 Savez-vous tirer profit de Google Search Console pour faire un audit SEO Technique?
Savez-vous tirer profit de Google Search Console pour faire un audit SEO Technique?
Si vous avez répondu non, ça tombe bien !
Je vais justement vous expliquer quels sont les éléments à auditer et comment les auditer dans Google Search Console.
Les tests qui vont suivre permettent de déterminer si les informations contenues sur le site sont facilement trouvables par les moteurs de recherche et par les visiteurs.
Allez c’est parti !
Avant de démarrer l’audit avec Google Search Console, vous aurez besoin de mon modèle Google Sheets.
Je vous invite à cliquer sur le lien ci-dessous.
Bonus: cliquez ici pour accéder au Modèle Google Sheets avec 207 tests pour réaliser un audit SEO technique complet.
Pour démarrer l’audit, je me rends sur le modèle d’audit technique.
Dans la colonne “Outil utilisé” sélectionnez “Google Sheets” de manière à lister seulement les tests dédiées à Google Search Console.
Comme vous le savez, Google adore les sites qui possèdent beaucoup de contenu riche et utile pour ses utilisateurs.
A l’inverse il apprécie guère les petits sites avec peu de pages…
Mais lorsque le site a beaucoup de pages de contenu, il faut tout de même être certain que Google soit au courant que tout ce super contenu existe.
C’est pour ça que ce test est crucial pour vérifier que le taux d’indexation n’est pas trop faible.
Si c’est le cas, il se pourrait bien que ça soit dû à un certain nombre de problèmes, comme par exemple:
Pour faire le test, il suffit de se rendre dans la Google Search Console et suivre ces étapes:
Dans la section Indexation, cliquez sur Pages.
Ce rapport permet de prendre connaissance des pages indexées et non indexées du site, et d’identifier d’éventuels problèmes rencontrés lors de l’indexation du site.
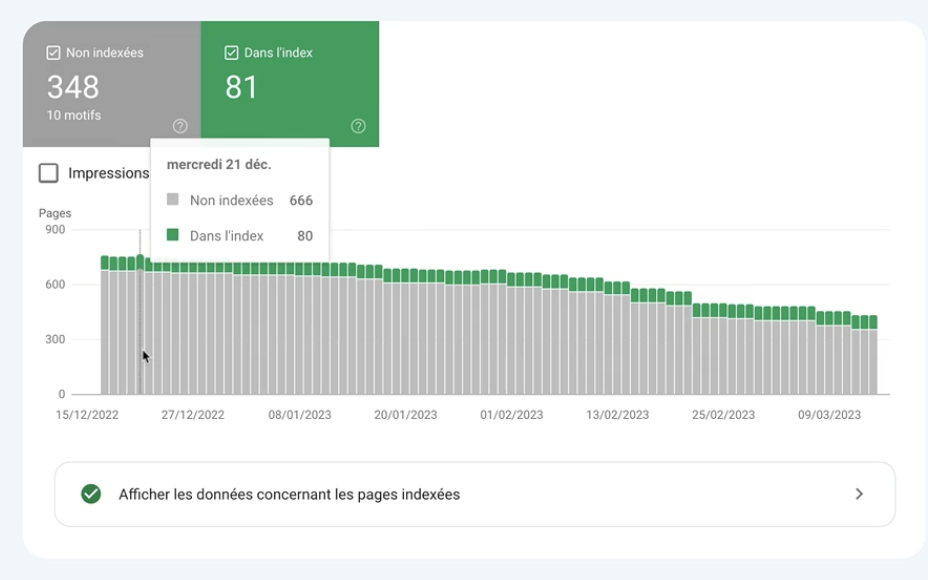
J’aime bien ce rapport car il est certes très simple, mais il permet de vérifier l’état d’indexation de toutes les URL que Google a exploré ou a tenté d’explorer sur le site.
Très rapidement, je peux donc identifier les différents états des URL du site suite aux explorations faites par Googlebot.
Dans mon cas, il y a beaucoup plus de pages non indexées que de pages indexées, donc à moi de creuser et de voir si c’est normal ou pas.
Si je désélectionne Non indexées, Je vois que la courbe des pages indexées n’augmente pas certes mais elle ne descend pas non plus.
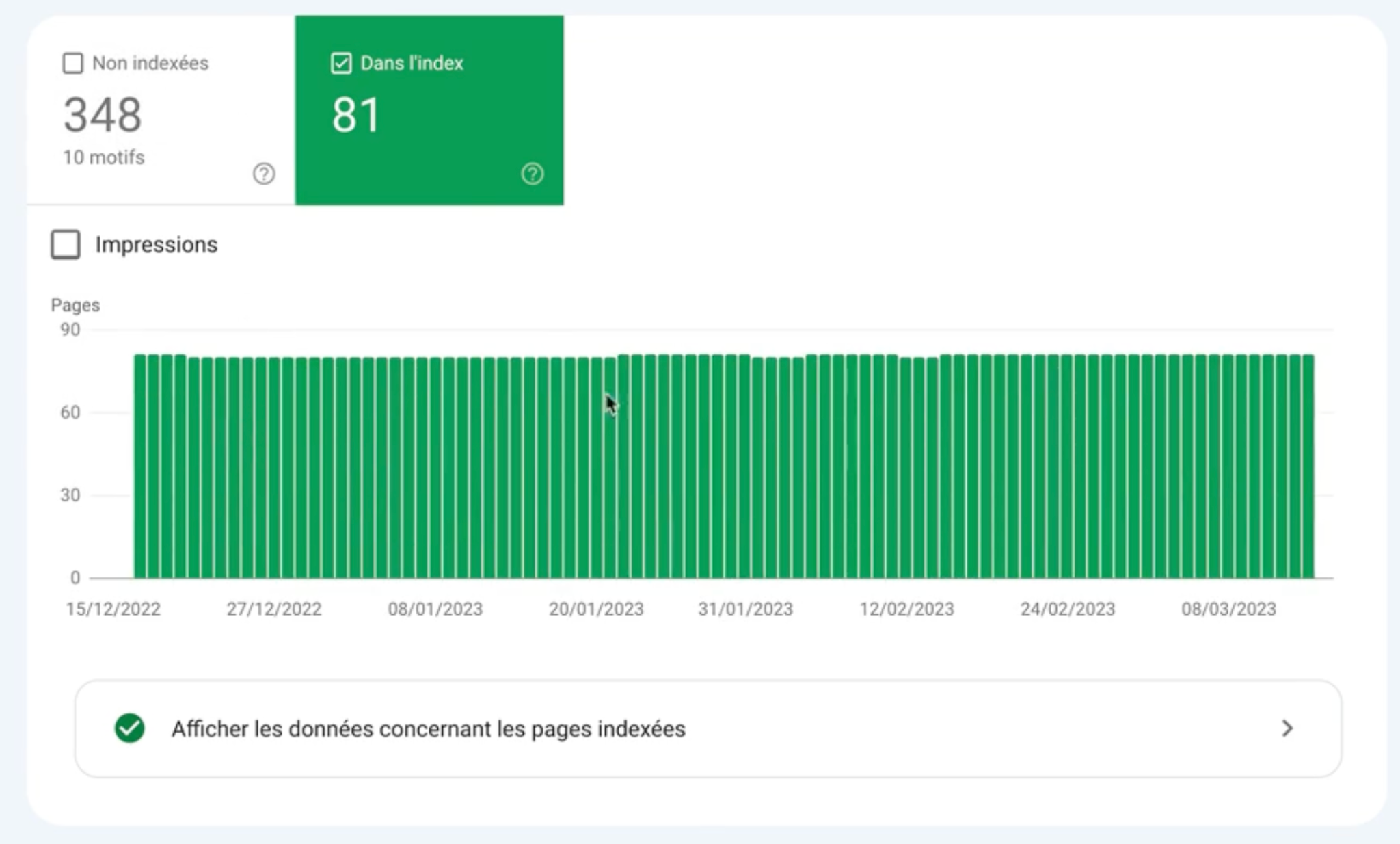
Elle stagne tout simplement parce que je produis peu de contenu récemment par manque de temps mais cela ne représente en aucun cas un problème puisque c’est logique.
Par contre, si vous auditez un site qui produit régulièrement du contenu, la courbe d’indexation (c’est-à-dire le nombre de pages indexées) doit augmenter au fil du temps si tout va bien.
Si la courbe subit des baisses, ou même des augmentations trop fortes, cela peut être dû à différents problèmes d’indexation.
Dans l’aide Google Search Console vous trouverez les problèmes les plus fréquents et des pistes sur comment les dépanner.
Je vais vérifier si les 81 pages indexées toutes sont censées l’être.
Ca va me permettre d’identifier d’éventuelles pages sans aucune valeur SEO et donc à désindexer.
Pour ça je clique sur Afficher les données que concernant les pages indexées.

Je sélectionne un affichage de 100 lignes dans mon cas, puisque j’ai 81 résultats pour ce rapport.
Puis je survole rapidement toutes les URL pour identifier d’éventuelles URL qui sont censées ne pas être indexées.
Par exemple ici je vois système SEO pas à pas. Il s’agit d’une landing page destinée à la pub Facebook, donc à exclure de l’index de Google.
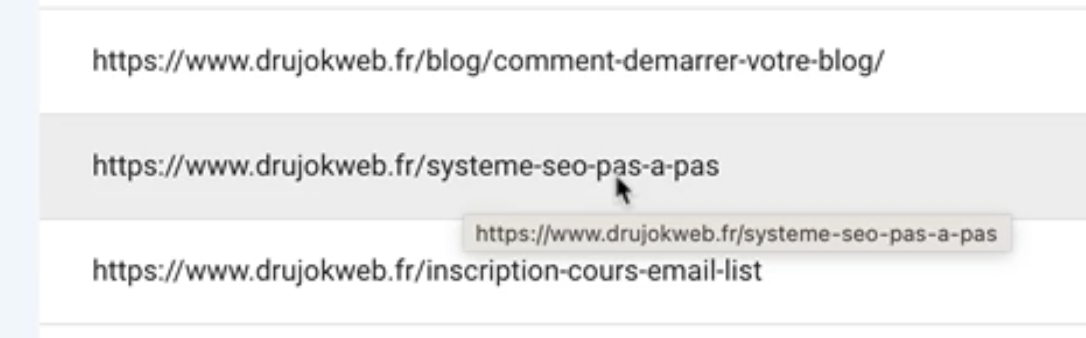
En plus je ne m’en sers plus depuis longtemps.
Je trouve également des pages de politique de confidentialité et de conditions générales de vente, c’est pareil.
Puis idem pour les pages de paiement et de réservation d’une session stratégie.
Toutes ces pages-là ne sont pas censées être indexables et donc indexées.
Même si ce n’est pas lié à l’audit technique, ça ne m’empêche pas de noter ces URL dans Google Sheets.
Ça me permettra d’y penser ou de transmettre ces recommandations aux développeurs pour ajouter une balise noindex follow ou bien pour supprimer certaines de ces pages.
En ce qui concerne notre audit technique, ce qui m’intéresse vraiment, c’est de vérifier si les 348 URL non indexées le sont de manière intentionnelle.
C’est à dire qu’il ne s’agisse pas en fait d’erreurs qui, dans ce cas, peuvent avoir un impact négatif sur le trafic du site.
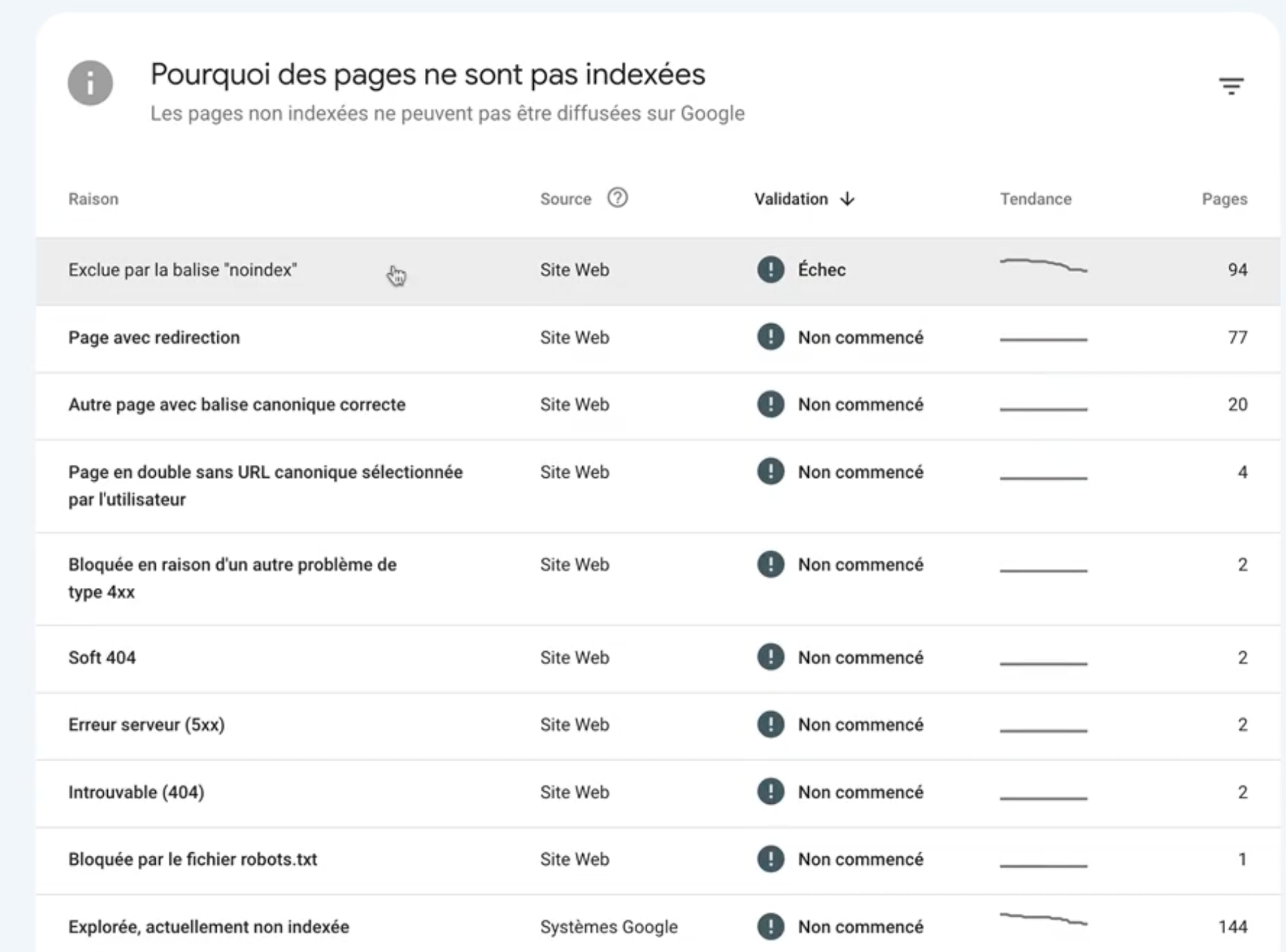
D’après le rapport, il y a 94 pages exclues de l’index parce qu’elles comportent une balise meta robots noindex…
Je clique dessus pour voir le détail, il y a des pages tags.
Je mets affichage 100 pour toutes les voir.
Il y a également des pages de type fichier joint WordPress, c’est à dire des pages qui contiennent uniquement une image, donc sans aucune valeur SEO
Pour le moment tout est normal.
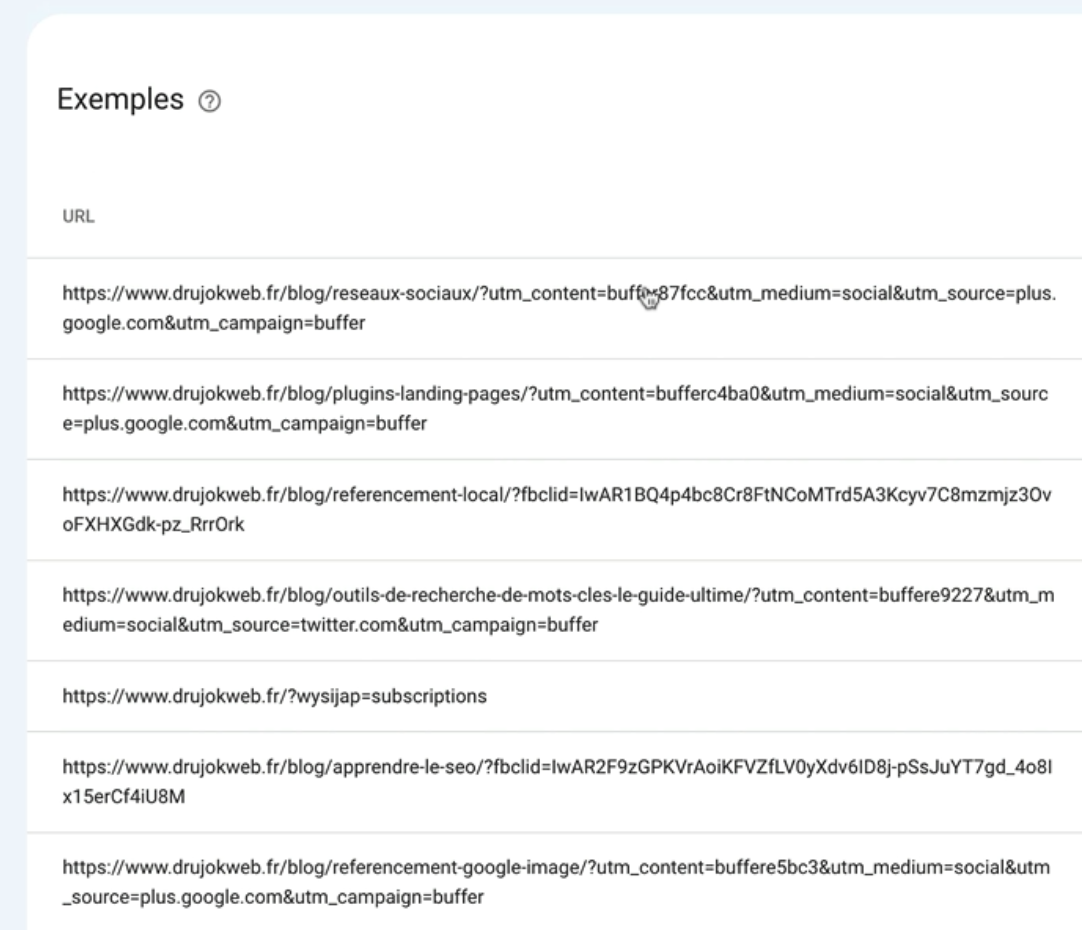
Puis il y a également des URL que j’utilise pour traquer les liens d’affiliation.
C’est principalement ces trois types d’URL que je retrouve dans le rapport.
Donc rien à signaler, tout est bon.
Si je reviens dans le tableau qui explique la raison pour laquelle ces pages sont non indexées, je vois qu’il y a également des pages avec redirection.
il y en a 77.

Je clique dessus pour jeter un œil à ces redirections.
Bon, je vais vous faire gagner du temps.
J’ai déjà vérifié et toutes ces redirections sont normales.
Donc je reviens dans mon tableau d’indexation des pages.
Prochaine raison de non-indexation identifiée dans le tableau, c’est les URL avec des balises canoniques.

Là, idem, je clique pour vérifier les détails et pour voir si toutes les URL ici sont bien non-indexables en raison d’une balise canonique utilisée par les pages en question.
Il y en a 20 et je sais déjà en parcourant ce tableau que tout est OK.
C’est tout à fait normal que ces URL soient non-indexées.
Ensuite, la prochaine raison identifié par Google Search Console, c’est page en double sans URL canonique sélectionnée par l’utilisateur.

Ici ça veut dire que Google a identifié 4 pages dans mon cas, qui sont identiques et dont aucune d’entre elles n’indique la page canonique préférée.
Du coup il a dû choisir une page sur les 4 comme URL canonique.
Je vais cliquer dessus pour avoir plus de détails et là je vois qu’il y a 3 URL qui correspondent au modèle Checklist Audit.
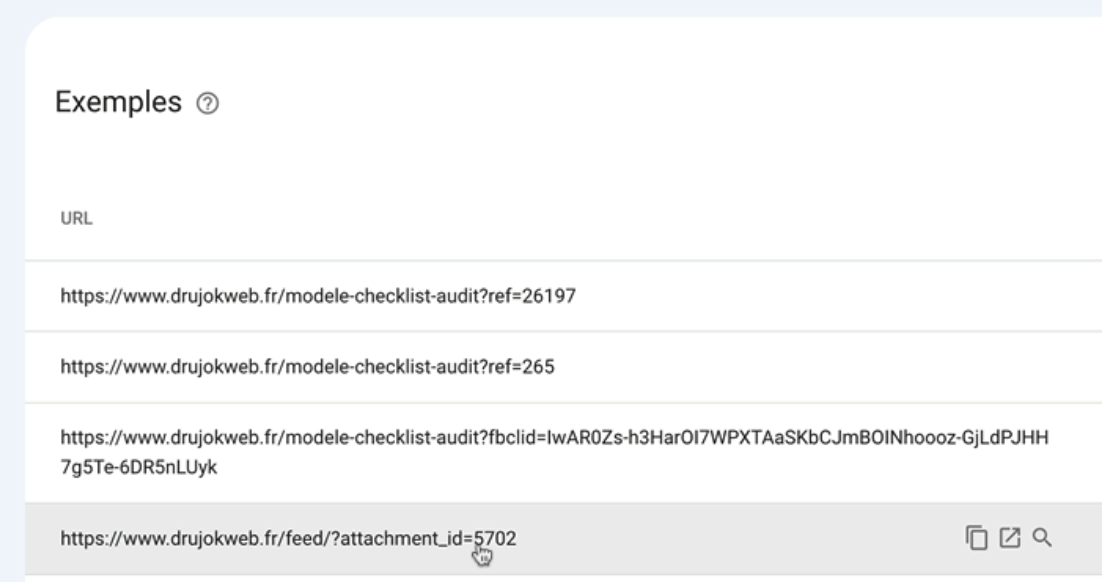
Ca veut dire que dans ce cas de figure Google a identifié ces trois url qui sont identiques visuellement mais qu’aucune de ces trois url n’indique de page canonique préférée.
Puis pour la dernière url c’est le même principe.
Donc une fois de plus il suffit que je m’assure qu’aucune de ces url soit importante.
Et dans mon cas il s’agit d’url avec des paramètres qui n’ont pas lieu d’apparaître dans l’index de Google donc tout est ok.
Bien entendu, si pendant l’analyse vous identifiez des pages qui sont censées être indexées, Il faudra bien sûr les noter dans les remarques correspondant au test.
Voici une documentation Google qui détaille toutes les raisons possibles et qui vous explique ce que ça veut dire.
Si je continue un peu, là, je vois qu’il y a une erreur soft 404.

Ça signifie que les URL en question renvoient des pages qui n’existent pas, mais dont le code réponse est 200 au lieu de 404.
Ça peut être dû à diverses raisons, comme par exemple:
Si je jette un œil à ces deux url, je vois qu’il s’agit en fait de deux pages de flux rss avec très peu de texte qui correspondent donc à des pages html vides, d’où l’erreur soft 404.
Le rapport affiche également qu’il y a des URL qui renvoient un code réponse 404 donc bien entendu non indexable.

Après vérification, il s’agit de deux pages qui n’existent plus depuis belle lurette donc RAS.
Ici il y a deux url qui déclenchent une erreur serveur 500.
Pour la première c’est normal mais pour la deuxième non puisque c’est une page qui existe donc c’est pas normal qu’elle renvoie un code 500.
Mais en y regardant de plus prêt, la dernière exploration a eu lieu le 12 février 2023…

Du coup quand c’est comme ça je clique sur la loupe pour vérifier quand même lors de l’inspection qu’il y ait toujours le même problème.
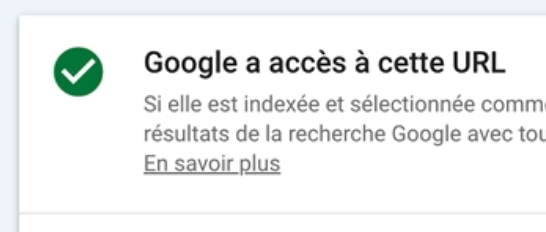
Je clique sur Tester l’url active pour voir si l’url renvoie un code réponse 500.

Et là je vois que Google a accès à cette url donc le problème a été réglé depuis.
Je vais revenir sur Index google du coup et je vais demander une indexation de cette page.
Puis une fois que ça a été fait, je clique sur Ok.
Je reviens dans mon rapport et je valide la correction.

Je retourne ensuite dans le rapport d’indexation des pages et je continue comme ça.
Bloquée par le fichier robots.txt, il n’y en a qu’une et c’est une url qui me permet de traquer les liens d’affiliation donc non indexable, donc RAS.

Ensuite on a la raison Explorée actuellement non indexée
Là il y en a 144.

Ça signifie que ces pages ont été explorées par Google mais que Google a estimé qu’elle ne valait pas le coup d’être indexées sur le moment.
Si je jette un oeil à ces 144 url une fois de plus je vois que ça termine par “feed” donc c’est des flux rss…
Après avoir parcouru toutes les URL, je constate qu’aucune d’entre elles n’a de valeur SEO.
Il faudra donc que j’essaie d’empêcher le crawl de ces pages-là à l’aide du fichier robots.txt.
A l’échelle de mon site, ça ne pose pas de problème que ces URL soient crawlées.
Mais pour un très gros site, il faut éviter que Googlebot gaspille du budget crawl en crawlant des pages qui n’ont aucun intérêt en termes de SEO.
En tout cas, en ce qui me concerne, le premier test est passé avec succès puisqu’il n’y a pas de gros problème d’indexation.
La courbe ne chute pas et toutes les pages non indexées ne sont pas censées l’être donc tout est bon.
Je mets donc Réussi et dans observations et indications en revanche je vais quand même mettre un commentaire au sujet des pages de fichiers joints wordpress puis des url concernés par les erreurs 404 et 500.
Je peux également indiquer qu’il faut mettre en place le blocage d’accès aux pages tags et de flux rss Via le fichier robots.txt.
Par exemple, désactiver la génération de fichiers joints WordPress.
Le but n’est pas de dire aux développeurs quoi faire, mais juste de faire des suggestions lorsque ça s’y prête.
Le test étant fini je peux cocher la case Terminé
Les trois prochains tests sont en rapport avec le fichier robots.txt.
Pour ça je vais utiliser l’outil de test du fichier robots.txt.
Une fois sur l’outil, il suffit de sélectionner la propriété.
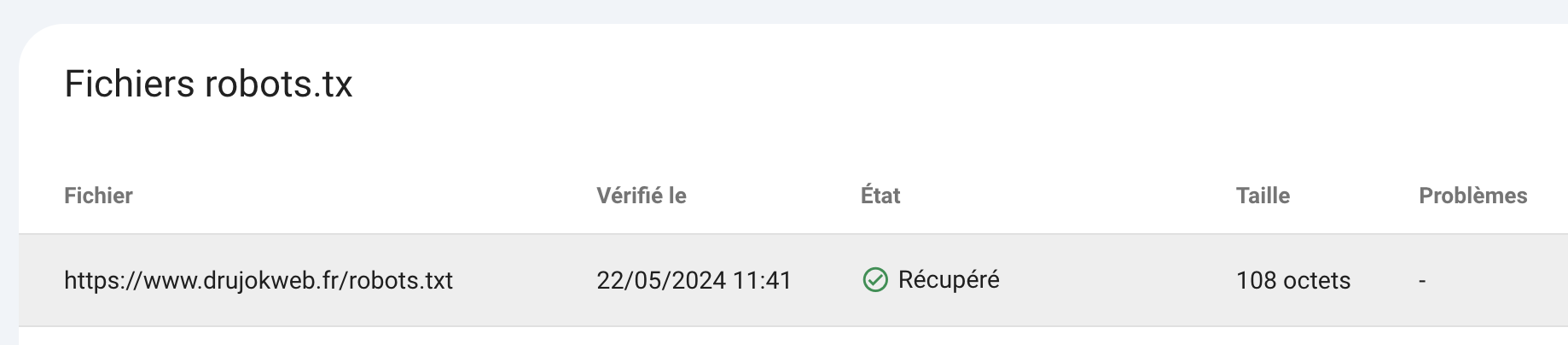
Ensuite l’outil affiche la dernière version du fichier robots.txt et les erreurs et avertissements détectés.
Dans mon cas il n’y a rien à signaler Zéro erreur, zéro avertissement.
Je retourne sur le modèle d’Audit Technique pour sélectionner « Réussi », puis je coche “Terminé”.
Les deux prochains tests se ressemblent et peuvent être effectués ensemble.
Pour vérifier ces test 3) et 4), vous pouvez retourner dans le rapport d’indexation des pages puis cliquer sur Bloquée par le fichier robots.txt s’il apparaît dans le tableau.

Dans mon cas, j’ai une URL mais comme j’ai dit plus haut, elle n’est pas censée être indexable.
Mais si vous voyez des URLs, il faudra bien entendu vérifier s’il est normal que ces URLs soient bloquées par le fichier robots.txt, tout simplement.
Dans mon cas, c’est tout à fait normal donc je retourne dans mon tableau des tests Google Sheets et j’indique que le test est Réussi puis je coche également Terminé.
Idem pour le prochain test.

On a vu que dans le rapport d’indexation des pages, tout semblait normal au niveau de l’exploration et de l’indexation.
Donc pour ma part, je vais sélectionner Réussi et Terminé.
Bien entendu, si ce n’est pas votre cas alors vous devez indiquer que le test a échoué puis noter les détails dans la colonne Remarques du modèle Google Sheets.
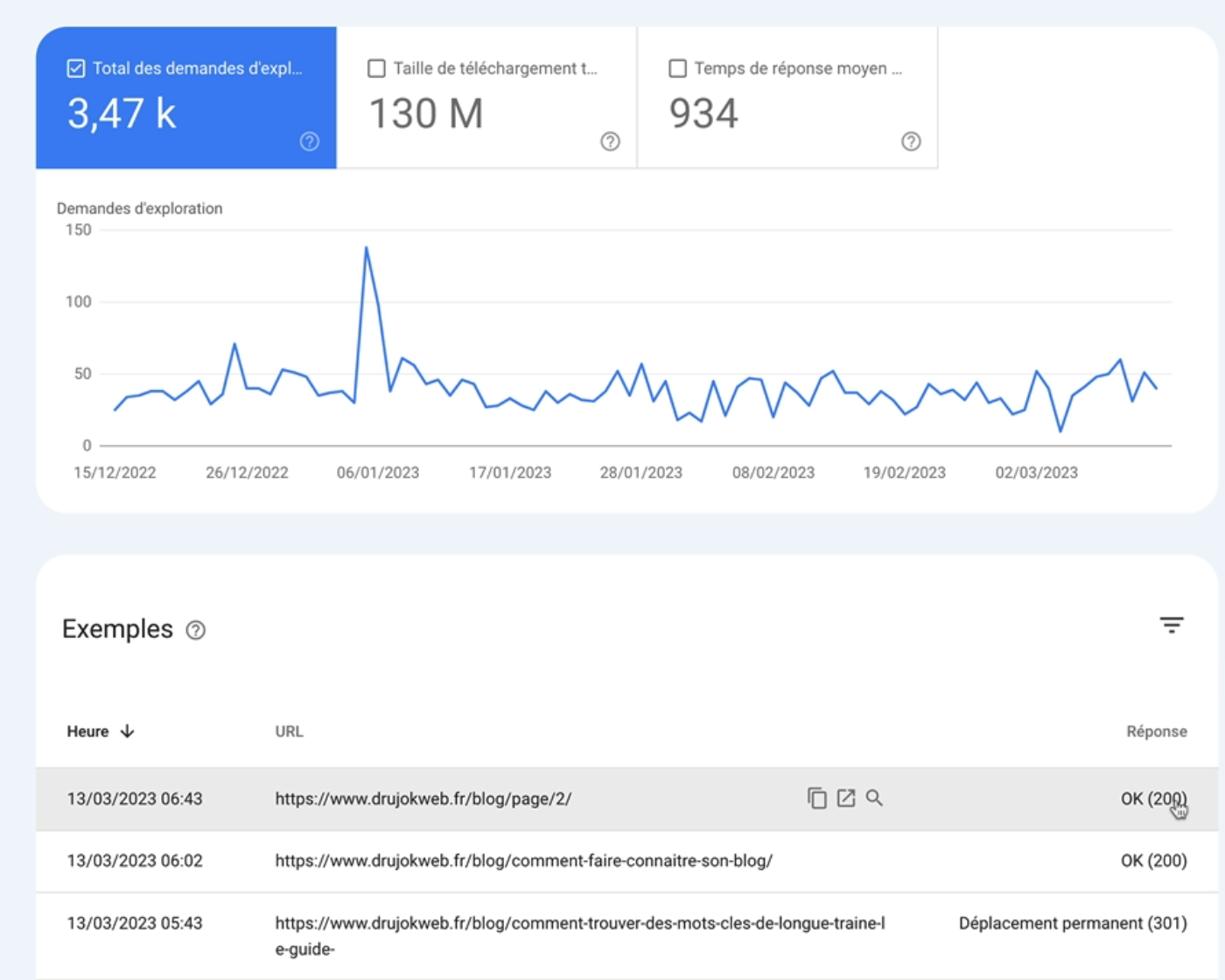
Il suffit de retourner dans Google Search Console dans Paramètres puis statistiques sur l’exploration et ouvrir le rapport.
Mon site a eu 9950 demandes d’exploration au cours des trois derniers mois.
On peut connaître également la taille de téléchargement de l’ensemble des fichiers et ressources et le temps de réponse moyen pour une demande d’exploration.
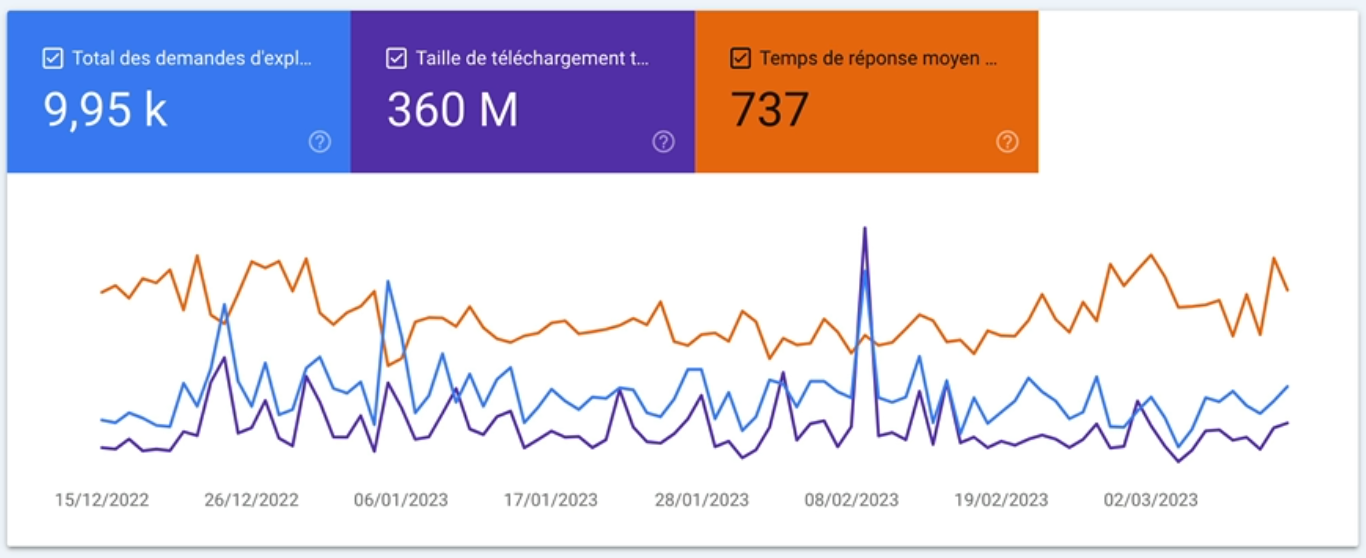
Plus concrètement, la première courbe en bleu montre le nombre de fois que le site est exploré par jour en sachant qu’une page peut être explorée plusieurs fois.
Si ces demandes d’exploration sont envoyées à des ressources qui ne sont pas hébergées sur le même serveur que celui du site, alors elles ne sont pas comptabilisées dans ce graphique.
Ça peut être le cas si Googlebot fait une demande d’exploration à des images qui sont stockées dans un CDN par exemple.
Dans l’idéal, cette courbe doit augmenter au fil du temps si vous produisez régulièrement du contenu ou elle doit au moins stagner.
Il se peut qu’il y ait de temps en temps des petits pics, comme sur mon site mais l’important c’est que globalement la tendance soit à la hausse ou du moins qu’elle ne soit pas à la baisse.
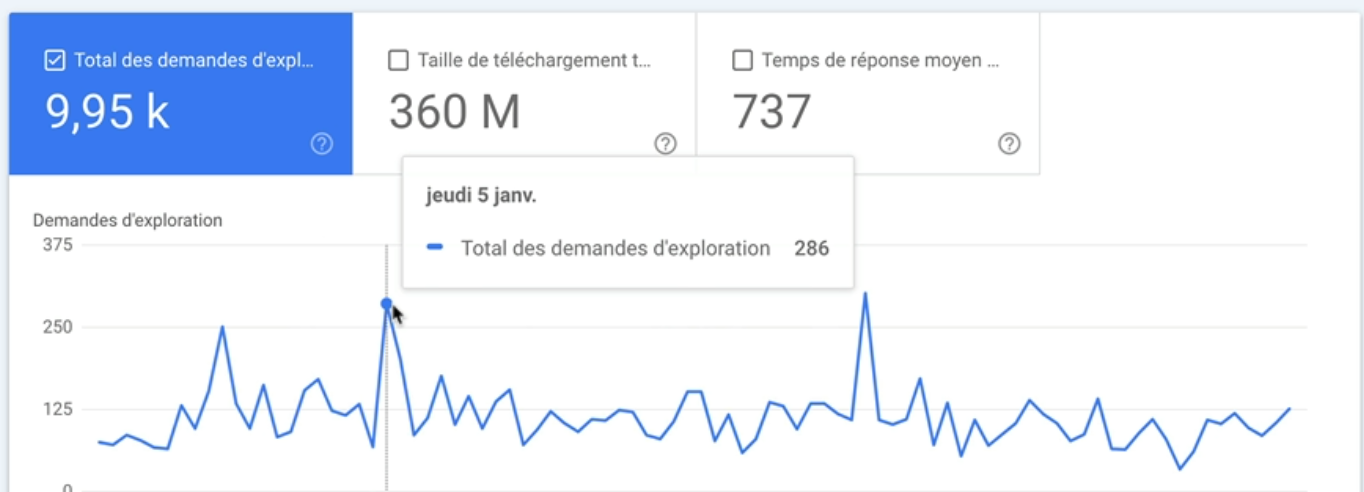
Si vous remarquez une grosse chute, il va falloir creuser pour savoir d’où provient le problème.
Parfois ça peut être causé, par exemple, par l’ajout d’un nouveau fichier robots.txt sur le site en question.
Ce qu’il est important de regarder également c’est la tendance de la troisième courbe, en orange, qui représente le temps de réponse moyen d’une page pour une demande d’exploration. C’est en millisecondes.
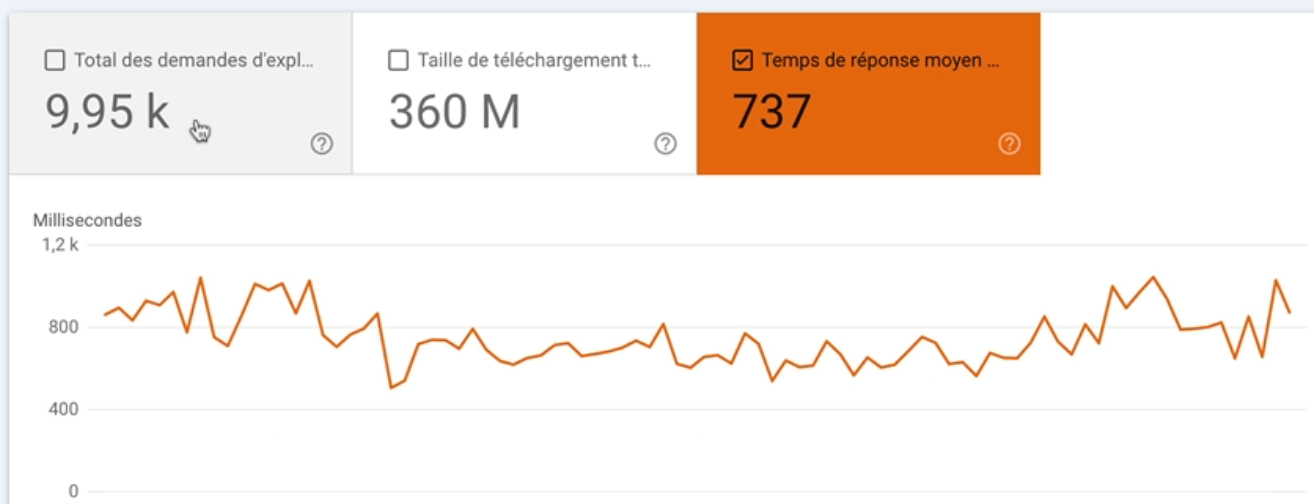
Si vous remarquez que le site répond lentement aux requêtes de Googlebot, il va falloir creuser pour comprendre d’où ça peut venir.
Par exemple, ça peut être dû à une surcharge du serveur parce qu’il a du mal à gérer toutes les demandes d’exploration, auquel cas il faut peut-être voir pour un serveur plus performant.
Idem si vous voyez que la courbe du temps de réponse suit une tendance haussière; c’est qu’il y a certainement un problème de performance du serveur.
Donc le risque c’est qu’il y ait un impact négatif sur l’expérience utilisateur mais aussi par moment sur le budget crawl pour les gros sites.
En revanche si le site ne compte que quelques milliers d’url vous n’avez aucun souci à vous faire pour le budget crawl.
Vous avez besoin de creuser un peu plus pour essayer de comprendre ce qui provoque de mauvaises statistiques d’exploration ?
Pas de panique, Google Search Console fournit les détails concernant l’hôte dans la section État de l’hôte.

Je vois que l’hôte a rencontré des problèmes précédemment mais lorsque je clique pour avoir plus de détails, il est indiqué qu’en fait Google n’a récemment plus rencontré ces problèmes.

Donc finalement tout va bien !
Je vois qu’il n’y a pas de problème au niveau de l’exploration par le fichier robots.txt.
Idem pour la résolution DNS et pour la connectivité du serveur.
Dans le passé il y avait quelques problèmes mais récemment il y a un taux d’échec acceptable donc j’en conclus ici une fois de plus qu’il n’y a pas de problème majeur.
Si lors d’un audit, vous découvrez des problèmes d’exploration, alors vous pourrez savoir si ça vient d’un de ces trois éléments.
Par exemple, il se peut que Googlebot ait rencontré des soucis lors de l’exploration du fichier robots.txt.
Si c’est le cas, vous aurez un point d’exclamation rouge à la place de l’encoche verte.
Et si vous cliquez dessus, vous aurez accès à une courbe qui montre le taux d’échec des demandes de fichiers robots.txt.
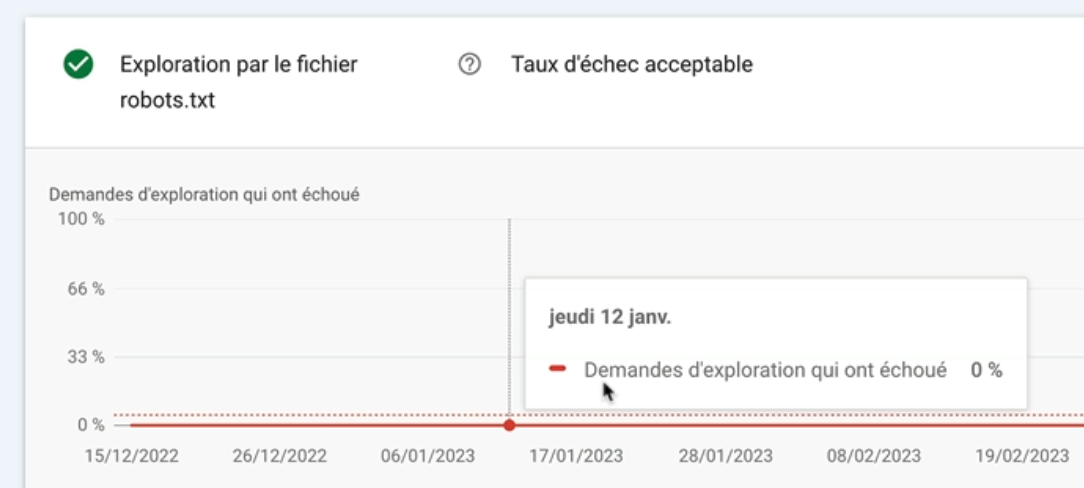
Dans mon cas, c’est 0% de moyenne.
Donc parfait.
Il faut savoir que Google demande souvent l’accès au fichier robots.txt
Si la demande ne renvoie pas de fichier valide ou de réponse 404 dans le cas où le fichier n’existe pas, ce qui est autorisé, alors Google va ralentir l’exploration du site, voire même l’arrêter jusqu’à ce qu’un fichier robots.txt soit à nouveau accessible.
Donc ce n’est pas une erreur anodine.
Voici une ressource vers des informations supplémentaires sur la disponibilité du fichier robots.txt.
Pour la résolution DNS, si je clique dessus, j’ai accès à un graphique qui m’indique à quel moment mon serveur DNS n’a pas réussi à reconnaître le nom d’hôte ou n’a pas répondu lors de l’exploration par Googlebot.
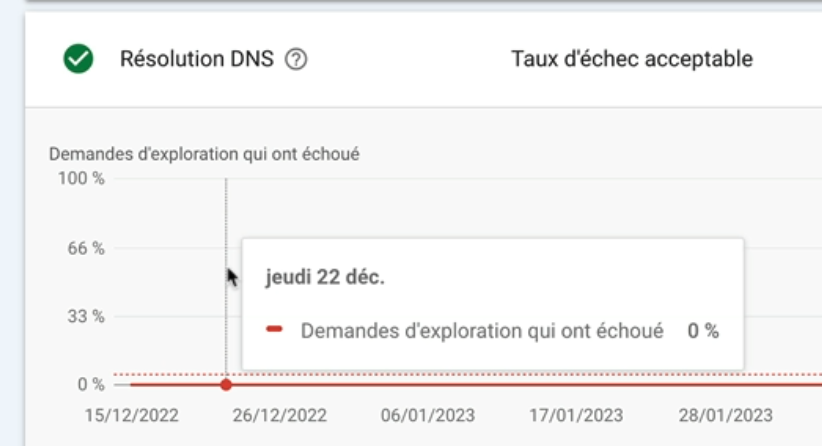
Dans mon cas, tout est OK.
Si vous rencontrez des problèmes, alors ça peut être dû à une mauvaise configuration du site ou que le serveur n’est pas connecté à Internet.
Enfin la connectivité du serveur comme j’ai dit, j’avais un petit souci dans le passé mais aujourd’hui le taux d’échec est acceptable puisqu’il est proche de zéro.
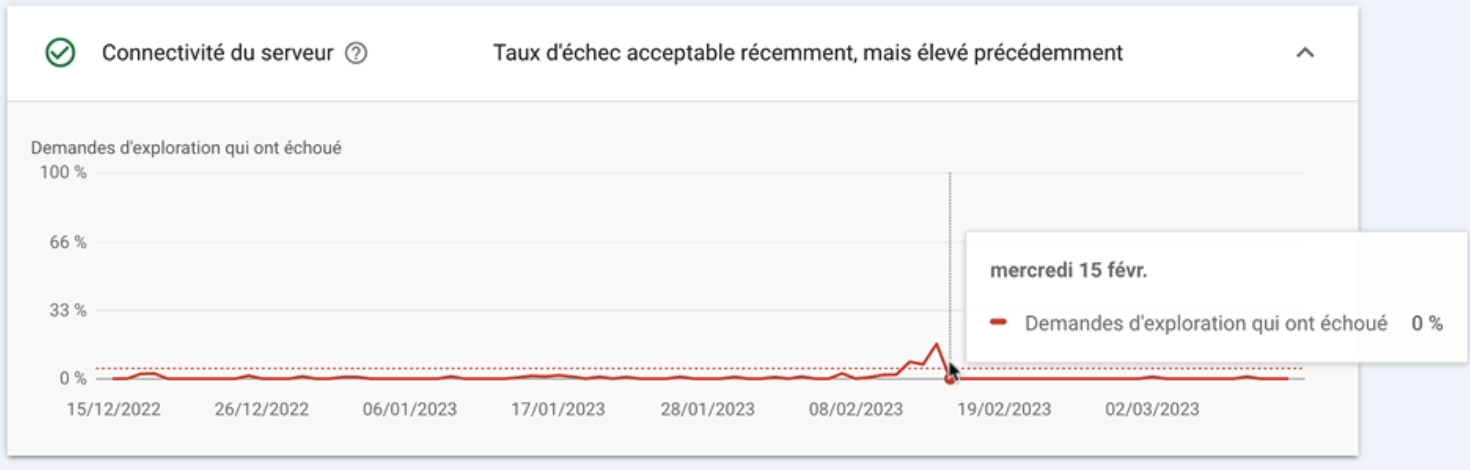
Si vous voyez des taux d’échec élevés et réguliers ça peut être dû à différentes raisons mais il faudra voir avec l’équipe technique responsable du serveur.
Peut-être qu’il s’agit d’un problème de disponibilité récente de l’hébergeur ou encore que le serveur est surchargé ou mal configuré.
Voici quelques pistes pour corriger ce problème.
Dans tous les cas, si vous constatez un ou plusieurs problèmes, il faudra vérifier les logs du serveur ou demander à un développeur de comprendre les problèmes.
Pour comprendre ce que Googlebot explore, vous avez les détails dans ce rapport par code réponse, par type de fichier, par objectif et par type de Googlebot.
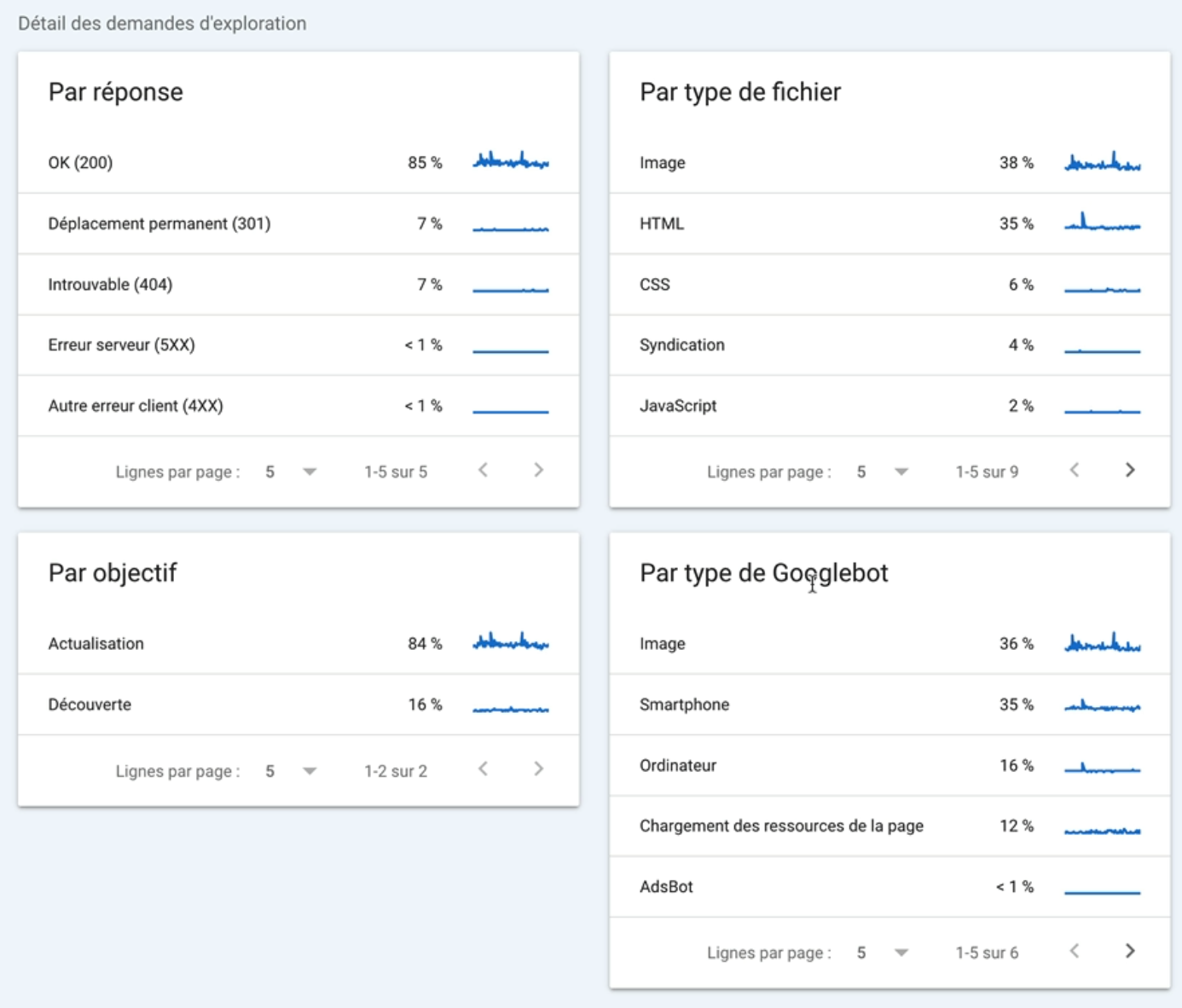
Par exemple, si je clique sur le User Agent Smartphone je peux voir:
Ça vous permet donc d’y voir beaucoup plus clair sur l’exploration du site que vous auditez par Googlebot.
Et par conséquent de mieux identifier et comprendre les éventuels problèmes rencontrés lors de l’exploration.
Je vais retourner sur le modèle d’audit technique pour indiquer que le test a une nouvelle fois réussi, puis j’indique terminer.
Cet audit Google Search Console est très utile pour identifier des problèmes qui peuvent causer un véritable gaspillage du budget crawl alloué au site.
Il existe des raisons assez fréquentes qui sont à l’origine de ce gaspillage de budget crawl.
Voici un tableau récapitulatif de ces raison et des solutions envisageables:
| Raison | Description | Solution |
|---|---|---|
| Accès aux URL contenant des paramètres | URL avec paramètres peuvent générer des quantités infinies d’URL. Utiliser robots.txt ou paramètres d’URL de la Google Search Console pour les bloquer. | Utiliser robots.txt, paramètres d’URL de la Google Search Console, ou l’instruction rel=nofollow. |
| Contenu dupliqué | Pages dupliquées, résultats de recherche internes, et pages tags. Utiliser des redirections 301 et robots.txt. | Redirections 301, rendre les pages de recherche internes inaccessibles via robots.txt, désactiver les pages générées automatiquement. |
| Contenu de mauvaise qualité | Pages avec peu de contenu ou sans valeur. Nécessité d’un audit de contenu. | Réaliser un audit de contenu, éviter les pages FAQ avec des questions ayant des liens vers des réponses sur des URL différentes. |
| Liens cassés et chaînes de redirection | Liens cassés et longues chaînes de redirection. Les supprimer pour optimiser le budget crawl. | Supprimer les liens cassés et éviter les longues chaînes de redirection. |
| URL incorrectes dans les sitemaps XML | URL de pages non indexables ou retournant des codes erreurs dans les sitemaps XML. Vérifier que seules les URL indexables sont incluses. | Vérifier que les sitemaps XML ne contiennent que des URL indexables. |
| Pages qui se chargent lentement ou pas du tout | Pages qui se chargent lentement affectent le crawl et l’expérience utilisateur. Utiliser des outils pour vérifier et améliorer le temps de chargement. | Utiliser des outils comme Pingdom, GTmetrix, Webpages test, Google Pages Speed insights pour améliorer le temps de chargement. |
| Nombre élevé de pages non indexables | Pages non indexables accessibles aux moteurs de recherche. Identifier et limiter leur quantité. | Identifier et limiter les pages non indexables lors d’un audit technique. |
| Mauvaise structure du maillage interne | Structure des liens internes non optimisée. Vérifier que les pages importantes ont beaucoup de liens internes. | Optimiser la structure des liens internes pour que les pages importantes aient beaucoup de liens pointant vers elles. |
La majorité des tests listés dans le modèle d’audit technique permettent d’identifier des problèmes qui sont un frein direct pour optimiser le budget crawl, mais également des problèmes qui ralentissent la croissance de l’autorité des pages du site.
Or, pour améliorer le budget crawl, il faut construire l’autorité des pages du site.
Donc l’audit technique et la résolution des problèmes est incontournable pour résoudre Cette problématique de budget crawl.
Passons maintenant au prochain test…
Bonus: cliquez ici pour accéder au Modèle Google Sheets avec 207 tests pour réaliser un audit SEO technique complet.
Sur ma lancée, je peux également faire le test suivant qui consiste à vérifier si la où les sitemaps possèdent des erreurs ou avertissements.
Pour ça, c’est facile.
Il suffit d’aller dans la Search Console, dans la section Indexation, et cliquer sur Sitemaps.
Dans mon cas, la sitemap a bien été envoyée à Google.
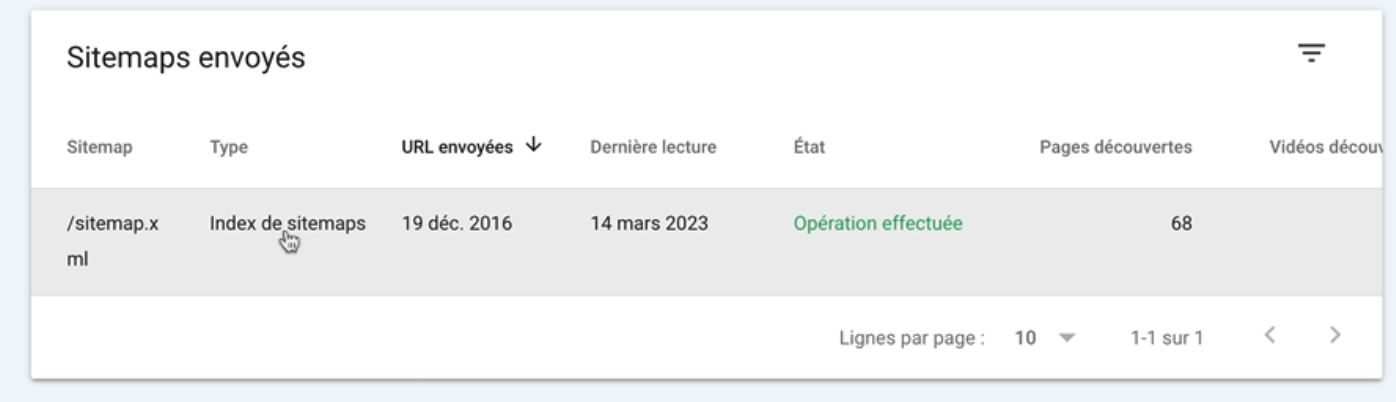
Et pour vérifier si elle contient des problèmes je vais cliquer sur les trois petits points…
Puis Voir l’indexation des pages.
Ici ça me renvoie dans le rapport d’indexation des pages mais qui est cette fois-ci spécifique à la sitemap xml.
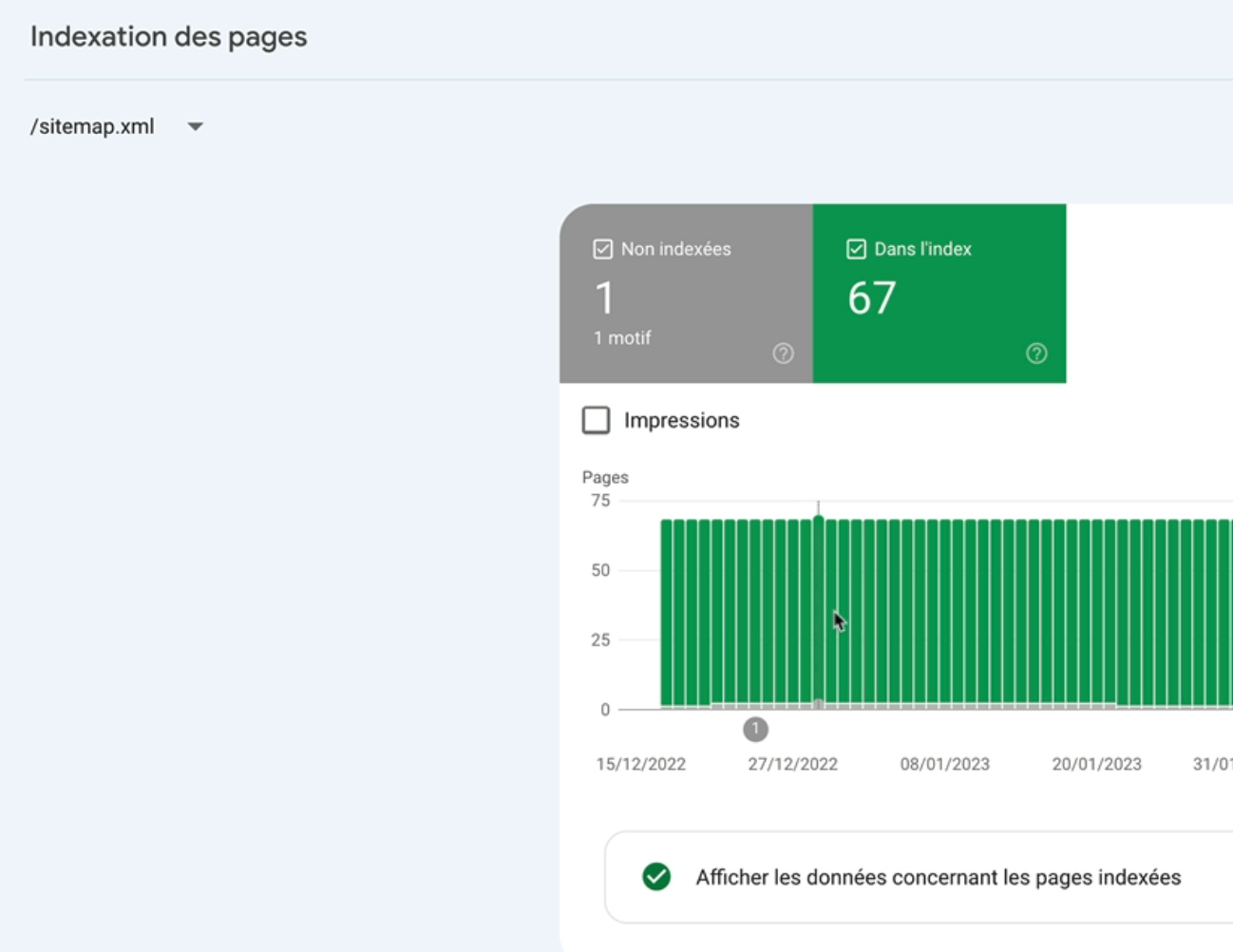
Je vois qu’il y a une URL non indexée dans la sitemap et il s’agit d’une page avec redirection.
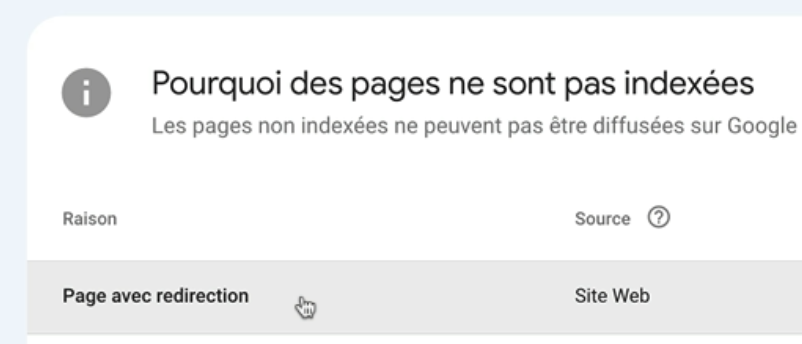
Je clique dessus pour voir à quelle page ça correspond.

En effet c’était l’ancienne URL de mon guide sur le référencement local donc vu que cette page est bien redirigée vers la nouvelle URL ici je peux supprimer cette URL de ma sitemap.
Je vais quand même vérifier si cette URL finale est bien indexée.
Pour ça je retourne à mon rapport d’indexation général, je vais mettre 100 lignes et je vérifie bien que cette URL est bien indexée.
C’est bon, c’est bien le cas, donc tout est ok.
Je vais indiquer que tout est ok pour les deux, mais je vais quand même indiquer qu’il va falloir supprimer l’ancienne URL de mon guide sur le SEO local de mon fichier sitemaps.xml.
Puisque ça ne sert à rien que cette URL soit explorée.
Je note “Supprimer de la sitemaps.xml cette URL.”
Je note ensuite que le test est Terminé.
Pour ça il suffit de regarder dans le rapport d’indexation de la sitemap s’il y a des erreurs, dans mon cas ce n’est pas le cas.
Le test est donc réussi.
Dans mon cas, je sais qu’il n’y a aucun sous-domaine, donc le test est non applicable.
Par contre, l’utilisation des sous-domaines est fréquente.
Par exemple, l’une des utilisations les plus courantes est l’hébergement de contenu, C’est-à-dire l’installation d’un blog.
Dans ce cas-là, on retrouve souvent le sous-domaine blog avec une URL qui ressemble à blog.drujokweb.fr.
Ensuite, une autre utilisation fréquente, c’est pour installer un environnement de test lors d’un développement web.
L’URL ressemble à test.drujokweb.fr.
Enfin, ça peut servir également à héberger des contenus privés, par exemple une formation pour les employés de l’entreprise.
Et dans ce cas-là, l’URL ressemble à quelque chose comme formation.drujokweb.fr.
Pour vérifier tous les sous-domaines, j’utilise un outil qui s’appelle Pentest Tools.
Je vais lancer L’outil, ensuite dans product vous allez trouver la section reconnaissance et subdomain finder
Une fois sur la page vous n’aurez plus qu’à insérer l’url du site et lancer le scan mais dans mon cas il n’y a aucun sous-domaine.
Donc le test est non applicable puisque je n’ai pas de sous-domaine.
Donc il n’y a pas de problème d’indexation.
Bon là j’ai pas besoin de vérifier c’est oui bien évidemment donc je mets Réussi et Terminé.
Bien entendu il suffit d’aller à dans Google Search Console, vérifier si la propriété correspondant au site à auditer a été créée ou non et est donc présente dans la liste.
Donc moi, c’est bien le cas.
Pour vérifier ça, il suffit d’aller dans la section Sécurité et action manuelle, puis Actions manuelles.
Donc là, on voit bien que dans mon cas, il n’y en a pas.
Il existe diverses raisons pour déclencher une action manuelle.
Pour comprendre à quoi correspond une action manuelle vous pouvez utiliser l’aide officielle de Google que je trouve très utile qui contient la liste des actions manuelles et les détails sur chaque action manuelle et les recommandations pour rectifier le tir.
Toujours est-il que dans mon cas j’en ai pas donc le test est Réussi et Terminé.
Pour mon site, il y a quatre améliorations proposées par Google.
La première, c’est FAQ.
On voit qu’il n’y a aucun problème critique, mais du coup, il n’y a aucune URL valide non plus.
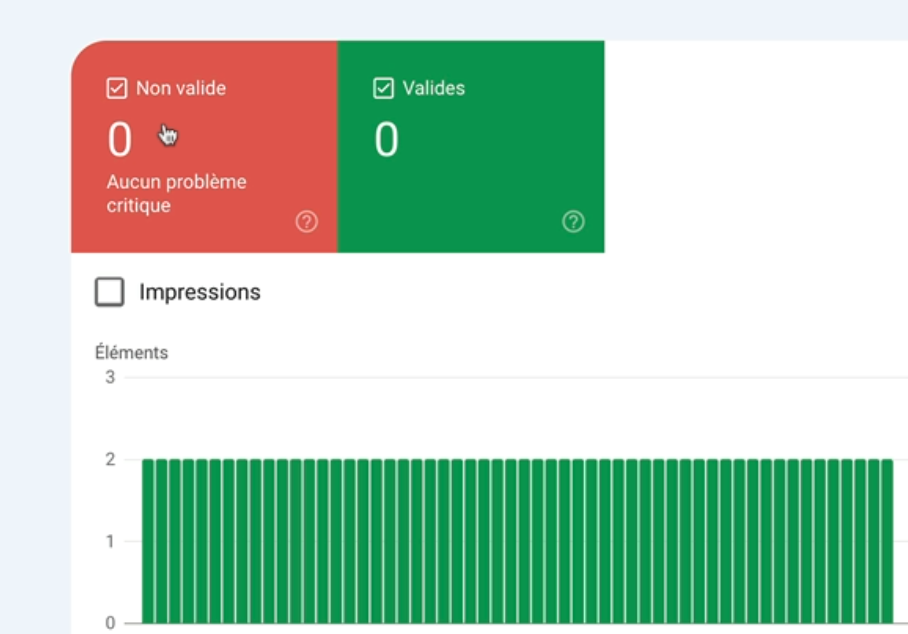
Donc en fait, il n’y a rien du tout.
Ensuite, Extrait d’avis.
“Nous n’avons pas trouvé de données”.
Donc OK.
Ça bug un petit peu des fois.
“Champ de recherche associé au lien SiteLink”.
Ici, tout est OK.
Et pareil pour la vidéo, donc dans mon cas c’est vraiment pas intéressant.
Je vais prendre le cas d’un autre site, où là par contre il y a une erreur ou plusieurs erreurs à corriger.
Là on voit qu’il y a 4 améliorations proposées:
Apparemment, pour l’amélioration sur l’extrait d’avis, l’élément n’accepte pas les avis.
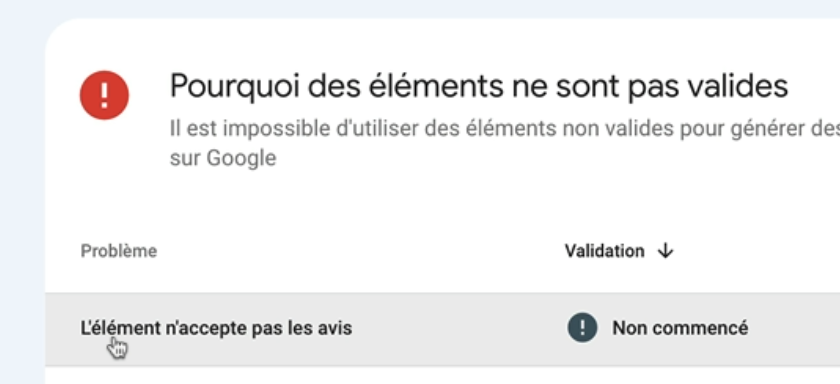
Si je clique pour voir les détails je vois qu’il s’agit de deux pages produit.
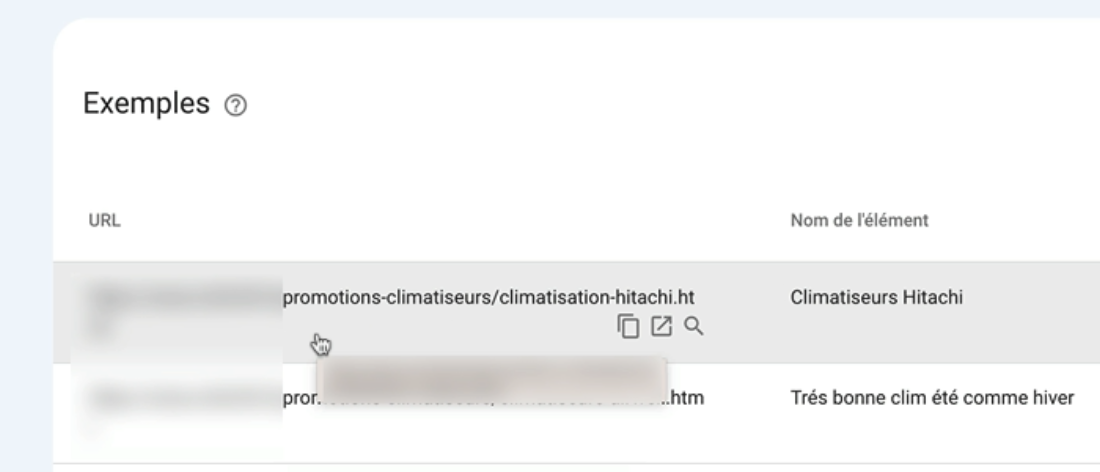
Je peux cliquer dessus pour voir la partie du code à corriger.
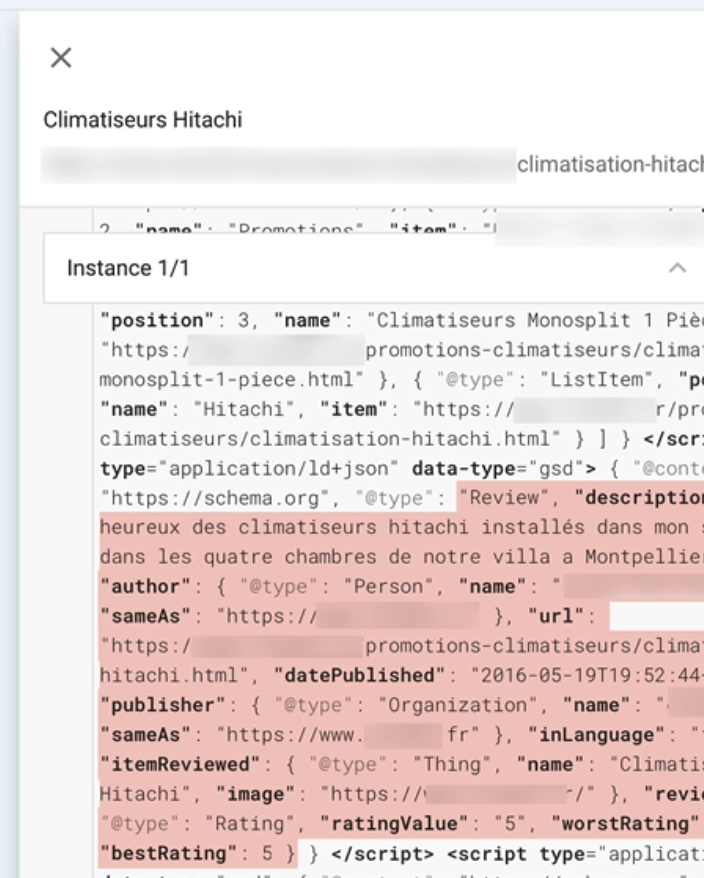
Il doit donc manquer dans ce code un élément qui permet d’afficher les avis.
Il suffit alors que je copie ce code et que je le mette dans les commentaires correspondant à ce test pour que le développeur puisse avoir une idée plus précise du problème.
Si je veux aider le développeur en lui expliquant ce qu’il faut ajouter dans le code il suffit que j’aille voir les pages valides.
Je reviens en arrière, je clique sur Afficher les données concernant les éléments valides.
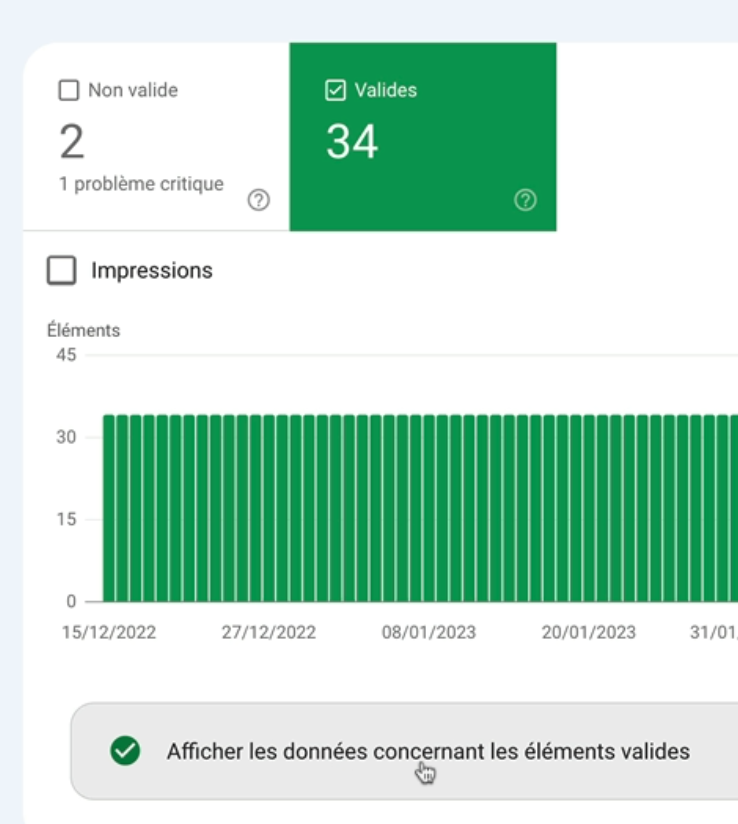
Puis je vais prendre la première URL et je vais cliquer dessus pour faire apparaître le code.
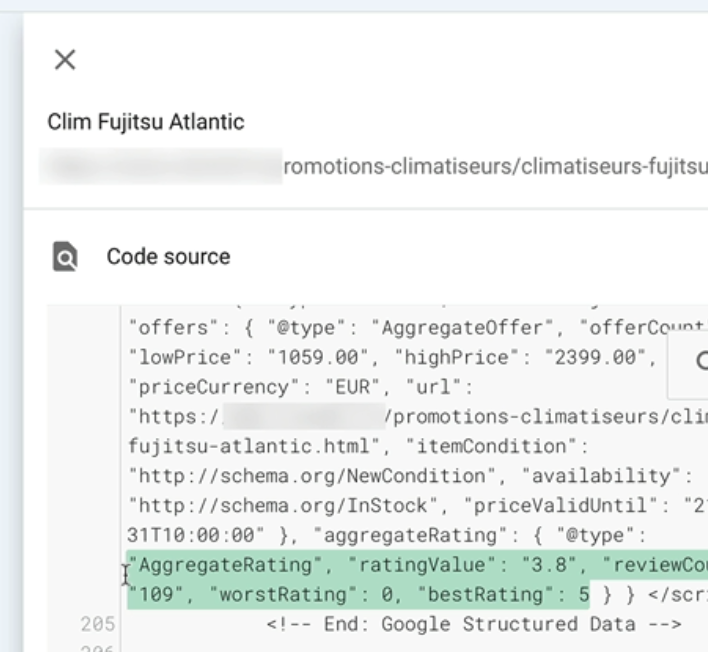
Et ici, je vois qu’en vert, Google met en surbrillance la partie en question qu’il faudrait ajouter dans le code des deux pages produit concernées par le problème.
Je n’ai plus qu’à coller ce code dans les commentaires du test.
Mais en ce qui concerne mon site, en tout cas, le test est Réussi et Terminé.
Pour ça, je vais dans Sécurité et actions manuelles, puis Problèmes de sécurité.
Aucun problème détecté, donc test Réussi encore une fois, Terminé.

C’était donc le dernier test à réaliser grâce à la Google Search Console.
A ce stade, comme vous avez pu le remarquer, je n’ai pas encore utilisé de crawler.
Il s’agit plutôt de tests à l’échelle du site et non pas à l’échelle de chaque page.
La Search Console permet ainsi d’obtenir rapidement des éléments cruciaux sur le site audité et devrait être selon moi le premier endroit où regarder.
Si vous pensez que j’ai oublié un test important à réaliser dans Google Search Console, je vous invite à me l’indiquer dans les commentaires !
Bonus: cliquez ici pour accéder au Modèle Google Sheets avec 207 tests pour réaliser un audit SEO technique complet.
D’autres guides qui pourraient vous intéresser:
Formation SEO et stratégies de référencement
naturel avancées

Merci pour ce bel article, très instructif.
J’ai une petite question : j’ai un décalage entre les infos affichées et la réalité.
Nous sommes le 31 mai, le graphique et le nombre de pages indexées date du 27 mai. Et quand je vais sur le détail de chaque page, beaucoup ont été indexées depuis. Du coup c’est compliqué de s’y retrouver… Dois-je seulement patienter ?
Autre question : au début j’avais un mauvais réglage, le site n’était pas en https. Du coup dans la liste des pages, j’en ai la moitié en http et l’autre moitié en https. Dois-je faire quelque chose en les supprimant dans Google Search ou dois-je seulement attendre et ça va se régler tout seul ?
Bonjour,
ça dépend de la date du dernier crawl de chaque page. Vous pouvez patienter. Pour l’autre question, avez-vous bien réalisé la redirection 301 de http à https ? La propriété crée est bien en https ? Puis dernier chose, avez vous envoyer la sitemap xml avec toutes les urls https à l’intérieur ?
Pour la différence de dates, le graphique des pages indexées indiquent des résultats d’il y a plusieurs jours donc des pages non indexées et quand je « Inspecter » les pages, elles ont depuis été indexées. Du coup le graphique ne reflète pas la réalité.
Concernant le https, maintenant c’est bon, tout est en https, les pages https sont bien indexées mais il affiche des pages en http qui ne sont pas indexées. Dois-je les supprimer ou vont-elles disparaitre toutes seules ?