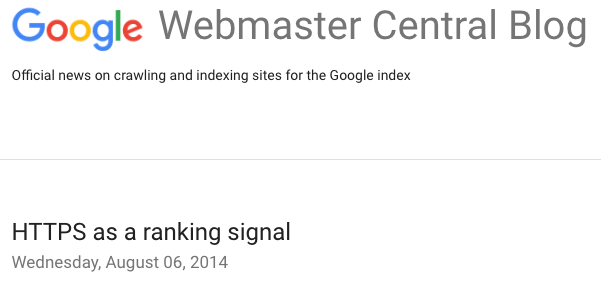
C’est un facteur annoncé officiellement par le Webmaster Central Blog de Google en 2014 :
l’utilisation du protocole HTTPS.
Google a promis à ce moment-là d’en faire un signal positif de plus en plus fort.
Domaine
On Site
Positif
Très certainement
Le code pays en extension de domaine, comme .fr, est un signal de pertinence fort pour un marché spécifique à ce pays.
Domaine
On Site
Positif
Mythe
Commencer ou non un sous-domaine par www ne change rien en terme de référencement.
Domaine
On Site
Positif
Très certainement
Les sous-répertoires participent des données structurées.
Ils permettent de créer des breadcrumbs (des miettes de pain façon petit Poucet, ou « fil d’Ariane ») pour une architecture de site structurée et une bonne expérience utilisateur.
Ils pourraient passer un meilleur jus de lien au domaine en général que des sous-domaines (quoique cela soit démenti par l’analyste Google John Mueller), mais ils renseignent surtout parfaitement Google de l’étendue des sujets que couvre votre domaine.
Domaine
On Site
 Négatif
Incertain
Négatif
Incertain
Il semble assez probable qu’un domaine puisse être jugé en fonction du risque que l’utilisateur a de tomber sur une page d’erreur (ajouter à cela les pages portant des liens cassés, etc.).
Domaine
On Site
Négatif
Très certainement
Un domaine de premier niveau national se positionnera bien dans le pays cible, mais nécessairement moins bien à l’extérieur de ce pays… à l’exception de certains ccTLD qui se sont « internationalisés », comme .co.
Domaine
On Site
Négatif
Incertain
Les sous-domaines peuvent être perçus comme des sites à part entière par Google, ce qui peut impacter beaucoup de facteurs.
Domaine
On Site
Négatif
Officiel
Acquérir un nom de domaine nécessite de faire un peu de recherche et de connaître son historique, parce que des pénalités peuvent vous coller à la peau (Matt Cutts est assez explicite là-dessus dans cette vidéo).
Selon l’analyste John Mueller cité par le Search Engine Journal, un domaine ayant été en mauvais termes avec Google et repris par un nouveau propriétaire devrait voir son historique remis à zéro… si l’activité suspecte n’a pas duré trop longtemps.
Domaine
On Site
Négatif
Incertain
Donner de fausses informations pour enregistrer un domaine est une violations des règles de la société de régulation ICANN (Internet Corporation for Assigned Names and Numbers, ou Société pour l’attribution des noms de domaine et des numéros sur Internet).
Vous pouvez être reporté, ou même hijacké sans pouvoir rien y faire.
Domaine
On Site
Négatif
Incertain
Dissimuler les informations de cette base de données sur les noms de domaines peut, cumulé à d’autres facteurs du même type, attirer des suspicions sur l’intention du webmaster.
Domaine
Off Site
Négatif
Incertain
S’il a été pénalisé une fois, un webmaster a intérêt a montrer patte blanche pour ses autres sites, parce que le moteur de recherche l’attend au tournant.
Serveur
On Site
Positif
Mythe
Avoir une adresse IP dédiée ne fournit pas d’avantage direct, contrairement à une certaine croyance.
Cela peut être utile par contre en cas de ciblage géographique.
Et cela peut encore être un prérequis pour obtenir un certificat SSL.
Serveur
On Site
Positif
Probablement
Matt Cutts l’a expliqué dans une vidéo de 2009 :
« On regarde l’adresse IP de votre serveur web.
Si votre serveur est situé en Allemagne, nous serons plus enclins à penser que votre site est utile aux utilisateurs allemands.
Ce n’est pas le seul pays dans lequel on affichera votre site, et nous regardons aussi les domaines de premier niveau (…).
Si vous trouvez une super affaire dans un pays en particulier et que vous voulez vraiment garder votre serveur dans ce pays, ce n’est pas un problème.
Mais si ça vous inquiète ou que vous voulez expérimenter, essayez de changer la situation géographique de votre serveur (ce qui veut dire changer votre adresse IP) et ça peut vous aider dans certains pays. »
Serveur
On Site
Négatif
Incertain
Des brevets et autres articles sur PageRank ont suggéré que les redirections faisaient perdre une petite fraction d’autorité et menaient à un affaiblissement de PageRank.
Quoiqu’il en soit, dès 2016 l’analyste Gary Illyes a déclaré sur Twitter que ce n’était plus le cas.
Il n’empêche que les redirections en chaîne peuvent affecter les performances du site.
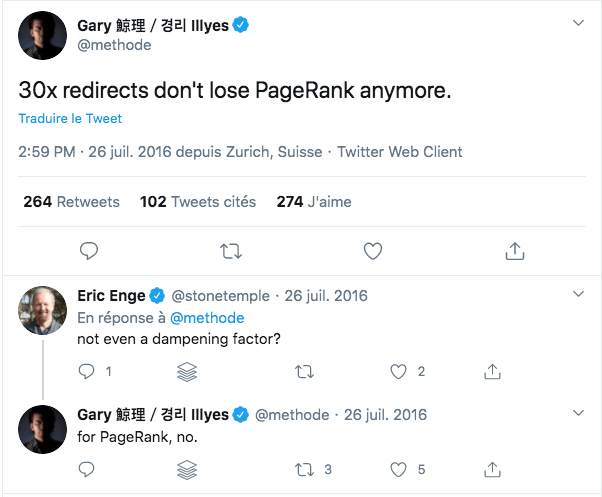
Serveur
On Site
Négatif
Très certainement
Vous ne pouvez pas toujours contrôler qui se trouve à la même adresse IP que vous dans votre serveur.
Comme le dit Matt Cutts, dans certains cas extrêmes, ça peut être un problème :
« si vous avez des milliers et des milliers de sites spammy sur une seule adresse IP, et un site normal au milieu… ça peut faire mauvaise figure. »
Serveur
On Site
Négatif
Incertain
Il y a plusieurs types de certificats SSL.
Dans sa promesse de rendre la navigation de plus en plus sécurisée, il paraît intéressant d’imaginer que Google puisse favoriser les sites dont le chiffrement SSL possède un niveau de sécurisation élevé.
Serveur
On Site
Négatif
Officiel
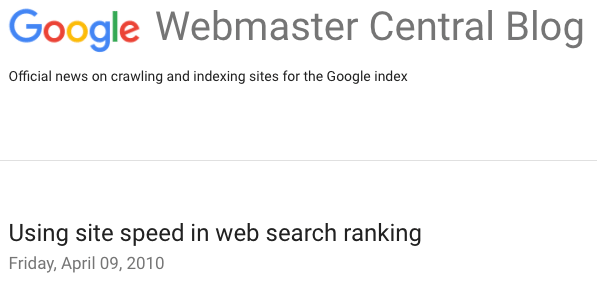
Depuis 2010, la rapidité de chargement d’un site est devenue un facteur officiel.
Elle répond à l’objectif « expérience utilisateur », et Google affirme qu’elle réduit aussi les coûts d’opération.
En terme de hiérarchie, elle se situe tout de même sous les questions de pertinence et d’autorité.
Serveur
On Site
Négatif
Officiel
L’uptime, c’est de pourcentage de disponibilité de votre site sur un temps donné (par exemple une année), en fonction du fonctionnement du serveur.
Il est important qu’il avoisine les 100%, pour être correctement indexé et garantir une bonne expérience utilisateur.
Serveur
On Site
Négatif
Officiel
Les erreurs 4xx ou 5xx indiquent des erreurs sur la page côté client du serveur, ou côté serveur, et envoient un signal de mauvaise qualité.
Vérifiez celles qui peuvent être corrigées notamment via des redirections 3xx.
Serveur
On Site
Négatif
Incertain
L’en-tête HTTPS Expires peut améliorer la performance de votre site.
Malheureusement cela peut affecter l’indexation et écarter les robots pour une durée plus longue que la durée souhaitée.
Serveur
On Site
Négatif
Très certainement
Pour bloquer l’indexation ou l’exploration d’un document autre que HTML par le moteur de recherche au niveau du serveur (et pas par un fichier robots.txt à la racine du site), on peut utiliser un en-tête HTTP X-Robots-Tag.
Mais une erreur dans l’utilisation de cette instruction et les conséquences peuvent être très négatives pour le référencement.
Sitewide
On Site
Positif
Très certainement
La densité d’utilisation d’un mot-clé sur la totalité du domaine peut servir à « rééquilibrer » l’autorité vers certaines pages.
Certaines pages ne possèdent pas encore suffisamment d’autorité, mais méritent un coup de pouce étant donné l’expertise du site en général sur un sujet.
Sitewide
On Site
Positif
Officiel
Assez logiquement, plus une page possède de liens internes, plus elle doit s’en trouver avantagée par rapport aux autres.
Même si outre leur nombre, la distribution architecturale de ces liens est également importante.
Sitewide
On Site
Positif
Officiel
Voici comment ça marche :
Les pages qui ont des liens internes sur l’ensemble du site sont fortement avantagées.
Celles qui ont des liens à partir de ces dernières le sont un peu moins, etc.
De la même manière, une page bénéficie fortement d’un lien sur la page d’accueil ou sur des pages à l’autorité forte.
Une architecture de site optimisée met ainsi en valeur les pages les plus importantes.
Sitewide
On Site
Positif
Incertain
Il peut être raisonnable de supposer que si l’algorithme Query Deserves Freshness s’applique à un certain nombre et à un certain type de sujets et requêtes définis, alors pour les autres sujets, c’est un contenu plus ancien qui prime.
Sitewide
On Site
Positif
Incertain
Les instructions aux évaluateurs de Google (les fameux Google Quality Raters) spécifient que ces derniers doivent vérifier que des informations de contact sont accessibles aux visiteurs d’un site, pour attester de la légitimité de celui-ci – en fonction bien sûr de son objectif principal -.
Sitewide
On Site
Positif
Très certainement
Il est clair que les documents / pages sont évalués à travers un score de nouveauté.
Le fait qu’une moyenne soit ensuite établie pour l’ensemble du site paraît logique, puisque cette même méthode est appliquée en ce qui concerne le contenu médiocre (algorithme Panda) ou l’expertise sur un sujet (algorithme Hilltop).
Sitewide
On Site
Positif
Très certainement
La pondération « TF-IDF » (Term Frequency-Inverse Document Frequency ») ne prend pas seulement en compte la fréquence d’un terme, mais l’importance de cette fréquence dans un document comparativement à d’autres documents.
Autre, Sitewide
On Site
Positif
Très certainement
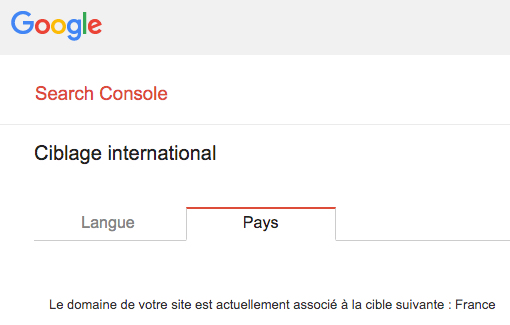
La Google Search Console possède un outil appelé « Rapport sur le ciblage international » qui permet de définir un pays cible, dans le cas où le site a un domaine de premier niveau générique comme .com ou .net.
Cela peut donc favoriser le positionnement dans le pays sélectionné.
Sitewide
On Site
Positif
Incertain
L’impact positif qu’aurait une politique de confidentialité est une théorie qui semble être partagée par une grande proportion de SEOs, comme l’a montré le sondage du Search Engine Roundtable en 2012.
Ça ne reste qu’une hypothèse mais qui est très conforme à la philosophie « sécuritaire » de la firme de Montain View.
Voir à ce sujet l’article du Journal du Net datant de 2018.
Sitewide
On Site
Positif
Très certainement
L’outil de réexamen de Google est l’action appropriée à effectuer après une pénalité manuelle (après avoir identifié et réglé le problème, évidemment).
Par contre, ces pénalités sont rares, et de fait le recours à cet outil rarement de circonstance.
Contenu, Sitewide
On Site
Positif
Incertain
C’est une hypothèse à vérifier, qui signifierait que s’il favorise un site en fonction de son score moyen de nouveauté, Google préfère en général le contenu récent.
Interaction utilisateur, Sitewide
On Site
Positif
Mythe
Oui, il existe un brevet sur le positionnement en fonction d’avis utilisateurs sur les produits.
Et il existe aussi un algorithme qui tente d’empêcher les marketeurs de générer une médiatisation par un bad buzz.
Mais cela ne veut pas dire que des commentaires positifs vont être un facteur avantageux, puisque comme l’a dit l’ancien responsable Google Amit Singhal en 2010:
Si nous rétrogradions les pages web qui font l’objet de commentaires négatifs, vous ne trouveriez pas beaucoup d’informations sur les personnalités politiques, sans parler de beaucoup de concepts importants mais controversés.
Interaction utilisateur, Sitewide
On Site
Positif
Très certainement
Les données utilisateurs sont aussi utilisées par Google pour mesurer le temps de chargement des pages.
Code, Sitewide
On Site
Positif
Officiel
La vitesse de chargement du site est l’un des plus certains facteurs de classement.
À ce sujet, un article très complet de SEMrush.
Sitewide
On Site
Négatif
Officiel
C’est plus qu’officiel, Google pénalise les sites sur-optimisés.
Ça comprend, entre autres :
Contenu, Sitewide
On Site
Négatif
Officiel
L’algorithme Panda traque le contenu sans aucune originalité, et il analyse particulièrement le domaine dans son ensemble.
Comme il établit une moyenne de qualité du contenu, la stratégie pour remettre son contenu à niveau sera différente que s’il favorisait une analyse page par page.
Il peut être intéressant par exemple d’empêcher certaines pages d’être indexées.
Sitewide
On Site
Négatif
Probablement
Trop de liens internes peuvent assez logiquement impacter l’expérience utilisateur chère à Google.
Surtout, ils divisent le jus de référencement / score PageRank, comme l’explique cette étude de SEMrush.
Sitewide
On Site
Négatif
Probablement
Pour commencer, les liens en footer sont moins intéressants que les liens contextuels.
Mais ils sont aussi fortement associés aux liens payants et à des pratiques spammy qui attirent les pénalités.
Sitewide
On Site
Négatif
Incertain
Si l’on en croit le succès de Wikipédia dont tous les liens sont en nofollow, on ne peut pas considérer que cet attribut peut être utilisé « à l’excès ».
Par contre, tout le monde n’est pas Wikipédia, et beaucoup de sites peuvent bénéficier d’un bon lien sortant en dofollow de temps en temps.
Sitewide
On Site
Négatif
Officiel
Les liens outbound, comme le reste du contenu, doivent paraître naturels.
Sinon, ils donnent l’impression qu’ils font partie d’un accord d’échange de liens.
Sitewide
On Site
Négatif
Officiel
Ces pages sont invisibles de l’architecture de votre site.
Au mieux, elles ne profitent d’aucun PageRank.
Au pire, elles peuvent être considérées comme des pages satellites et être pénalisées.
Sitewide
On Site
Négatif
Mythe
Le fait que posséder des liens sortants puisse impacter négativement votre site est un mythe.
Le bénéfice est supérieur au dommage subi par la relative fuite de PageRank.
Contenu, Sitewide
On Site
Négatif
Très certainement
Les algorithmes Hilltop, puis Panda, se sont attachés à évaluer l’expertise des sites sur des sujets.
Cela a eu pour effet d’impacter négativement des sites très légitimes mais extrêmement hétérogènes.
Sitewide
On Site
Négatif
Probablement
Trop de liens cassés sur une page peuvent-être le signe d’un site abandonné ou négligé, ce qui peut décevoir certains Raters (les évaluateurs manuels de Google, qui ne pénalisent pas directement les sites mais influencent à terme l’algorithme).
Contenu
On Site
Positif
Officiel
Le contenu récent bénéficie particulièrement de l’algorithme QDF (« Query Deserves Freshness » : La recherche mérite des informations nouvelles) de Google, appliqué sur certaines recherches… et pas d’autres.
Contenu
On Site
Positif
Officiel
Le contenu ancien peut répondre positivement à l’un des brevets de Google qui affirme :
Pour certaines recherches, des documents anciens seront plus adaptés que d’autres plus récents.
Concrètement, un résultat de recherche peut être classifié en fonction de l’âge moyen des documents qui le constituent.
Contenu
On Site
Positif
Probablement
Face à la concurrence, c’est l’originalité qui prime :
Google est capable de comparer des documents, d’en repérer d’abord les similitudes et de récompenser l’originalité du plus descriptif, unique ou spécial.
Contenu
On Site
Positif
Probablement
Tout comme le contenu dupliqué est analysé globalement et à l’intérieur-même d’un site web, c’est très probablement le cas aussi pour l’analyse de l’originalité d’un contenu.
Contenu
On Site
Positif
Officiel
Le renouvellement de votre contenu envoie un signal quant à son actualité.
D’autre part, il est préférable d’ajouter ou d’enlever des paragraphes entiers plutôt que de simplement modifier quelques mots.
Contenu
On Site
Positif
Très certainement
Il a été observé que les pages qui traitaient un sujet de manière exhaustive se positionnaient mieux que celles qui traitaient du même sujet plus partiellement.
Contenu
On Site
Positif
Officiel
Ça se résume ainsi : un contenu substanciel est toujours préférable à un contenu court et superficiel.
Contenu
Off Site
Positif
Mythe
En 2019, John Mueller, Webmaster Trends Analyst chez Google, a affirmé que le nombre de mots ne comptait pas, et ceci a été testé et prouvé par les experts.
Cela ne veut pas dire que le nombre de mots n’a pas un rôle à jouer dans l’originalité du contenu, le potentiel de répondre à davantage de requêtes, ou l’opportunité d’obtenir des backlinks, entre autres exemples.
Et donc in fine d’impacter le classement, mais c’est à prendre avec de grosses pincettes.
Contenu
On Site
Positif
Probablement
La pondération « TF-IDF » (Term Frequency-Inverse Document Frequency ») sur une page est plus fine qu’une simple analyse de fréquence de mot-clé.
Elle permet non seulement de comparer la fréquence d’un terme comparativement à d’autres pages – et donc de déduire l’importance que prend un sujet – mais aussi de juger du caractère « naturel » et donc qualitatif du contenu.
Contenu
On Site
Positif
Officiel
L’emphase sur certains mots (gras ou <strong>, italique, souligné, etc) sert effectivement à les mettre en valeur aux yeux de Google, dans son effort pour comprendre ce qui est pertinent dans un contenu.
Cela fonctionne tant que c’est utilisé de manière logique et naturelle.
Contenu
On Site
Positif
Probablement
Très logiquement, un contenu qui possède une correspondance exacte avec une phrase de recherche est valorisé dans les résultats.
Une correspondance partielle est également valorisée (sûrement moins), ce qui est confirmé par un peu de pratique.
On peut aussi s’appuyer sur ce brevet, et en conclure que le score évalué augmente au fur et à mesure de la correspondance des termes :
Le score de Récupération d’Information peut être mesuré de multiples façons. (…) Un document qui correspond à tous les termes d’une requête peut recevoir un score plus élevé qu’un document dont un seul terme correspond.
Contenu
On Site
Positif
Officiel
Varier les mots-clés en utilisant leur racine ou des synonymes est un facteur réel et important, voire indispensable.
Il vous permet de ne pas rester bloqué sur un mot-clé mais au contraire d’écrire avec le plus de naturel possible.
Il est donc important de ne pas exploiter ce facteur au point de créer un contenu très artificiel rempli de synonymes qui n’ont pas vraiment leur place.
Contenu, Domaine
On Site
Positif
Incertain
Séparer les mots de l’URL par un trait d’union peut aider Google à différencier ces mots et isoler les mots-clés.
Mais selon le SEO Learning Center de Moz, cela peut aussi être associé à un comportement spammy : dans tous les cas, ils recommandent de ne pas utiliser plus d’un trait d’union.
Contenu
On Site
Positif
Officiel
Google est assez clair sur le fait que les liens sortants de qualité, vers des sites à forte autorité, sont encouragés.
Contenu
On Site
Positif
Très certainement
Même si ce facteur n’est pas affirmé clairement par Google, des dizaines de facteurs relatifs au contenu et à sa qualité ont un rapport plus ou moins direct avec la grammaire, l’orthographe etc.
Et puis… c’est un facteur confirmé de Bing.
Contenu
On Site
Positif
Très certainement
Rien d’officiel sur les algorithmes actuels, mais en plus d’attirer naturellement plus de trafic notamment à travers les onglets images et vidéos, ce format a pour réputation chez Google de participer à un contenu de haute qualité.
Contenu
On Site
Positif
Incertain
Cela fait bien 10 ans maintenant que les mots-clés utilisés en meta description ne sont plus considérés comme un facteur de classement direct.
La meta description reste cruciale à votre taux de clics et donc à votre remontée dans la SERP.
Contenu
On Site
Positif
Probablement
Une formulation et une contextualisation de qualité remplacent naturellement en SEO un bourrage de mots-clés, notamment si l’on prend en compte un des brevets importants déposé (et régulièrement mis à jour) par Google :
L’indexation basé sur la phrase (Phrase-Based Indexing), qui permet d’identifier les phrases connexes.
Contenu
On Site
Positif
Très certainement
La fréquence de mise à jour des pages joue un rôle dans leur score de « fraîcheur » (ou nouveauté), qui est un facteur dans un certain nombre de cas.
Contenu
On Site
Positif
Très certainement
Bien que ça n’ait pas été vraiment confirmé, il semble qu’il y ait tout de même des avantages à définir clairement les variations linguistiques d’un site à travers les balises « hreflang ».
Contenu
On Site
Positif
Très certainement
Plus tôt le mot-clé apparaît dans l’URL, plus il a de poids ; et plus précisement Matt Cutts, la mine d’informations de Google, a affirmé qu’un mot-clé perdait de l’importance après le 5ème mot.
Contenu
On Site
Positif
Très certainement
La densité d’apparition du mot-clé sur une page a été et reste un facteur important, tant qu’on n’en n’abuse pas.
Cette densité sert notamment à identifier correctement le sujet traité.
En fait, ce qui va importer, c’est non pas tant une forte densité qu’une densité répondant à un pourcentage raisonnable.
Contenu
On Site
Positif
Probablement
Les mots-clés dans les balises H1 sont connus pour ajouter de la pertinence, de la lisibilité et réduire le taux de rebond.
Contenu
On Site
Positif
Très certainement
La plupart du temps, les mots-clés sont mieux installés à l’avant !
Contenu
On Site
Positif
Très certainement
L’expérience montre que plus les mots-clés arrivent tôt dans les balises Title et chapitres, plus ils sont efficaces sur le positionnement.
Contenu
On Site
Positif
Probablement
Plus vous souhaitez associer des concepts ensemble, plus il va falloir les rapprocher dans votre contenu.
De même que vous séparerez le moins possible deux termes constitutifs de votre mot-clé.
Contenu
On Site
Positif
Mythe
Cette balise HTML « servant » à indiquer les mots-clés d’une page est ignorée des moteurs de recherche puisque si elle était prise en compte, elle serait sujette a bien trop d’abus.
Quand elle est remplie, c’est sûrement pour faire vivre le mythe…
Contenu
On Site
Positif
Très certainement
Insérer des mots-clés LSI, c’est identifier des mots associés à votre mot-clé pour que Google puisse trouver et confirmer le sens de votre article (et notamment écarter toute ambiguité avec d’autres sujets).
C’est aussi un signal de qualité de contenu.
Contenu
On Site
Positif
Probablement
L’un des brevets de Google affirme que :
Un document dont le contenu correspond parfaitement à tous les termes d’une requête peut recevoir un meilleur score qu’un document qui n’a qu’un terme correspondant.
Contenu
On Site
Positif
Très certainement
L’algorithme Page Layout accorde une préférence au contenu situé au dessus de la ligne de flottaison, c’est-à-dire ce qui est visible sur la page avant d’avoir à défiler vers le bas.
D’autre part, se positionner en première page de Google va de pair avec le placement du mot-clé dans les 100 premiers mots du contenu.
Contenu
On Site
Positif
Très certainement
La saillance est ce qui ressort et retient l’attention :
Les ingénieurs de Google ont compris que compter les mots-clés ne suffisait pas mais qu’un certain nombre de termes (ou sujets / entités), et la relation entre ces termes, donnaient du sens à un texte.
Les entités saillantes sont celles que le lecteur humain jugent les plus pertinentes pour un document.
Elle fait partie du Natural Language Processing, une technologie de Google qui va de plus en plus vers une compréhension précise du discours.
Contenu
On Site
Positif
Officiel
Un texte d’ancre pertinent pour vos liens internes est un outil de navigation crucial (pertinent n’étant pas synonyme d’ancre exacte).
Contenu
On Site
Positif
Très certainement
En parallèle de nos backlinks, il n’y a pas de raison que nos liens sortants ne fassent pas également bonne figure (s’ils ne le font pas, on peut être pénalisé).
Pertinence du thème et autorité sont de mise.
Contenu
On Site
Positif
Incertain
Google disposait en 2010 d’un filtre pour le niveau de lecture, mais ce n’est plus le cas.
La seule chose que l’on sait, c’est qu’il n’est pas fan des usines à contenu, dont le niveau de lecture est considéré comme bas.
Contenu
On Site
Positif
Mythe
L’impact de la réputation de l’auteur sur le positionnement, à travers des balises spécifiques, a été une expérimentation de quelques années, qui n’est plus en cours aujourd’hui.
Rien à voir par ici !
Contenu, Interaction utilisateur
On Site
Positif
Incertain
C’est un fait que Google peut différencier le contenu généré par les utilisateurs, et il est possible que le nombre de commentaires soit un indice de qualité…
Mais ce facteur semble un peu trop facile à manipuler.
Contenu
On Site
Positif
Officiel
Une table des matières comportant des liens facilite la lecture, mais pas seulement ; elle aide aussi Google à comprendre le contenu de votre page.
Elle vous permet aussi
Contenu
On Site
Positif
Officiel
L’optimisation des images envoie un fort signal de pertinence.
Il s’agit du nom de fichier, du texte alternatif, du titre, de la description et de la légende.
Contenu
On Site
Positif
Officiel
L’utilisation de divers média (images, vidéos etc.) est un fort signal de qualité du contenu.
Contenu
On Site
Négatif
Officiel
L’algorithme de Panda reconnaît facilement du contenu sans aucune originalité, même si en apparence, ce contenu couvre largement son sujet.
Contenu
Off Site
Négatif
Officiel
Google estime qu’un contenu est dépassé globalement parce qu’il est vieux.
Il semble que ce soit un facteur négatif principalement pour les requêtes labellisées « Query Deserves Freshness ».
Contenu
On Site
Négatif
Officiel
Le contenu dupliqué ou « détourné » est un facteur négatif fort, qu’il y ait ou non violation de copyright.
Google repère évidemment aussi le contenu légèrement modifié (voir les conseils sur la Search Console)
Contenu
On Site
Négatif
Officiel
C’est simple, tout contenu dupliqué subit une dévaluation.
Contenu
On Site
Négatif
Officiel
Google ne plaisante pas avec le contenu généré automatiquement !
C’est une violation des consignes aux webmasters de la Google Search Console.
Contenu
On Site
Négatif
Probablement
La traduction automatique de texte s’apparente à du contenu généré automatiquement, et c’est plutôt un mauvais présage.
« Nous appliquons les mêmes règles au contenu traduit automatiquement qu’au contenu généré automatiquement » explique Matt cutts dans cette vidéo (en conseillant d’ajouter plutôt un widget de traduction si on n’a pas le temps de traduire un contenu pour tous les marchés).
Contenu
On Site
Négatif
Très certainement
Quand une partie d’un site est accessible depuis d’autres sites grâce à un contenu dynamique, cela peut finir par ressembler à du contenu dupliqué.
On sait que le contenu dupliqué est un facteur négatif.
Contenu
On Site
Négatif
Probablement
Ce genre de contenu arrive en général parce qu’une partie d’un site ou d’un forum est un peu laissée à l’abandon.
Ce morceau-là peut subir des pénalités.
Il nécessite de faire le ménage et de reprendre la main avec des captcha, ou différentes formes de modération.
Contenu
On Site
Négatif
Probablement
Les listes sont tellement pratiques, qu’on pourrait avoir tendance à en abuser, surtout quand elles invitent à n’écrire que quelques mots… ou mots-clés.
Attention à la dévaluation.
Contenu
On Site
Négatif
Officiel
Un texte écrit sur une vidéo n’est pas accessible par Google ; le mieux est donc de le transcrire.
Contenu
On Site
Négatif
Incertain
Un contenu masqué dans un onglet ou en accordéon, qui nécessite un clic utilisateur pour être déployé, risque de ne pas être indexé par Google…
Sauf s’il est intégré dans le code source et charge en même temps que la page dans laquelle il est intégré.
Ce qui est sûr, c’est que ce contenu ne sera pas montré dans le snippet.
Contenu
On Site
Négatif
Incertain
Pour une question d’ergonomie, le contenu caché sur les mobiles ne devrait pas être défavorisé par rapport au contenu immédiatement visible.
Mais dans son Hangout de 2017, l’analyste John Mueller encourage les webmasters à rendre visible tout contenu essentiel.
Contenu
On Site
Négatif
Incertain
Une trop grosse proportion de liens dans le texte peut être le signe d’un contenu de mauvaise qualité.
Il n’y a pas de sources chez Google pour étayer cet argument, mais étant donné leurs efforts pour juger de la qualité d’un texte, ça paraît logique.
Contenu
On Site
Négatif
Très certainement
Trop de liens sortant en DoFollow font perdre du jus de référencement.
Éliminez en priorité les liens les moins justifiés parmi les sitewide, spammy, non pertinents, et sans autorité.
Contenu
On Site
Négatif
Probablement
Attention au bourrage de mots-clés, qui génère des pénalités.
Contenu
On Site
Négatif
Probablement
Le bourrage de mots-clés vaut aussi pour la balise titre, qui se contente largement de 60-70 caractères.
Contenu
On Site
Négatif
Probablement
Des balises d’en-tête denses en mots-clés sont encore un cas de bourrage de mots-clés.
Contenu
On Site
Négatif
Incertain
Eh non, la meta description n’est pas utilisée pour le positionnement.
Mais oui, il est probable qu’elle soit tout de même une source de pénalité en cas d’abus…
Contenu
On Site
Négatif
Très certainement
Répéter le même mot-clé dans une URL n’ajoute simplement pas de valeur en terme de positionnement.
Contenu
On Site
Négatif
Probablement
Pour éviter la pénalité pour bourrage de mot-clé, quelques mots descriptifs font parfaitement le job dans la balise alt.
Contenu
On Site
Négatif
Incertain
Bien que Google ne regarde pas du tout les meta mots-clés, il arrive toujours que cette balise en soit remplie.
Pour cette raison, il est possible que cela envoie tout de même un signal négatif à Google.
Contenu
On Site
Négatif
Probablement
C’est l’inverse du bourrage de mot-clé.
L’idée, c’est de rester raisonnable et pertinent dans l’utilisation de mots-clés, et globalement pertinent dans le développement d’un sujet.
Contenu
On Site
Négatif
Probablement
Comme on l’a déjà dit, la balise titre se contente largement de 60-70 caractères.
Contenu
On Site
Négatif
Probablement
Pour éviter la pénalité pour bourrage de mot-clé, quelques mots descriptifs font parfaitement le job dans la balise alt.
Contenu
On Site
Négatif
Probablement
Si quelque chose semble fonctionner, il vaut toujours mieux l’utiliser avec une certaine sobriété.
Contenu
On Site
Négatif
Très certainement
Des ancres de texte excessivement longues peuvent être pénalisées comme spammy.
Contenu
On Site
Négatif
Officiel
Ces pages quasiment identiques sont uniquement destinées à « noyer » le trafic sur une requête, mais n’ont aucun intérêt dans le but de faire remonter une page en particulier.
Contenu
On Site
Négatif
Très certainement
Google se méfie grandement des liens affiliés qui n’apportent aucune valeur supplémentaire au contenu.
Si vous avez trop de liens affiliés, Google peut regarder de plus près les signaux de qualité de votre site pour s’assurer que vous n’êtes pas un site affilié « pur » ou « sans valeur ajoutée ».
Contenu
On Site
Négatif
Officiel
Google n’apprécie pas les liens affiliés qui n’apportent pas de valeur ajoutée, et il ne sert à rien de les cacher en y ajoutant des redirections.
Trop de liens affiliés = pénalité.
Dans ce court extrait d’interview, on peut entendre Matt Cutts suggérer de mettre ces liens en nofollow en cas d’inquiétude.
Contenu
On Site
Négatif
Probablement
Des URLs trop longues sont souvent associées à du bourrage de mots-clés.
Après le 5e mot, Google dévalue l’importance des mots suivants, et scrute les signaux spammy.
Contenu
On Site
Négatif
Officiel
Le contenu plagié peut-être détecté automatiquement par Google, ou reporté par les utilisateurs.
Les répercussions peuvent être très lourdes.
Contenu
On Site
Négatif
Officiel
Le texte inséré dans les images n’est pas dévalué.
Non : il n’est tout simplement pas lu, donc pas analysé, donc pas positionné.
Par contre, la balise alt aide le moteur de recherche à comprendre de quoi il s’agit.
Contenu
On Site
Négatif
Officiel
Comme dans les images, le texte inséré dans les rich media n’est pas dévalué.
Mais il n’est tout simplement pas lu, donc pas analysé, donc pas positionné.
Contenu
On Site
Négatif
Officiel
Vous ne voulez pas avoir de backlinks toxiques sur les sites de casino ou pharmaceutiques spammy, et c’est la même chose pour vos liens sortant :
Entretenez un bon voisinage pour ne pas être défavorisé par le moteur de recherche.
Contenu
On Site
Négatif
Probablement
En soi, les liens internes nofollow sont absurdes puisqu’ils indiquent au Googlebot que vous n’avez pas confiance dans votre propre site, et que vous ne voulez pas référencer vos propres pages.
Donc, attention à la balise meta robots dans votre code source, et à ne pas y ajouter de « nofollow » qui désavouerait tous les liens d’une page.
Matt Cutts affirme qu’il ne sert à rien d’essayer de faire du « PageRank sculpting » de cette façon.
Contenu
On Site
Négatif
Officiel
Une page de résultats de recherche ne donne pas à l’utilisateur la réponse que Google souhaite à priori lui donner.
Elle donne un peu l’impression qu’il n’a pas fait son job…
Dès 2007 c’était officiel :
Google agit pour réduire l’impact de ces pages dans notre index.
Contenu
On Site
Négatif
Officiel
Le phishing ou hameçonnage est sévèrement réprimé par Google, qui propose aux utilisateurs de les aider à « éradiquer » de tels sites.

Contenu
On Site
Négatif
Très certainement
Le contenu à caractère sexuel est bloqué des résultats à partir du moment où le filtre Safe Search est activé.
Il est fort possible que Safe Search bloque également ce type de contenu, quand il est généré par un utilisateur, et apparaît sur le site « à l’insu du plein gré » du webmaster.
Contenu
On Site
Négatif
Très certainement
Selon Matt Cutts, plus les différentes langues d’un site ou d’une marque sont isolées les unes des autres (dans différents sous-domaines ou mêmes domaines), plus les lecteurs des marchés concernés y verront de la crédibilité.
La stratégie inverse n’est certainement pas appréciée du moteur de recherche.
Code, Contenu
On Site
Négatif
Officiel
La balise meta « noindex » indique concrètement à Google de ne pas indexer une page, donc son seul intérêt peut être d’aider l’orientation des visiteurs vers des pages plus pertinentes.
Code
On Site
Positif
Très certainement
L’utilisation de données structurées peut améliorer votre positionnement de plusieurs manières : entre autres, elles simplifient la compréhension de votre contenu par Google.
Code
On Site
Positif
Mythe
Google Analytics n’est pas un facteur de positionnement.
Matt Cutts le dit clairement dans cette vidéo.
Code
On Site
Positif
Mythe
Susan Moskwa & Trevor Foucher, de l’équipe Webmaster Tools de Google, ont affirmé dans un ancien Q&A du Webmaster Blog de Google que les Sitemaps n’affectaient pas directement le positionnement.
Par contre, ils peuvent aider les robots à avoir un meilleur accès à certaines URLs, à les indexer et les rendre visibles.
Code
On Site
Positif
Mythe
C’est un conseil que l’on retrouve disséminé ça et là, mais Google ainsi que la pratique ont largement démenti (voir la vidéo ci-dessous de Matt Cutts) cette possibilité, à savoir que l’utilisation d’AdSense aurait un impact positif sur le référencement naturel.
Code
On Site
Positif
Mythe
Le placement de mots-clés dans les commentaires des feuilles de style CSS ou JavaScript est une vieille théorie SEO qui ne survit pas à la pratique.
Code
On Site
Positif
Incertain
Une page est constituée de texte et divers éléments visuels et structurants, sous-tendus par un code plus ou moins fourni.
ce code est fourni, plus il y a un risque d’affecter la vitesse de chargement ou de commettre des erreurs.
Ce n’est donc pas un facteur direct mais une bonne chose à surveiller.
Le rapport conseillé entre la quantité de texte visible et la quantité de code HTML est de 25% (voir le wiki de Ryte).
Code
On Site
Positif
Incertain
Google regarde les adresses IP et les domaines de premier niveau, mais pas vraiment la balise geo.position pour déterminer une pertinence géographique.
SAUF éventuellement pour favoriser une certaine localisation quand le domaine est générique.
Code
On Site
Positif
Mythe
Comme l’a affirmé l’analyste John Mueller dans un hangout, « Nous n’utilisons pas le contenu que nous voyons dans les sondages comme un facteur de positionnement. »
Utiliser schema.org ou un autre système de notation pour afficher des étoiles n’affectera pas votre positionnement dans les résultats organiques classiques.
Quoi qu’il en soit, ils ont une influence sur d’autres sites comme Amazon, ET sur le référencement local.
Code
On Site
Positif
Officiel
L’algorithme « Mobilegeddon » en 2015 a rendu prioritaire sur les appareils mobiles tous les sites optimisés pour les smartphones.
Ce facteur n’est pas prêt de perdre de l’importance.
Code
On Site
Positif
Mythe
L’utilisation de la Google Search Console (anciennement Webmaster Tools) n’est pas davantage un facteur que Google Analytics.
Code
On Site
Positif
Incertain
À travers le code source, cette balise indique à Google quelle page est l’originale comparée aux pages dont le contenu est dupliqué.
Elle peut vous aider à empêcher Google de vous pénaliser pour ce contenu.
Les pages dupliquées doivent elles-mêmes contenir une balise <link> pointant vers la page « canonical ».
Code
On Site
Positif
Mythe
L’impact de la réputation de l’auteur sur le positionnement, à travers des balises spécifiques, a été une expérimentation de quelques années, qui n’est plus en cours aujourd’hui.
L’utilisation de cette balise n’a donc plus d’intérêt sur le référencement.
Code
On Site
Positif
Mythe
Cette balise est assez similaire à rel= »author ».
L’impact de la réputation de l’auteur sur le positionnement, à travers ces balises spécifiques, a été une expérimentation de quelques années, qui n’est plus en cours aujourd’hui.
L’utilisation de ces balise n’a plus d’intérêt sur le référencement.
Code
On Site
Positif
Mythe
Placer des mots-clés dans le code source sera ignoré par Google et a le potentiel de ralentir le chargement de vos pages…
Code
On Site
Positif
Mythe
Il ne sert à rien de placer des mots-clés dans ces attributs HTML qui servent à appliquer des styles CSS à des éléments choisis.
Code
On Site
Positif
Incertain
L’ordre des mots dans les balises d’en-tête semble, comme ailleurs, avoir un impact sur la prise en compte des mots-clés.
Code
On Site
Positif
Officiel
La balise title doit contenir le mot-clé, c’est un facteur considéré comme crucial, et une pratique généralisée dans le monde du SEO.
Plus la balise est courte, plus les mots ont d’importance.
Il semble qu’une balise title riche en mots-clés soit un « ticket d’entrée » pour accéder à la première page.
Cependant, une fois que vous êtes sur la première page, utiliser le mot-clé exact ne semble pas vous faire remonter dans le classement.
C’est là que les autres facteurs jouent un rôle important.
Code
On Site
Négatif
Incertain
Le contenu JavaScript n’est pas censé être lisible par les moteurs de recherche mais les robots Google le crawlent quand même.
Dans certains cas extrêmes, si JavaScript est utilisé pour dissimuler du texte HTML, il y a un risque de pénalité.
Cf. la Search Console sur les techniques de dissimulation.
Code
On Site
Négatif
Officiel
Si votre texte est de la même couleur que votre arrière-plan, cela peut évidemment être interprété comme du « cloaking » (une technique de dissimulation qui montre à l’utilisateur un autre contenu qu’au moteur de recherche).
Bien sûr, il peut arriver que ce contenu soit tout de même visible par l’utilisateur, par exemple s’il est devant une image.
Mais même si l’algorithme Page Layout est censé prévenir une mauvaise interprétation, il existe des erreurs qui peuvent mener à des pénalités.
Voir aussi la Search Console sur le texte caché.
Code
On Site
Négatif
Officiel
Les ancres de liens vides s’apparentent à du cloaking.
C’est donc vite interprété comme du spam.
Code
On Site
Négatif
Officiel
Les liens internes cassés sont le signe d’un site de mauvaise qualité, et dévaluent l’expérience utilisateur (voir l’article de SEMrush).
Code
On Site
Négatif
Très certainement
Il vaut mieux éviter l’indexation d’un contenu dynamique (tel qu’un calendrier, un catalogue, etc.), parce que celui-ci est laborieux à analyser par le Googlebot.
Code
On Site
Négatif
Très certainement
L’algorithme Page Layout ne mentionne pas les pop-ups mais dévalorise tout ce qui entrave l’accès au contenu.
D’autre part, les efforts générés par Google pour améliorer l’expérience mobile sont un autre indicatif de la mauvaise tolérance des pop-ups intrusifs.
Des efforts sont faits pour tolérer les contenus non publicitaires (interstitiels « légaux », comme les appelle John Mueller).
Code
On Site
Négatif
Officiel
Les redirections trompeuses par balise Meta Refresh ou JavaScript s’apparentent à du cloaking (ici, une dissimulation de contenu via des pages satellites), et exposent à une pénalité, voire même à une suppression de l’indexation.
Code
On Site
Négatif
Très certainement
L’usage d’HTML invalide n’est pas un facteur direct mais John Mueller lui-même a affirmé que cela avait un impact négatif indirect.
Cela rend la tâche plus difficile aux robots, les données structurées sont mal prises en compte et la relation mobile / desktop est affectée.
Code
On Site
Négatif
Incertain
Les erreurs de code dégradent l’expérience utilisateur, et peuvent éventuellement empêcher Google d’analyser correctement le contenu d’une page.
Code
On Site
Négatif
Incertain
L’attribut « priority » qui peut être assigné à certaines pages dans un sitemap XML a éventuellement un impact positif sur ces pages.
Cela dit, c’est tout de même improbable que Google donne un coup de pouce à une page juste parce qu’on lui demande.
Par contre, ce qui est possible, c’est qu’il rende moins prioritaire du contenu qui ne porte pas cet attribut.
Code
On Site
Négatif
Probablement
Dissimuler du contenu CSS, c’est encore du cloaking (ce facteur négatif intervient dans de nombreuses pratiques).
Un gros appel à pénalité.
Cela peut trouver une certaine légitimité dans le cas d’onglets ou d’info-bulles.
Code
On Site
Négatif
Officiel
Les images à 1 seul pixel (ou tout autre texte minuscule) sont destinées à dissimuler des liens dans une pure ambition SEO.
C’est du cloaking, et c’est répréhensible par la loi… de Google.
Code
On Site
Négatif
Très certainement
Cela s’apparente à de la suroptimisation pour mettre en valeur certaines parties du contenu…
Et pour Google, la suroptimisation n’est jamais trop loin du spam.
Code
On Site
Négatif
Officiel
Dans le passé, les moteurs de recherchent ne pouvaient pas crawler le contenu dans les frames, qui divisent l’écran en plusieurs fenêtres.
Des progrès ont été faits mais il n’est pas sûr que ce type de contenu soit analysé correctement.
Code
On Site
Négatif
Officiel
Les pages ayant trop de publicités, et notamment au-dessus de la « ligne de flottaison », garantissent une mauvaise expérience utilisateur.
Google n’aime pas ça !
Et il surveille l’apparence et la mise en page des sites avec son algorithme Page Layout.
Code
On Site
Négatif
Officiel
Créer un fichier robots.txt au répertoire racine d’un site avec la mention « Disallow » permet de bloquer l’exploration du site par certains moteurs de recherche.
Par contre, cela n’empêche pas l’indexation de contenus (Tout sur le protocole robots.txt dans l’Aide Search Console)
Code
On Site
Négatif
Officiel
Le texte en JavaScript n’est toujours pas lu idéalement par le Googlebot.
Son référencement en est donc affecté.
Code
On Site
Négatif
Très certainement
Un site hacké peut se retrouver, le plus souvent sans le savoir, porteur de logiciels malveillants distribués aux utilisateurs.
Google dispose d’outils pour repérer ces problèmes, qui doivent être résolus immédiatement.
Il fait en sorte de protéger les utilisateurs des dangers inhérents à ces malwares et pénalise évidemment les sites le temps qu’ils agissent sur l’infection.
Code
On Site
Négatif
Très certainement
Il y a deux types d’erreurs 404.
Les erreurs « soft 404 » renvoient en réalité un code 200 selon lequel la page existe effectivement, mais qui n’ont aucun contenu.
Celles-ci sont crawlées et font perdre du jus de référencement (voir le site Web Rank Info à ce sujet).
Code
On Site
Négatif
Mythe
Oui, la Google Search Console conseille aux webmasters d’ajouter un fichier robots.txt à leur site, mais non, ce n’est pas un facteur de référencement.
Si vous ne souhaitez pas désindexer des pages, alors ce fichier n’est même pas particulièrement souhaitable.
Code
On Site
Négatif
Incertain
La balise <changefreq> dans la Sitemap donne au moteur de recherche une « fréquence probable de modification de la page ».
Comme l’indique le site officiel, c’est une « indication et non une commande » pour le crawl.
S’il y a une prise en compte approximative, la fréquence d’exploration risque d’être moins importante que la fréquence indiquée.
Autorité
Off Site
Positif
Incertain
Les signaux sociaux (partages, etc.) ne sont pas directement évalués par Google.
Cela ne veut pas dire qu’ils n’ont pas un impact indirect sur le trafic et même sur le PageRank via la génération de liens.
Autorité
Off Site
Positif
Incertain
Les partages sont effectivement un signe de popularité, donc plus généralement d’autorité.
Mais actuellement, il semble que les algorithmes ne prennent pas en compte ce genre de signaux.
Autorité
Off Site
Positif
Incertain
Les partages sont effectivement un signe de popularité, donc plus généralement d’autorité.
Mais actuellement, il semble que les algorithmes ne prennent pas en compte ce genre de signaux.
Autorité
Off Site
Positif
Mythe
Le MozRank, semblable à la métrique autrefois fournie par la barre d’outils de Google et à l’algorithme PageRank toujours en place, n’utilise pas les mêmes données que Google, et n’influence pas non plus le moteur de recherche.
Autorité
On Site
Positif
Incertain
En plus d’être une marque de légitimité, votre numéro de téléphone fait partie du NAP (Name, Address, Phone Number) que vous voudrez voir cité au maximum dans une campagne de référencement local.
Autorité
On Site
Positif
Probablement
Comme votre numéro de téléphone, votre adresse physique est une marque de légitimité.
Elle fait partie du NAP (Name, Address, Phone Number) que vous voudrez voir cité au maximum dans une campagne de référencement local.
Autorité, Signaux relatifs à la marque
Off Site
Positif
Mythe
Les citations NAP (Name, Address, Phone Number), dénuées de backlinks, sont un facteur important du SEO local.
Il a été théorisé que les citations de marque pourraient comparablement affecter le référencement naturel classique.
Le fait est que cela n’a jamais été vérifié.
Autorité
Off Site
Négatif
Officiel
Ce facteur vient directement de l’algorithme PageRank, qui évalue les pages principalement en fonction des liens entrants et sortants et du trafic associé.
Chaque page bénéficie d’une autorité globale et avec chaque lien, elle passe un peu de cette autorité.
Plus elle en passe, plus l’autorité est divisée entre les différents liens.
Matt Cutts a nuancé cet effet en 2013 en rappelant que le nombre de liens que l’on pouvait s’autoriser à placer était en fort rapport avec la valeur ajoutée du contenu.
Autorité
Off Site
Négatif
Officiel
L’autorité de domaine n’existe pas officiellement chez Google, mais c’est une métrique calculée par Moz (qui l’a inventée), Ahrefs, etc.
Quoi qu’il en soit, le domaine peut être globalement affecté par la dilution d’autorité de ses pages.
Autorité, Autre, Pertinence, Qualité
Off Site
Négatif
Officiel
Avec l’outil Paramètres URL de la Google Search Console vous pouvez indiquer aux robots de ne pas crawler certains paramètres / variations d’URL, qui peuvent s’apparenter à du contenu dupliqué et qui ne sont pas importants.
Mais voici ce que le centre d’aide résume très bien :
Si vous utilisez cet outil de manière inappropriée, Google risque d’ignorer des pages importantes sur votre site, sans fournir d’avertissement ni de rapport sur les pages ignorées. (…) Si vous n’êtes pas certain de vous servir de cet outil correctement, mieux vaut ne pas l’utiliser.
Autorité, Signaux relatifs à la marque
Off Site
Positif
Incertain
En 2014, Matt Cutts affirmait assez clairement :
« Nous n’avons actuellement pas de tels signaux dans nos algorithmes de classement. »
C’est dû entre autres au caractère extrêmement fluctuant (et humain) de ces signaux.
Néanmoins, les followers Twitter ont évidemment un impact positif, indirect.
Autorité, Signaux relatifs à la marque
Off Site
Positif
Incertain
Les likes Facebook sont aussi un signal positif – qui a un impact au moins sur Facebook- et un atout dans l’interaction avec les utilisateurs.
Mais il semble que les algorithmes Google ne prennent pas en compte ce genre de signaux.
Autorité, Signaux relatifs à la marque
Off Site
Positif
Officiel
Une ancre de lien de marque est un signal aussi simple que fort pour votre marque.
Autorité, Signaux relatifs à la marque
Off Site
Positif
Officiel
Google présume que si les utilisateurs recherchent votre marque, c’est que votre site est une marque qui existe réellement.
Autorité, Signaux relatifs à la marque
Off Site
Positif
Probablement
Si certains utilisateurs associent régulièrement un mot-clé particulier à votre marque, il est possible que Google vous donne un petit coup de boost sur ce mot-clé même lorsqu’il n’est pas associé à la marque.
Autorité, Signaux relatifs à la marque
Off Site
Positif
Très certainement
Un compte indispensable puisque la plupart des entreprises en possèdent.
Autorité, Signaux relatifs à la marque
Off Site
Positif
Probablement
Si l’on compare deux comptes sur les réseaux sociaux avec le même nombre de followers, le plus crédible sera celui qui a le plus d’interactions.
La légitimité des comptes de réseaux sociaux est l’objet d’un énième brevet déposé par Google.
Backlinks
Off Site
Négatif
Très certainement
Une vélocité négative de backlinks est un signal d’ancienneté plus que de manque de qualité.
Ce brevet de 2013 indique :
En analysant l’augmentation ou la diminution du nombre de backlinks vers un document (ou une page) avec le temps, le moteur de recherche peut en retirer un signal quant à l’actualité du contenu.
Par exemple, si une telle analyse montrait une courbe en forte baisse, cela pourrait signifier que le document est vieux (plus mis à jour, moins important, supplanté par un autre, etc.).
Backlinks
Off Site
Négatif
Incertain
Google peut considérer que votre site est problématique si sur le long terme vous perdez des liens plus vite que vous n’en gagnez.
Autorité, Backlinks
Off Site
Positif
Très certainement
La rapidité de création de backlinks indique au moteur de recherche le niveau de popularité de votre site.
Et donc, cela impacte sa position sur les SERP.
Autorité, Backlinks
Off Site
Positif
Officiel
L’une des bases de PageRank :
Des backlinks venant de sites à l’autorité forte et pointant vers une page passent de l’autorité à cette page.
Autorité, Backlinks
Off Site
Positif
Officiel
Un autre basique de PageRank, toujours d’actualité :
Des backlinks venant de sites à l’autorité forte et pointant vers une page bénéficient à cette page, et globalement au domaine sur lequel elle est située.
Autorité, Backlinks
Off Site
Positif
Officiel
Oui, c’est le principe de PageRank :
Plus une page a de backlinks, plus elle est valorisée.
Sauf évidemment si ces backlinks viennent de sites toxiques.
Autorité, Backlinks
Off Site
Positif
Officiel
Vous avez compris le principe, plus des pages, et par extension un domaine, ont de backlinks de qualité, plus ce domaine gagne en autorité. Donc en positionnement.
Autorité, Backlinks
Off Site
Positif
Officiel
C’est tout simplement toujours l’un des facteurs les plus importants en SEO aujourd’hui.
Autorité, Backlinks
Off Site
Positif
Probablement
L’algorithme Hilltop laisse entendre qu’obtenir des liens de la part de pages considérées comme des pages piliers (des ressources clé, ou hubs) sur un sujet en particulier mérite un traitement de faveur.
Autorité, Backlinks
Off Site
Positif
Incertain
Bien que les liens Wikipédia sont nofollow, il semblerait qu’un lien de la part de l’encyclopédie collaborative soit un boost de crédibilité et d’autorité.
Autorité, Backlinks
Off Site
Positif
Officiel
L’autorité de la page qui pointe vers le site apporte une valeur significative.
Autorité, Backlinks
Off Site
Positif
Officiel
L’autorité d’un site en général apporte une valeur intéressante, bien que moins prépondérante que l’autorité de la page-même qui contient ce lien.
Autorité, Backlinks
Off Site
Positif
Incertain
Une théorie vraisemblable voudrait que l’ancienneté d’un domaine rentrerait en compte dans la valorisation de ses liens sortants.
Un backlink d’un domaine ancien bénéficierait de la crédibilité de celui-ci.
Autorité, Backlinks
Off Site
Positif
Mythe
Un domaine dont l’extension est en .gov n’apporte pas plus d’autorité à vos backlinks que tout autre domaine de premier niveau générique (sans relation avec un pays).
Autorité, Backlinks
Off Site
Positif
Mythe
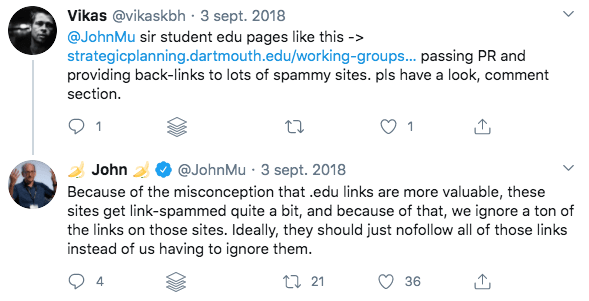
Comme pour le .gov, un domaine dont l’extension est en .edu n’apporte pas plus d’autorité à vos backlinks que tout autre domaine de premier niveau générique.
L’analyste John Mueller a même suggéré sur Twitter qu’à cause des abus, ces backlinks devraient être en nofollow.
Autorité, Backlinks
Off Site
Positif
Mythe
Une balise de lien avec attribut « data-href » n’est pas prise en compte comme un lien.
Autorité, Backlinks
Off Site
Positif
Incertain
Une page profonde reçoit davantage d’autorité via un lien direct que par un lien qui s’arrête à la page d’accueil.
Posséder de tels « liens profonds » vers des contenus spécifiques est sans doute un gage de crédibilité.
Autorité, Backlinks
Off Site
Positif
Très certainement
Les iframes d’un site intégrés sur la page d’un site tiers sont considérés comme des backlinks classiques.
Autorité, Backlinks
Off Site
Positif
Très certainement
Des sites qui partagent les mêmes 3 premiers octets d’une adresse IP sont considérés affiliés.
Posséder des backlinks d’adresses IP variées est donc le signe que vous êtes soutenu par plusieurs tiers et pas uniquement par vous-même, et peut vous valoir un bonus en tant qu’expert en vertu de l’algorithme Hilltop.
Backlinks
Off Site
Positif
Probablement
Des backlinks de sites apparaissant dans la même SERP peuvent être un signal positif.
L’important étant la valeur ajoutée, cela éviterait à tous les concurrents de se tirer dans les pattes plutôt que de collaborer.
Backlinks, Pertinence
Off Site
Positif
Officiel
Le texte d’ancre d’un backlink est un gros signal de pertinence entre une page et un terme de requête.
Cette page n’a même pas besoin d’avoir ce mot-clé dans son contenu pour bénéficier de ce signal.
Par contre, les ancres exactes sont à utiliser avec une grande modération pour ne pas être considérées comme spammy.
Backlinks, Pertinence
Off Site
Positif
Officiel
La pertinence de la relation entre vous et un site qui pointe vers vous est fondamentale.
Cela veut dire que vous devez traiter des mêmes sujets / avoir des sujets en commun.
C’est au coeur de l’algorithme Hilltop et aide à établir des communautés d’expertise.
Cela ne signifie pas que TOUS les sites pointant vers vous doivent être pertinents.
C’est à la limite du paradoxal, mais trop de pertinence paraît artificiel.
Backlinks, Pertinence
Off Site
Positif
Officiel
Les sites passent de la pertinence, et les pages le font également.
Ce brevet sur les mises à jour accorde par ailleurs de l’importance à la stabilité du sujet des pages qui pointent vers une autre page :
Un changement significatif dans l’ensemble des sujets associés à un document peut indiquer que le document a changé de propriétaire et que les signaux précédents, tels que son score, ses ancres de liens, etc, ne sont plus fiables.
La pertinence est meilleure quand elle est durable, donc.
Backlinks, Pertinence
Off Site
Positif
Officiel
Tout est dans le titre !
Si le mot-clé associé à votre page est dans le titre de la page qui pointe vers vous, c’est tout bonus.
Backlinks, Pertinence
Off Site
Positif
Probablement
Dans la logique ou la suroptimisation d’ancres exactes est considérée comme du spam, Google s’attend à des ancres variées, y compris un certain nombre d’ancres correspondant partiellement au mot-clé.
Ces ancres ont un aspect naturel.
Backlinks, Pertinence
Off Site
Positif
Officiel
Google fait de plus en plus d’efforts concrets pour parfaire son analyse du texte, et celui qui est situé autour du lien est particulièrement important.
D’où l’importance accordée aux liens « contextuels » ou éditoriaux, entre autres.
Ce brevet de 2013 stipule notamment :
Une portion de texte à gauche du lien et une portion du texte à droite du lien peuvent être analysée pour déterminer un contexte associé au lien.
Backlinks, Pertinence
Off Site
Positif
Probablement
Dans un brevet de 2003, Krishna Bharat décrit un système dans lequel posséder un backlink de la part d’un site qui est en bonne position pour une certaine requête, est avantageux pour se positionner soi-même sur cette requête.
Backlinks, Pertinence
Off Site
Positif
Très certainement
Le code pays dans le domaine de premier niveau, tel que .fr, est un signal de pertinence fort.
Il s’applique non seulement au site en question mais aussi à tous les sites qui pointent vers lui.
Backlinks, Pertinence
Off Site
Positif
Incertain
Cette théorie est une déduction faite à partir de plusieurs facteurs officiels :
On est sûr que Google utilise plusieurs façons d’analyser la pertinence géographique d’un site en fonction de la localisation des utilisateurs.
Du coup, pourquoi ne regarderait-il pas la localisation des sites qui pointent vers lui ?
Attention, on ne parle pas du fait qu’ils aient une adresse IP similaire, mais plutôt que leurs serveurs soient situés dans une même zone géographique, pays ou région.
Pertinence
Off Site
Positif
Probablement
L’attribut ALT qui correspond partiellement à un mot-clé fonctionne à peu près comme une ancre partielle.
Pertinence
Off Site
Positif
Mythe
Il ne sert à rien de remplir l’attribut « title » d’un lien avec un mot-clé si votre but est purement relatif au SEO, puisqu’il n’a tout simplement aucun impact direct sur le référencement.
En revanche il est très utile pour les utilisateurs ayant une déficience visuelle puisque les lecteurs d’écrans peuvent lire le contenu de l’attribut et ainsi aider à la compréhension du contenu.
Pertinence
On Site
Positif
Officiel
L’attribut alt d’une image sert à la décrire auprès de Google.
Il sert à la fois comme signal de pertinence, notamment pour la recherche d’Images, et comme outil d’accessibilité.
Pertinence
Off Site
Positif
Très certainement
Diverses expérimentations, notamment par Rand Fishkin de Moz, ont donné des résultats contradictoires (voir les exemples cités par Web Rank Info).
Il semblerait tout de même que le taux de clics d’une page, pour le positionnement de celle-ci sur la SERP sur une requête spécifique, ait un impact positif, au moins indirect.
Quant à Google, il n’admet pas qu’il s’agisse d’un facteur.
Interaction utilisateur, Pertinence
Off Site
Positif
Incertain
Le taux de clics fait partie des données très certainement analysées par Google pour déterminer un « quality score » organique (différent du quality score habituellement évoqué pour AdWords) appliqué aux pages en particulier et impactant le domaine en général.
Un domaine dont les pages auraient un fort taux de clics (ou « sélections utilisateur ») parmi les résultats de recherche présentés serait donc avantagé, si l’on en croit le brevet de Navneet Panda, créateur de l’algorithme éponyme.
Qualité
Off Site
Positif
Incertain
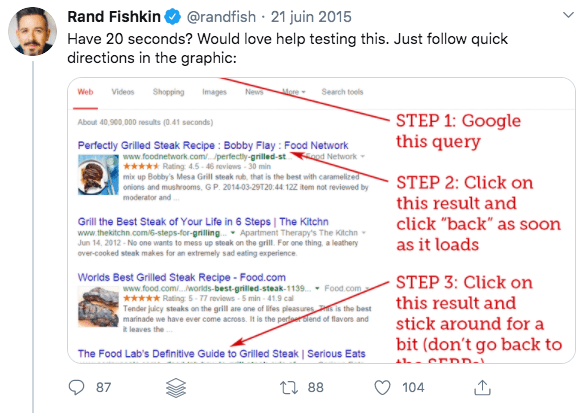
Assez similaire au « dwell time » (qui lui cible spécifiquement les retours à la page de résultats Google), le taux de rebond n’est pas censé être analysé par Google.
Cela semble effectivement facile à manipuler.
Cependant, une expérimentation menée par Rand Fishkin de Moz (voir sur Twitter) a facilement démontré que les résultats changeaient assez rapidement en jouant avec les rebonds…
Qualité
Off Site
Positif
Incertain
C’est une hypothèse qui circule (sans preuve) :
Les achats effectués en sans contact avec un téléphone Android et associés avec un compte Google pourraient être utilisés par le moteur de recherche pour lier requêtes et concrétisation d’achat.
Qualité
Off Site
Négatif
Très certainement
Si Google fait peu de cas de la positivité des commentaires dans son classement de pages (des sentiments négatifs ne prouvent pas qu’un sujet est illégitime), c’est autre chose des avis ou du texte qui concernent les marques.
Il est très probable que des sentiments globalement négatifs impactent particulièrement le classement dans le Local Pack.
À ce sujet, une étude de Moz en 2011 s’intitule « Comment les impressions négatives peuvent affecter votre classement ».
Qualité
On Site
Négatif
Très certainement
Les instructions des Google Raters indiquent que les pop-ups et les publicités gênantes sont le signe d’un site de mauvaise qualité.
Backlinks, Qualité
Off Site
Positif
Officiel
Les liens stables sont récompensés pour leur durabilité.
Pourquoi ?
Parce que comparativement, les liens spammy sont souvent modérés et donc retirés, d’autres systèmes de liens ne tiennent pas toujours la route non plus.
Certains backlinks qualitatifs expirent simplement en même temps que leur contenu.
Les liens qui restent dans le temps ont par déduction plus de légitimité et un certain poids leur est donné.
Backlinks, Qualité
Off Site
Négatif
Probablement
On sait que Google regarde le contenu qui entoure les backlinks ainsi que la qualité des pages / sites qui les contiennent.
Il est tout à fait vraisemblable qu’il s’intéresse à la qualité du contenu près d’un lien.
Backlinks, Qualité
Off Site
Négatif
Très certainement
L’examen que Google fait du contenu qui est situé à gauche et à droite des liens vaut évidemment autant pour la qualité que la pertinence.
Un manque total de pertinence peut même mener à des pénalités.
Backlinks, Qualité
Off Site
Négatif
Probablement
Les liens sitewide se retrouvent sur l’ensemble d’un site, souvent parce qu’ils sont placés en footer.
Ils ne sont pas dangereux en soi et comptent comme un seul lien.
Mais ils peuvent aussi être revus manuellement (et pénalisés en fonction de leur nature) par l’équipe anti webspam – et éventuellement automatiquement, mais c’est beaucoup moins sûr-.
Autre, Contenu
Off Site
 Variable
Officiel
Variable
Officiel
Le contenu récent bénéficie de l’algorithme « Query Deserves Freshness », mais seulement sur certaines requêtes, notamment celles qui sont liées à l’actualité.
Autre
Off Site
Variable
Très certainement
Il y a 4 types de requêtes :
Pour la plupart des recherches d’information, Google considère important, dans un souci de fiabilité, que des sources soient fournies.
Les Google Quality Raters notamment sont mandatés pour évaluer cet aspect, ce qui a pour effet final de retravailler l’algorithme.
Autre
Off Site
Variable
Très certainement
Le contenu ancien peut répondre positivement à l’un des brevets de Google qui affirme :
Pour certaines recherches, des documents anciens seront plus adaptés que d’autres plus récents.
Concrètement, un résultat de recherche peut être classifié en fonction de l’âge moyen des documents qui le constituent.
Autre
Off Site
Variable
Très certainement
« Query Deserves Diversity » ou « la requête mérite du contenu diversifié » est un attribut donné (c’est en tout cas la théorie de Rand Fishkin chez Moz) à certaines requêtes qui peuvent comporter une ambiguité, notamment sémantique.
Cette ambiguité peut aussi être située dans (ou liée à) l’objectif de la recherche (de navigation, d’information ou transactionnelle).
Ainsi Google produirait une certaine diversité dans ses SERPs, qui bénéficierait à certains sites de nature ambigüe.
Autre
Off Site
Variable
Officiel
Safe Search est un paramètre qui filtre le contenu pour adultes :
il est activé par défaut, et peut donc influencer la présence d’un site sur la SERP en fonction de son contenu.
Autre
Off Site
Positif
Mythe
Contrairement à une légende tenace, Adwords n’influence pas la position d’un site sur les résultats organiques.
Autre
Off Site
Positif
Mythe
Une autre légende voudrait que le fait de NE PAS utiliser Adwords aurait un effet positif sur le référencement naturel.
C’est un mythe.
Autre, Interaction utilisateur
Off Site
Positif
Incertain
Même si Matt Cutts a démenti cette possibilité, il existe tout de même un brevet qui stipule que le moteur de recherche peut, au cours du temps, analyser le nombre de favoris auxquels un document est associé sur Google Chrome, pour déterminer son importance.
Autre
Off Site
Variable
Incertain
Encore un facteur démenti par Google…
…mais sur lequel on peut trouver des informations contraires dans un brevet :
A savoir que les données de trafic du navigateur concernant un document en particulier peuvent être utilisées par Google pour altérer son score.
Autre, Interaction utilisateur
Off Site
Variable
Très certainement
À moins qu’un utilisateur ait désactivé ce paramètre, et sans même qu’il ait besoin d’être connecté à son compte Google, les résultats qu’il va obtenir seront personnalisés, et donc relatifs à son historique de recherche.
Autre, Interaction utilisateur
Off Site
Variable
Très certainement
Les sites que vous visitez fréquemment partent avec un avantage dans vos résultats de recherche.
Dans ce cas de figure encore, la SERP est relative à l’utilisateur lui-même.
Autre, Interaction utilisateur
Off Site
Variable
Officiel
Une recherche avec intention d’achat va générer des types de résultats différents et modifier l’apparence de la SERP : c’est par exemple le cas si Google affiche le snippet Google Flights pour une recherche de vols.
Autre, Interaction utilisateur
Off Site
Variable
Officiel
La recherche locale (avec intention géographique) modifie également l’apparence de la SERP, notamment via le Pack Local placé au-dessus des résultats organiques classiques, et ce sont des facteurs spécifiques qui entrent en jeu pour le positionnement.
Autre, Interaction utilisateur
Off Site
Variable
Officiel
Des requêtes en rapport direct avec un nom de domaine ou un nom de marque peuvent voir apparaître le même site plusieurs fois sur la même page de résultats.
Autre
On Site
Positif
Très certainement
L’utilisation d’Accelerated Mobile Pages (versions de vos pages dénudées de contenus non textuels) n’est pas un facteur direct de classement par Google.
Par contre, cela peut-être un prérequis si vous voulez vous positionner dans le Carrousel Google News.
Autre
Off Site
Positif
Mythe
Même si une théorie voudrait que Google utilise le trafic sur Chrome pour évaluer les sites, absolument rien ne suggère qu’il le fasse aussi avec Alexa.
Autre
Off Site
Positif
Très certainement
Le brevet de Nanveet Panda intitulé « Score de qualité d’un site » décrit un cas de figure dans lequel les requêtes de type « navigational » (liées à une recherche de navigation) nommant une marque en particulier contribuent au score de qualité du site (de cette marque) dans son ensemble.
Ce score est entre autres déterminé par l’action de l’utilisateur une fois la recherche effectuée (clic sur le site de la marque).
Autre
Off Site
Positif
Mythe
Aujourd’hui, en plus d’envoyer un sitemap, l’autre moyen de soumettre son site à Google est de lui demander d’explorer quelques URL.
Ça n’a pas vraiment d’intérêt :
Une demande d’exploration ne garantit pas que l’inclusion se produira instantanément.
Il se peut même que l’inclusion n’ait pas lieu.
Nos systèmes privilégient l’inclusion rapide des contenus utiles et de haute qualité.
Autre
Off Site
Positif
Officiel
Le nombre de pages que Google explore sur un site est proportionnel à l’autorité que ce site à acquise à travers ses backlinks.
C’est le « budget crawl » et celui-ci est donc plus faible si l’autorité du site est faible.
Autre
On Site
Variable
Très certainement
Si Google considère que votre site est YMYL (Your Money or Your Life, c’est-à-dire qu’il impacte la vie, la santé, la sécurité et / ou les finances des lecteurs), ses exigences de qualité sont plus hautes – vous êtes donc jugé plus sévèrement.
Vous êtes attendu au tournant sur le E-A-T (Expertise + Authority + Trust).
Autre, Interaction utilisateur
Off Site
Négatif
Très certainement
Le brevet de Nanveet Panda intitulé « Score de qualité d’un site » qui influe notamment sur les recherches relatives à une marque accompagnées d’un clic, prend aussi en compte le temps que l’utilisateur passe sur la page sélectionnée.
Il correspond à une approbation plus ou moins appuyée du résultat exploré.
S’il est court, cette approbation est faible.
Autre
Off Site
Négatif
Très certainement
Si votre site est pénalisé, il est prévisible que cette pénalité vous suive en redirigeant ce site vers un nouveau domaine via un code 301.
Le risque est encore plus grand si vous achetez un nom de domaine dans l’espoir de profiter de ses backlinks.
Autre, Interaction utilisateur
Off Site
Positif
Très certainement
Le Dwell Time Long correspond au temps passé par l’utilisateur sur la page (provenant de la SERP n°1) avant de revenir sur la SERP.
Le brevet de Nanveet Panda intitulé « Score de qualité d’un site » qui influe notamment sur les recherches relatives à une marque accompagnées d’un clic, prend aussi en compte le temps que l’utilisateur passe sur la page sélectionnée.
Il correspond à une approbation plus ou moins appuyée du résultat exploré.
S’il est long, cette approbation est bonne.
Autre, Backlinks
Off Site
Négatif
Très certainement
Des sites qui partagent les mêmes 3 premiers octets d’une adresse IP sont considérés affiliés.
Ils ne risquent pas de pénalité… jusqu’à un certain point.
Systèmes de liens
Off Site
Négatif
Officiel
Lorsque vous possédez plusieurs sites, y insérer de nombreux liens pour les interconnecter n’est pas bien vu.
Google repère ces pratiques par l’intermédiaire du nom du propriétaire du domaine, des adresses IP, des contenus et thèmes similaires…
Et vous pouvez être pénalisé (sauf s’il s’agit de sites identiques en raison de la nature internationale de votre activité).
Systèmes de liens
Off Site
Négatif
Probablement
Des textes d’ancres récents qui diffèrent, pour la même URL, en fonction des sites, peuvent éventuellement être perçus comme une manière de tester leur potentiel et, donc, de manipuler le positionnement de la page.
Systèmes de liens
Off Site
Négatif
Très certainement
Diversifier ses ancres de liens peut devenir un tel réflexe que celles-ci deviennent trop diverses, alors que l’on cherche le ratio le plus naturel possible (c’est-à-dire avec une juste proportionnalité).
Systèmes de liens
Off Site
Négatif
Probablement
C’est un classique de l’optimisation depuis 2012 :
Les textes des ancres de liens doivent suivre une logique naturelle.
Trop de texte optimisés pour matcher parfaitement un mot-clé sont le signe d’une manipulation aux yeux de l’algorithme Penguin.
La répartition idéale met en avant la marque, devant le nom du site, l’URL nue, puis le titre de la page… les ancres exactes doivent être en proportion minime.
Systèmes de liens
Off Site
Négatif
Très certainement
Avoir des backlinks sur des sites pertinents c’est bien.
Avoir quelques backlinks supplémentaires sur des sites moins pertinents, c’est idéal, parce que cela paraît plus naturel.
Il ne faut pas pousser trop loin cette logique inverse et rester dans l’état d’esprit du naturel.
Des sites ayant insisté pour avoir le maximum de liens sur les sites les plus divers possibles ont été pénalisés.
Systèmes de liens
Off Site
Négatif
Officiel
Lorsque vous créez des backlinks vous-même sur le web, vous laissez des empreintes (footprints) qui vous identifient.
Ça peut être des :
Sans parler des points communs entre sites de Réseaux de Blogs Privés (PBNs).
Le problème, c’est que Google valorise les liens qui ne viennent pas de vous, et peut voir vos empreintes comme un « système de liens ».
Systèmes de liens
Off Site
Négatif
Probablement
Comme pour les liens outbound, les liens en footer sont moins intéressants que les liens contextuels (non seulement ils ne sont pas intégrés au contenu pertinent, mais ils sont aussi loin sous la ligne de flottaison).
Ils sont également fortement associés aux liens payants et à des pratiques spammy qui attirent les pénalités.
Systèmes de liens
Off Site
Négatif
Très certainement
Les liens en en-tête ou sidebar, qu’ils soient sitewide ou non, sont dans des zones considérées « standard », n’appartenant pas au contexte d’une page en particulier, que Google va mettre de côté.
Il leur accorde significativement moins de poids au moment d’indexer le contenu d’une page.
Systèmes de liens
Off Site
Négatif
Très certainement
Après l’avoir pointé du doigt plusieurs fois, Matt Cutts a annoncé sur son blog la mort du guest blogging en 2014.
Il est clair qu’il s’attaquait surtout au pendant le plus spammy du guest blogging et cette « mort » a été largement réévaluée ensuite.
Quoi qu’il en soit, le backlink obtenu à la fin d’un article invité contribue à agiter le drapeau « spam » pour le moteur de recherche.
La pénalité n’est pas automatique, mais elle plane.
Systèmes de liens
Off Site
Négatif
Incertain
Il est fort probable qu’avoir trop de backlinks sans texte autour devient du webspam, au moins à partir d’un certain volume où ce n’est plus naturel.
Systèmes de liens
Off Site
Négatif
Très certainement
L’acquisition rapide de backlinks appelle la suspicion et la surveillance.
Ces dernières seront levées en cas de « buzz » tout à fait authentique.
Systèmes de liens
Off Site
Négatif
Probablement
Dans la même logique qu’une vélocité négative peut-être un facteur négatif, a fortiori une perte rapide de backlinks ne peut pas être un signal enchanteur pour Google.
Elle peut notamment être le résultat d’un coup de balais passé par un webmaster sur ses liens sans valeur ajoutée : pas une super publicité.
D’un autre côté, un gain rapide est carrément suspect.
Systèmes de liens
Off Site
Négatif
Incertain
Depuis l’algorithme Hilltop introduit par Krishna Bharat, les sites sont récompensés pour leurs backlinks à partir de sites pertinents.
Il faut néanmoins faire attention à la croyance dans la logique inverse, à savoir que les backlinks de sites non pertinents seraient toxiques et à désavouer (cette croyance profite à certains services).
Pour rester « naturel », il est préférable de conserver les backlinks de sites qui ne sont pas exactement comme le nôtre.
Systèmes de liens
Off Site
Négatif
Incertain
Google n’apprécie pas les liens affiliés qui n’apportent pas de valeur ajoutée, et il ne sert à rien de les cacher en y ajoutant des redirections.
Trop de liens affiliés = pénalité.
Dans ce court extrait d’interview, on peut entendre Matt Cutts suggérer de mettre ces liens en nofollow en cas d’inquiétude.
Systèmes de liens
Off Site
Négatif
Probablement
Selon le concept du mauvais voisinage pour désigner les relations entre sites pénalisés ou illégitimes, posséder des backlinks toxiques de tels sites invite à la pénalité : autant les désavouer.
Systèmes de liens
Off Site
Négatif
Mythe
Le référent SEO de Google Matt Cutts, qui est très doué pour dire aux SEOs ce qu’ils doivent faire, a affirmé que tous les backlinks devaient être contextuels (placés au sein d’un article, donc nécessairement approuvés par le webmaster).
Mais il n’est pas compliqué de se rendre compte que l’on peut obtenir des liens très profitables en dehors d’un tel contexte : il n’y a qu’à penser à certains annuaires très autoritaires.
Systèmes de liens
Off Site
Négatif
Officiel
Les liens ne peuvent pas simplement être achetés à un webmaster dans un but purement SEO.
Cela ne correspond pas aux objectifs poursuivis par le moteur de recherche :
Ces liens peuvent être reportés et réprimés.
Voir le blog officiel de la firme à ce sujet, dès 2007.
Systèmes de liens
Off Site
Négatif
Très certainement
Le spamming en commentaires vous verra vite pénalisé.
Ne parlons même pas des commentaires générés automatiquement – évitez le contenu répétitif, et les ancres de lien en mot-clé.
Pour des commentaires de qualité, qui eux sont valorisés par Google, signez de votre nom.
Systèmes de liens
Off Site
Négatif
Très certainement
C’est bien le mot « spammy » qui compte ici parce que l’impact d’un post sur un forum peut-être tout à fait positif s’il apporte de la valeur au forum.
Ce qui est certain, c’est que le moteur de recherche scrute de genre de comportement spammy.
Systèmes de liens
Off Site
Négatif
Probablement
Le contenu advertorial (advertisement + editorial… ou publireportage) est traqué par l’équipe Webspam de Google.
Il correspond à des liens payants.
Pour ne pas être épinglé pour mauvaise pratique, les liens inclus doivent être « nofollow ».
Et bien sûr, le caractère publicitaire doit impérativement être spécifié.
Systèmes de liens
Off Site
Négatif
Très certainement
Google fait la différence entre les liens ajoutés aux signatures de forum et ceux qui s’insèrent naturellement dans une discussion.
Il faut faire très attention avec cette pratique, comme avec le fait de créer une masse de profils sur les forums.
Très peu de valeur ajoutée en vue, et un risque de pénalité qui plane.
Systèmes de liens
Off Site
Négatif
Très certainement
À une époque, créer un thème (simple) WordPress et y placer un backlink en footer était un bon moyen d’obtenir des milliers de backlinks…
On connaît maintenant la valeur des backlinks en pied de page.
Mais surtout, cette technique spammy ne trompe plus personne, surtout pas Google.
Systèmes de liens
Off Site
Négatif
Très certainement
Un autre système de liens qui dans le temps semblait asssez inoffensif, consistait à coder des widgets basiques et les distribuer sur WordPress avec un backlink (il était donc généré automatiquement).
Aujourd’hui, Google n’a d’yeux que pour les backlinks qui représentent le soutien d’un tiers.
Les liens des widgets doivent donc être en nofollow et dénués d’ancre, et ne pas suivre cette règle peut poser problème.
(La source sur le Webmaster Central Blog de Google)
Systèmes de liens
Off Site
Négatif
Probablement
Une link wheel (ou roue de liens) est une sorte de réseau privé avec un nombre limité de sites.
Ils ont chacun une nature particulière qui les rend propres à pointer les uns vers les autres, dans un schéma circulaire.
Au milieu de ces entités, le site principal reçoit un maximum de liens.
À une époque, cette pratique était géniale, aujourd’hui, elle n’échappe pas aux pénalités manuelles ou même algorithmiques.
Systèmes de liens
Off Site
Négatif
Très certainement
Les répertoires d’articles, qui vous permettent de soumettre votre article de niche à un annuaire pour qu’il soit repris par un ou plusieurs site tiers, ne sont pas « illégaux » en soi.
Mais ils sont bien éloignés des objectifs de Google.
Tous les procédés associés au placement d’un article dans un répertoire d’articles tendent à l’inscrire dans la case « spammy » :
Systèmes de liens
Off Site
Négatif
Très certainement
L’annuaire web où inscrire son site est un système de liens immémorial.
Si ces liens sont payants en plus d’être génériques, sauf rares exceptions ils seront pénalisés (Matt Cutts est assez clair à ce sujet dans cette vidéo de 2011).
Comme tous les liens sur la planète, s’ils ne sont pas valorisés par leur contexte ou au moins au certain effort de sélection, ils n’ont pas un grand avenir devant eux.
Systèmes de liens
Off Site
Négatif
Probablement
Trop de liens réciproques sont le signe d’un système de liens (coups de pouce réciproques) plutôt que de liens édités naturellement.
Systèmes de liens
Off Site
Négatif
Probablement
Les réseaux de blogs privés amènent le croisement de liens à un niveau supérieur.
Chacun de ces blogs pointent vers un site principal, lui apportant de nombreux backlinks efficaces.
Ce n’est pas du black hat à proprement dit, sauf quand on commence à parler de fermes de liens.
Celles-ci sont créées dans le seul but de faire du SEO.
Google les déteste…
Et peut éliminer des réseaux entiers s’il les repère.
Systèmes de liens
Off Site
Négatif
Mythe
Construire des liens n’est pas mauvais, évidemment.
Simplement, ça devient très vite problématique quand l’intention n’est que d’influencer le moteur de recherche.
Aujourd’hui, le netlinking doit être centrée sur la valeur ajoutée (pour les humains) pour avoir une quelconque crédibilité.
Systèmes de liens
Off Site
Négatif
Mythe
Payer pour un service qui propose de créer des liens à votre place n’est pas du tout pareil que d’acheter des liens.
Cela peut être très gratifiant, quand c’est bien fait.
Par contre, certains services peuvent retourner cette technique contre vous en achetant eux-mêmes des liens.
Et vous vous retrouvez avec des liens de mauvaise qualité, sans contexte ni effort éditorial.
Systèmes de liens
Off Site
Négatif
Probablement
Les annuaires d’articles et les communiqués de presse ont été utilisés en masse, ce qui a amené Google à les considérer comme des liens artificiels appartenant à des « Systèmes de liens« .
Backlinks, Sitewide
On Site
Négatif
Mythe
Les microsites, avec leur tout petit nombre de pages et leur étendue limitée, ne sont pas pénalisés.
Par contre, ils ne bénéficient pas de facteurs « Sitewide », pourtant importants.
L’une de leur raison d’être pourrait d’être des Exact Match Domain, mais on sait que les domaines EMD n’ont pas vraiment d’intérêt à exister si ce sont des sites de mauvaise qualité.
Bref, pas de dévaluation, mais peu de chance de se positionner.
Interaction utilisateur
On Site
Négatif
Très certainement
À partir du moment où l’on considère le taux de clics (CTR, Click Through Rate) comme ayant un impact sur le positionnement, même sans être un facteur direct, il est assez logique de se dire que cette métrique est contrôlée par les services de lutte contre le spam.
L’expert Larry Kim explique dans un article très complet :
Beaucoup de gens disent que Google n’utilisera jamais le CTR pour le référencement naturel parce qu’il est « trop facile à manipuler », « c’est trop facile de frauder ».
Je ne suis pas d’accord.
Google Ads se bat contre la fraude au clic depuis 15 ans et ils peuvent facilement appliquer ce qu’ils savent faire au trafic organique.
Il y a beaucoup de moyens de détecter les clics artificiels.
Interaction utilisateur
On Site
Négatif
Incertain
Certes, il est fort possible que le volume de recherche d’une marque soit un facteur de positionnement.
Mais il existe forcément des contrôles pour prévenir le fait de rechercher abusivement sa propre marque ou celle de ses concurrents pour les étiqueter comme spammeurs.
Interaction utilisateur
On Site
Positif
Officiel
RankBrain, né en 2015, est l’algorithme d’intelligence artificielle de Google.
Il modifie l’algorithme automatiquement en fonction de son analyse de la satisfaction utilisateur vis-à-vis des résultats proposés.
Sa tâche principale est de comprendre les requêtes en profondeur (pas seulement comme une collection de mots, mais le sens de la phrase en général).
Il évalue ensuite l’interaction des internautes avec les résultats, à travers le taux de clics, le dwell time, le taux de rebond, et surtout l’exploration de plusieurs résultats jusqu’à ce que l’utilisateur trouve le bon (« pogosticking »).
Pour mettre RankBrain de notre côté, il faut donc travailler à la fois l’expérience utilisateur, ainsi que notre usage des mots-clés.
Style conversationnel, mots-clé de deux ou trois mots (de traîne « moyenne »), richesse du contenu…
Interaction utilisateur
Off Site
Positif
Très certainement
Pour une requête / un mot-clé, un boost est accordé aux pages qui ont un fort taux de clics organique sur ce mot-clé en particulier.
Interaction utilisateur, Qualité
Off Site
Positif
Très certainement
Le taux de clics d’un site en général est un signal relatif à l’approbation de ce site par les utilisateurs.
Interaction utilisateur, Qualité
Off Site
Positif
Probablement
Google utilise les données de Google Chrome pour déterminer le nombre de personnes qui visitent un site et leur fréquence de visite, etc.
Il connaît également le trafic direct (référent) et voit un lien entre ce trafic et la qualité du site.
Interaction utilisateur, Qualité
Off Site
Positif
Probablement
Le retour des visiteurs sur un site est une métrique facile à obtenir, probablement un facteur positif.
Spam Off site
Off Site
Négatif
Officiel
À une époque, la malveillance d’un tiers pratiquant le Negative SEO pouvait mener votre site à être dévalué sur Google.
Aujourd’hui, c’est pire.
Les dévaluations à cause de systèmes de liens notamment, arrivent plus vite, et les pénalités aussi : et tout ça se passe en Off page.
Surveiller backlinks, contenus dupliqués, et sa e-réputation sont quelques actions pour s’en prémunir.
Spam Off site
Off Site
Négatif
Très certainement
Un site hacké disparaît vite des SERPs…
Il faut agir vite pour contenir les tentatives de hacking et restaurer le site à partir de sauvegardes.
Il y a de quoi faire.
Vous pourrez utiliser cette liste comme référence si vous êtes à court d’idées pour remonter dans la page de résultats de Google.
Connaissez-vous d’autres facteurs ou d’autres mythes à briser que vous ne voyez pas dans cette liste ?
Dites-le moi dans les commentaires !
Bonus: cliquez ici pour recevoir mon outil de projection du trafic pour connaitre le potentiel de trafic organique de votre site pour les 12 prochains mois.
Formation SEO et stratégies de référencement
naturel avancées
Laisser un commentaire