Vous avez déjà entendu parler du fichier robots.txt sans vraiment savoir à quoi il sert ?
C’est pourtant l’un des premiers trucs que Google consulte quand il arrive sur votre site.
Ce petit fichier texte dit aux robots des moteurs de recherche quels contenus ils peuvent explorer ou ignorer.
Avec ça, vous évitez qu’ils s’attaquent à vos pages sensibles, à vos répertoires internes ou à vos brouillons.
Googlebot, Bingbot et tous les autres utilisent ce qu’on appelle le robots protocol.
Ils lisent robots.txt à la racine du site pour suivre vos directives.
Pas de robots.txt ?
Google explore tout ce qu’il trouve.
Voici un exemple basique :
User-agent: *
Disallow: /admin/
Cette règle interdit l’accès au dossier /admin/ à tous les robots.
Mais attention : robots.txt ne fait pas tout.
Il existe aussi les balisages meta robots que vous placez directement dans le code HTML d’une page.
Et les en-têtes HTTP X-Robots-Tag, que vous définissez côté serveur, souvent pour les fichiers non HTML.
Alors, prêt à parler aux robots avec des règles simples ?
Let’s go.
Comprendre la structure d’un fichier robots.txt sans s’arracher les cheveux
Un fichier robots.txt suit une logique super claire.
Chaque règle tient en deux éléments : un User-agent et une ou plusieurs directives comme Disallow ou Allow.
Le User-agent désigne un robot spécifique.
Comme Googlebot pour Google ou Bingbot pour Bing.
Ensuite viennent les règles d’accès.
Voici les directives de base que vous utiliserez tout le temps :
Faites attention à la casse.
/Blog/ et /blog/ pointent vers deux dossiers différents.
Un robot fera clairement la différence et appliquera la directive à la lettre.
Dans la même idée, respectez l’ordre des directives.
Le fichier se lit de haut en bas.
Si deux règles se contredisent, c’est la plus spécifique et la plus proche du chemin cible qui gagne.
Prenez cet exemple simple :
User-agent: *
Disallow: /private/
Allow: /private/images/
Sitemap: https://www.monsite.fr/sitemap.xml
Ici vous bloquez toute la section « /private » pour tous les robots, sauf les images dans « /private/images » que vous laissez explorer.
Vous signalez aussi l’adresse de votre sitemap.
Placez toujours le fichier à la racine de votre site.
C’est la seule façon pour qu’il soit détecté correctement par les crawlers.
Si votre site s’appelle www.monsite.fr, votre fichier doit être accessible à cette adresse : www.monsite.fr/robots.txt
La directive Disallow dit clairement aux robots d’exploration ce qu’ils ne doivent pas visiter.
Vous l’associez à un User-agent.
Ensuite, vous spécifiez le chemin que vous voulez bloquer.
Si vous écrivez Disallow: /, vous bloquez tout.
Si vous écrivez Disallow: /dossier/, seul ce répertoire reste hors d’atteinte.
Googlebot et les autres bots qui respectent les règles s’arrêteront là.
Mais attention, le fichier robots.txt ne garantit pas la confidentialité.
Les fichiers restreints restent accessibles aux internautes qui ont un lien direct.
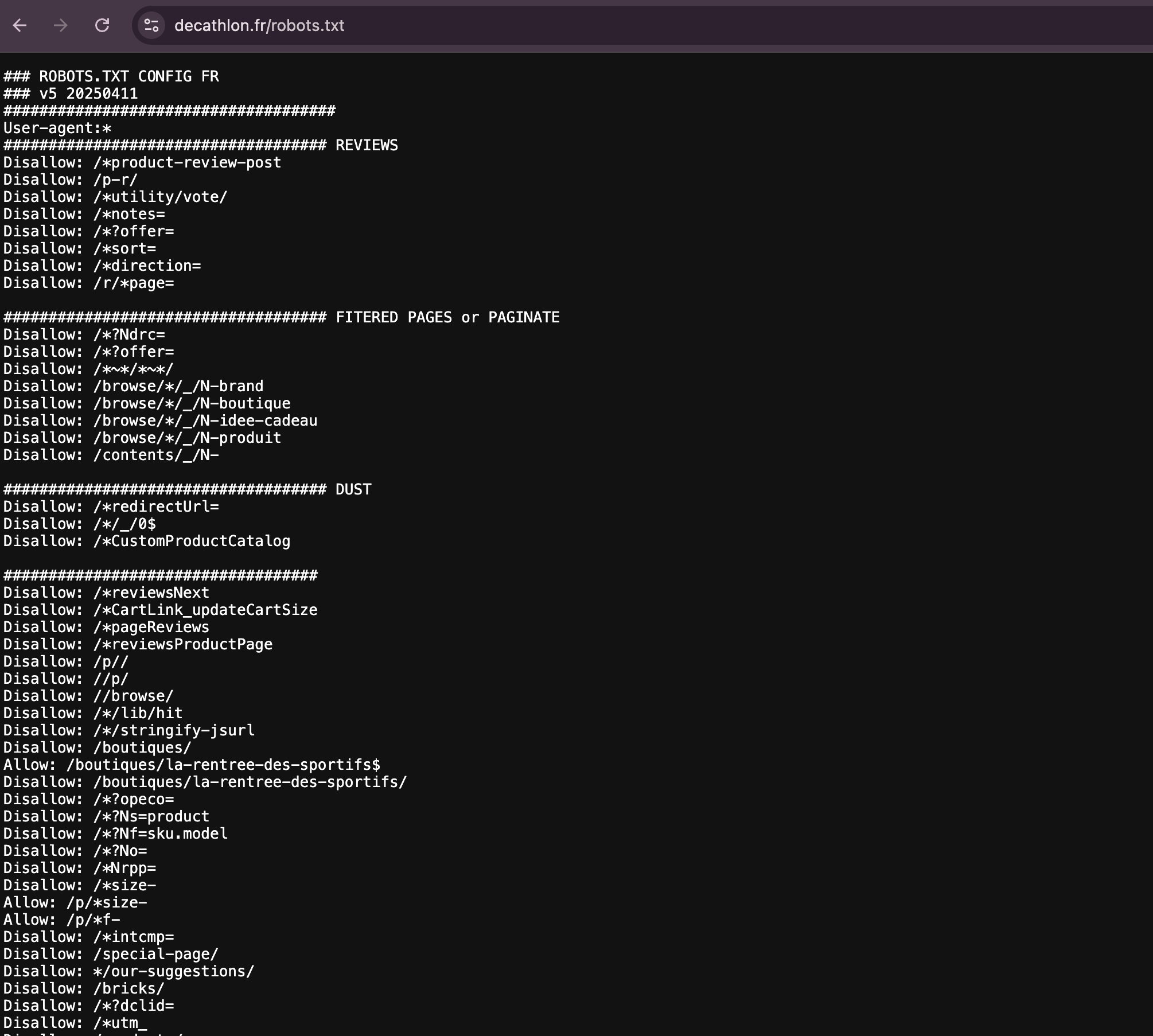
Voici un cas concret, il s’agit du site de Décathlon. Vous pouvez voir par vous-même toute l’étendue et la complexité de leur fichier robots.txtx, ici : https://www.decathlon.fr/robots.txt
Vous avez des sections que vous ne voulez pas voir indexées ?
Servez-vous de Disallow pour les bloquer :
Le plus gros piège : penser que Disallow empêche l’indexation.
Ce n’est pas le cas.
Si la page est liée ailleurs sur le web, elle peut quand même apparaître dans les résultats, sans contenu.
Autre erreur fréquente : mal formuler les chemins.
Disallow: panier ne bloque rien.
Il faut toujours utiliser le slash initial comme /panier.
Encore vu trop souvent : ajouter Disallow: /*utm= en pensant bloquer les paramètres.
Mauvais réflexe.
Le fichier robots.txt ne supporte pas les expressions régulières.
Dès que vous utilisez Disallow, vous impactez le crawl budget.
Vous évitez aux robots de perdre du temps sur des pages inutiles.
Mais si vous bloquez des pages stratégiques par erreur, vous coupez leur chance d’être explorées donc indexées.
Et là, vous perdez en visibilité.
Chaque directive Disallow doit servir un objectif clair : désencombrer le crawl, pas cacher le contenu utile.
Vous pouvez bloquer un dossier complet avec Disallow.
Mais si vous voulez quand même autoriser quelques fichiers à l’intérieur, vous faites comment ?
C’est exactement là que la directive Allow entre en jeu.
Elle donne une permission spéciale à certaines URL qui se trouvent dans un répertoire normalement interdit.
Imaginez que vous bloquez tout le dossier /wp-admin/ parce qu’il contient des fichiers sensibles.
Mais Google a besoin d’accéder à un seul fichier pour faire fonctionner certaines fonctions AJAX côté admin.
Si vous ne l’autorisez pas, certaines fonctionnalités du site ne fonctionnent pas bien dans les résultats de recherche.
Et Google rate des infos clés.
Pour ça, vous ajoutez cette ligne dans robots.txt :
Allow: /wp-admin/admin-ajax.php
Avec cette ligne, Google peut explorer ce fichier précis, même si vous avez un Disallow: /wp-admin/ juste au-dessus.
Googlebot lit et comprend Allow.
Il va comparer toutes les règles Disallow et Allow, et trouver celle qui correspond le plus précisément à l’URL.
Par exemple, si vous avez ça :
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Google va bloquer tout sauf admin-ajax.php.
Il suit la règle la plus spécifique.
Ce n’est pas une supposition, c’est documenté officiellement par Google.
Votre objectif, ce n’est pas d’ouvrir ou de bloquer aveuglément.
C’est de montrer aux robots ce qui leur est utile et de cacher le reste.
La directive Allow vous aide à faire ce tri, même dans les zones bloquées.
Chaque moteur de recherche utilise son propre robot d’exploration.
Google utilise Googlebot.
Bing utilise Bingbot.
Il y a aussi YandexBot pour Yandex.
Et DuckDuckBot pour DuckDuckGo.
Le fichier robots.txt vous permet de parler à chacun séparément.
Vous n’avez pas à imposer les mêmes règles à tout le monde.
Vous pouvez donner accès à certains endroits à Googlebot tout en les refusant à Bingbot.
Voici comment ça se présente :
User-agent: Googlebot
Disallow: /admin/
User-agent: Bingbot
Disallow: /
Dans cet exemple, Googlebot peut explorer tout sauf le dossier /admin.
Bingbot en revanche est bloqué entièrement.
C’est rapide, clair et sans ambiguïté.
Chaque User-agent doit avoir son propre bloc de directives.
Ne mélangez jamais tout dans un seul bloc sinon certains robots ignorent les consignes.
Regardez cette mauvaise pratique :
User-agent: *
User-agent: Googlebot
Disallow: /test/
Ce code n’a pas de sens pour la majorité des moteurs.
Certains vont l’ignorer, d’autres l’interpréter bizarrement.
Écrivez plutôt comme ceci :
User-agent: *
Disallow: /test/
User-agent: Googlebot
Disallow: /admin/
Le bloc User-agent: * s’adresse à tous les robots.
Ensuite, celui pour Googlebot contient des consignes propres à Google.
Tout le monde connaît Googlebot. Beaucoup connaissent Bingbot.
Mais peu pensent à Baiduspider, Exabot ou encore Slurp.
Ces robots interprètent les directives différemment.
Par exemple, Slurp (utilisé par Yahoo) ne respecte pas toujours les règles si elles ne sont pas correctement formatées.
DuckDuckBot peut aussi se comporter comme un navigateur en visitant des pages ignorées par d’autres.
Vous devez tester leur comportement sur votre site.
Surveillez les fichiers logs de serveur (journaux).
Identifiez s’ils suivent bien vos instructions.
Corrigez si besoin.
Vous avez un site très ciblé géographiquement ou un contenu sensible ?
Soyez précis.
Ajoutez des blocs pour chaque robot si vous voulez garder le contrôle total.
Vous pensez que bloquer une page avec robots.txt l’empêchera d’apparaître sur Google ?
Mauvaise nouvelle.
Google peut quand même indexer une URL bloquée si des liens externes pointent vers elle.
Même sans avoir visité la page, Google peut deviner qu’elle existe et l’afficher dans les résultats.
Mais sans contenu.
Juste le lien.
Ça peut poser problème si vous pensiez cacher un contenu sensible ou non destiné à être vu par le monde entier.
Vous mettez une ligne Disallow: /page-secrete en pensant rendre la page invisible.
Mais si un autre site crée un lien vers cette URL, Google détectera son existence.
Résultat ?
La page sort dans les résultats, même si elle n’a jamais été explorée.
C’est une indexation sans exploration.
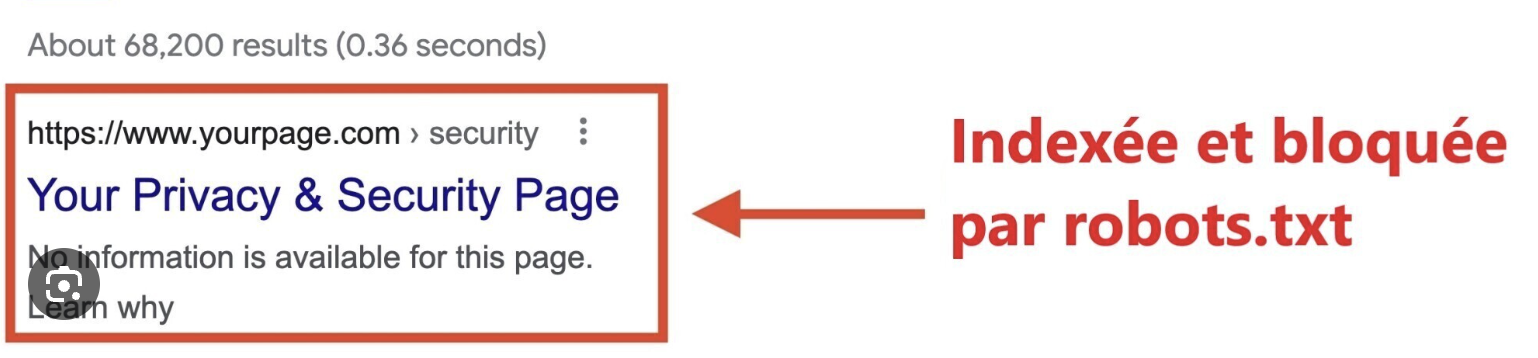
Si vous voulez empêcher une page d’apparaître dans les résultats, utilisez la balise <meta name= »robots » content= »noindex »> directement dans le code HTML.
Cette balise dit à tous les moteurs de recherche : « Tu peux venir, mais tu n’indexes rien ».
Mais attention : pour que Google lise cette balise, il faut qu’il puisse accéder à la page.
Donc pas de blocage dans le robots.txt.
Les deux méthodes ne servent pas au même objectif.
Le robots.txt contrôle juste l’exploration.
Le noindex contrôle l’affichage dans l’index.
Tapez site:votresite.fr dans Google et vous verrez parfois des pages dont vous auriez juré avoir bloqué l’accès.
Ces pages peuvent avoir été indexées parce que Google les a trouvées via des backlinks ou des fichiers sitemap envoyés avant la restriction.
Encore plus étrange : Google garde parfois en mémoire d’anciennes versions indexées même après votre mise à jour.
Alors posez-vous cette question : est-ce que la page est bloquée uniquement via robots.txt ?
Si oui, changez votre stratégie.
Remplacez le blocage par une vraie directive noindex dans le HTML.
Et supprimez l’URL du sitemap si elle y figure encore.
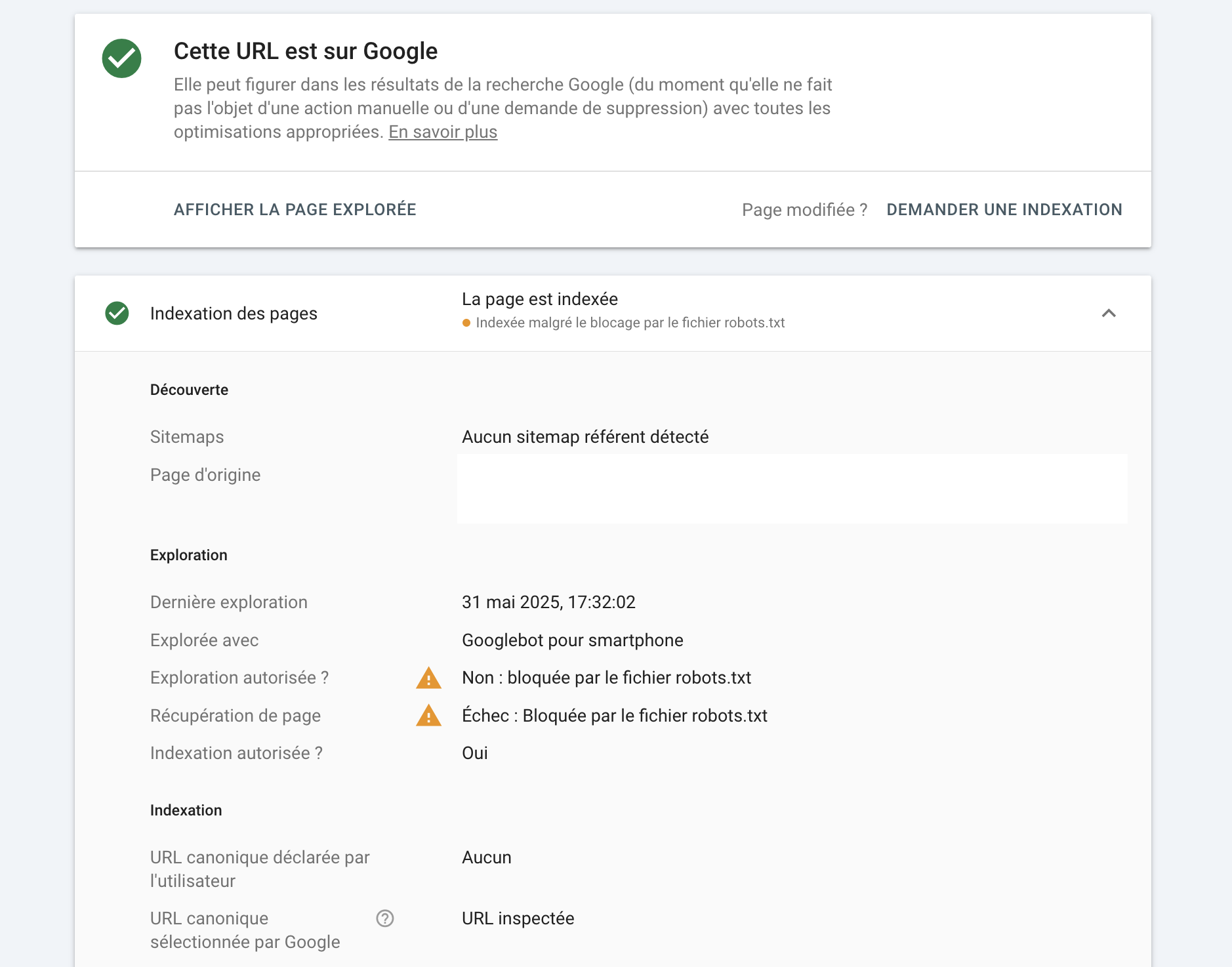
Testez sur la Search Console, inspectez l’URL, et vérifiez le statut d’indexation.
Vous avez un robots.txt ?
Très bien.
Vous avez un fichier sitemap.xml ?
Encore mieux.
Mais si vous ne les connectez pas clairement, vous perdez un levier super puissant pour guider les moteurs.
Allez droit au but.
Ajoutez une ligne simple et claire en tout début ou en fin du fichier robots.txt :
Sitemap: https://www.votre-site.com/sitemap.xml
Pas besoin de guillemets ni d’attribut magique.
Juste l’URL complète.
Et vous pouvez en déclarer plusieurs si votre contenu est segmenté.
Exemple :
Sitemap: https://www.votre-site.com/sitemap-index.xml
Sitemap: https://www.votre-site.com/blog/sitemap.xml
Vous voulez que Google ou Bing trouve plus vite vos pages clés ?
Ce lien dans le fichier robots.txt sera parcouru presque immédiatement.
Quand les robots accèdent à votre site, ils consultent d’abord robots.txt.
S’ils y trouvent votre sitemap, ils le visitent dans la foulée.
Et là, bingo, vous leur donnez un plan du site à suivre, page par page.
Résultat : l’exploration devient plus ciblée.
Googlebot ne gaspille pas de ressources pour chercher des pages inutiles.
Il accède tout de suite à ce que vous jugez important.
Moins de pages orphelines.
Meilleure couverture dans l’index.
Moins de gaspillage de budget crawl.
Google lit parfaitement cette directive.
C’est même recommandé officiellement par Google Developers.
Bing la prend aussi en compte.
Idem du côté de DuckDuckGo et Yahoo avec les mêmes standards.
Mais attention : Yandex n’utilise pas toujours cette ligne comme signal fort.
Il préfère un sitemap envoyé via ses outils.
Si vous travaillez avec plusieurs moteurs, publiez cette URL sitemap ici ET soumettez-la dans leurs outils respectifs.
Double impact instantané.
Vous bloquez des pages produits sans le vouloir ?
Ce genre d’erreur peut faire disparaître des pages clés des résultats Google.
Surtout si elles génèrent du trafic ou des conversions.
Vérifiez toujours si vos directives Disallow ne bloquent pas des URLs importantes.
Contrôlez aussi les répertoires impactés, surtout si vous automatisez la génération du fichier.
Les astérisques (*) et les signes dollar ($) peuvent vous piéger facilement.
Un Disallow: /blog* va bloquer /blog, /blogue et /blog-category sans distinction.
Pas de slash final ?
Les moteurs liront une URL, pas un répertoire.
Exemple : Disallow: /dossier bloque /dossier mais pas /dossier/page.html.
Avec /dossier/, ça bloque l’ensemble du dossier.
Google respecte robots.txt.
Bing aussi.
Mais Yandex ou certains bots obscurs ?
Pas sûr du tout.
Certains crawlers ignorent totalement vos directives.
Si vous voulez protéger des données sensibles, utilisez l’authentification ou limitez l’accès via le serveur.
Pas juste via robots.txt.
Un mauvais fichier robots.txt peut annihiler votre visibilité.
Googlebot ne verra plus vos pages.
Pas d’indexation.
Plus de trafic organique.
Ahrefs explique d’ailleurs que bloquer Googlebot via le fichier robots.txt peut empêcher l’indexation de contenu essentiel.
Vous perdez du trafic sans même le savoir.
Posez-vous cette question : est-ce que Google peut accéder à mes pages les plus rentables ?
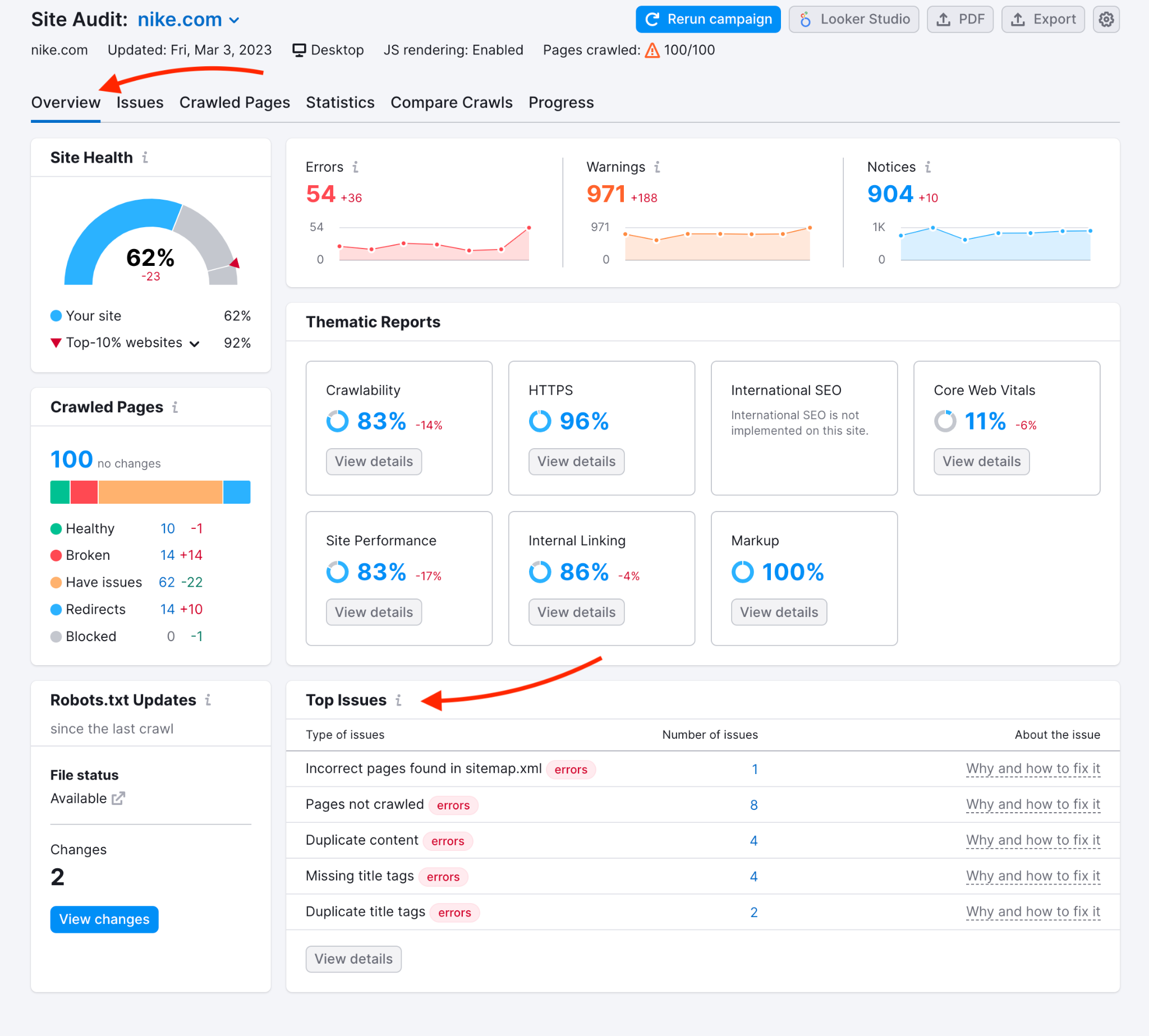
Vous avez modifié votre fichier robots.txt et maintenant certaines pages disparaissent de Google ?
Passez par Google Search Console.
C’est l’outil le plus direct pour visualiser les erreurs, tester des modifications et corriger rapidement ce qui bloque l’exploration.
Dans Search Console, ouvrez le menu de gauche et cliquez sur « Paramètres », puis sur « Statistiques sur l’exploration » et enfin sur « État de l’hôte ».

C’est rapide et accessible à tous les comptes validés.
Vous verrez immédiatement si Googlebot rencontre un problème en lisant votre fichier actuel.
L’outil montre le contenu lu en direct et signale les erreurs techniques.
Un simple slash mal placé peut bloquer tout un répertoire.
Vous pouvez voir des erreurs courantes comme :
En testant une URL dans l’outil, vous saurez tout de suite si Google peut l’explorer ou non.
Un indicateur rouge = bloqué. Un vert = exploré.
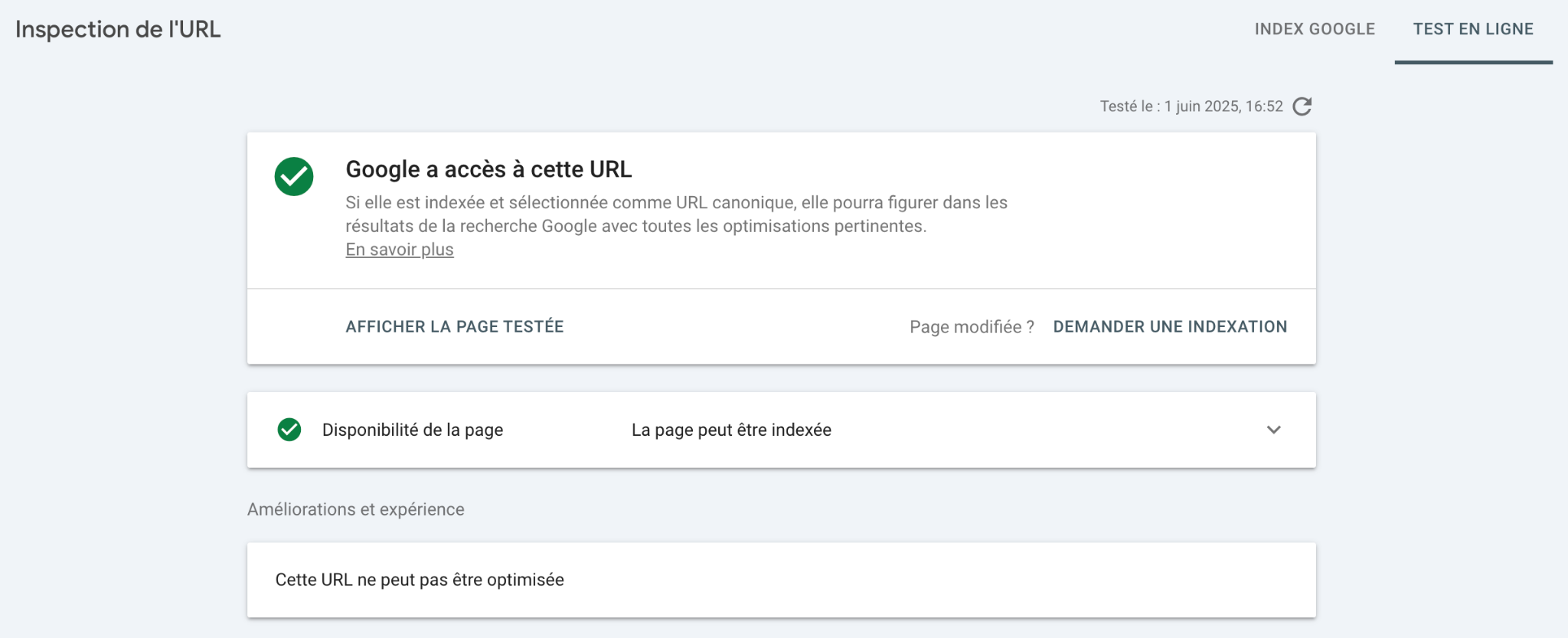
Ouvrez Google Search Console, et allez direct dans « Inspection de l’URL ».
Collez l’URL que vous voulez tester, appuyez sur Entrée.
Google vous dit tout de suite si l’URL est indexable ou non.
Et surtout pourquoi elle ne l’est pas.
Pas besoin d’attendre des heures, tout est instantané.
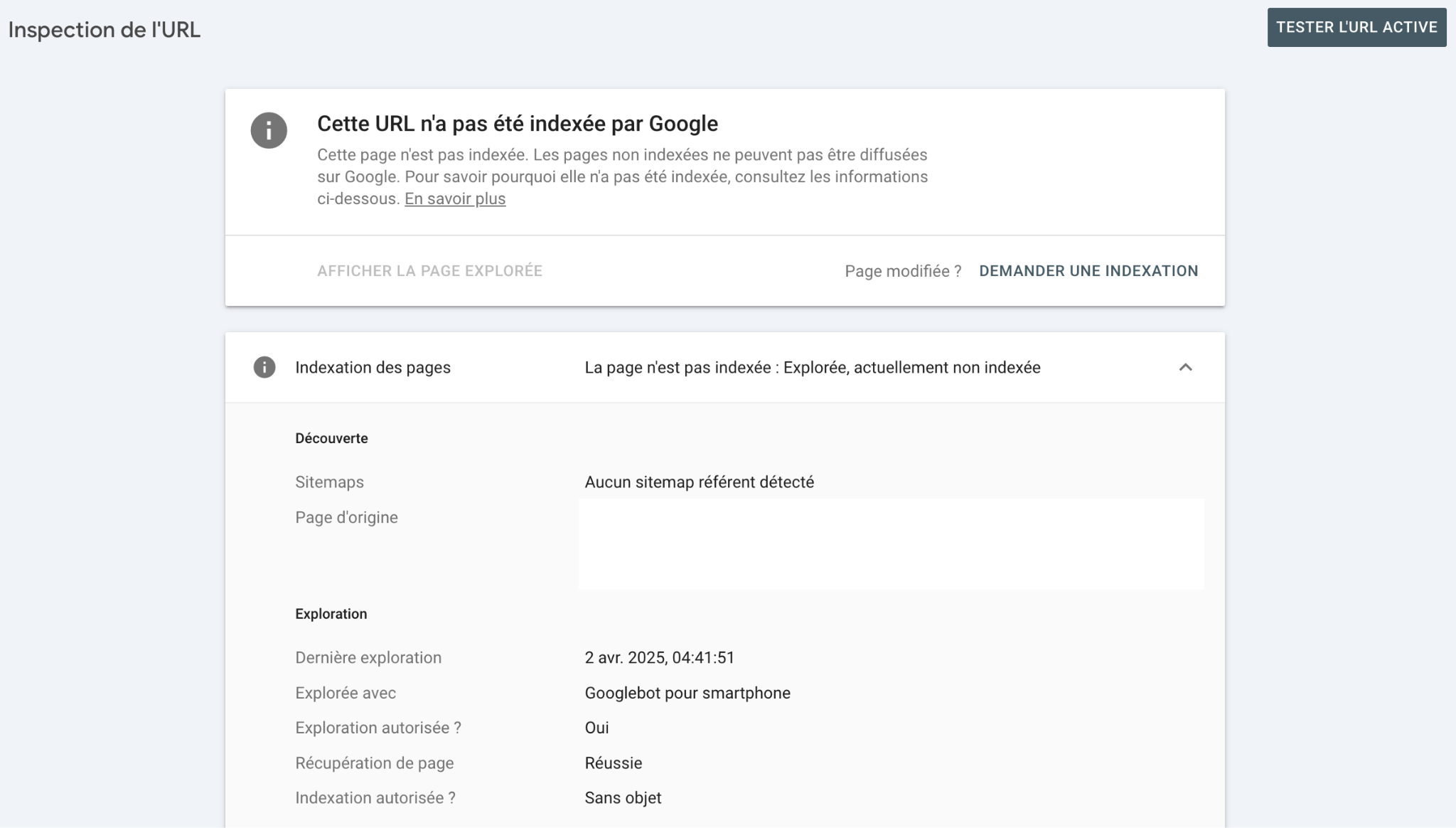
Regardez la section « Couverture » du rapport.
Si vous lisez « bloquée par le fichier robots.txt », vous avez une règle dans votre fichier qui empêche le crawl.
Par exemple une directive Disallow: /dossier/ qui bloque l’accès à ce dossier entier.
En revanche, si le message dit « explorée, actuellement non indexée » ou « exclue par la balise noindex », le problème vient du code HTML de la page.
La ligne à vérifier côté code c’est ça : <meta name= »robots » content= »noindex »>
Chaque cas a son propre remède, donc il faut bien différencier.
L’inspecteur d’URL sert à valider en live vos changements de robots.txt.
Vous modifiez une directive, vous testez ensuite direct l’impact sur une URL précise.
Aucun autre outil ne donne une réponse aussi fiable sur ce que Google voit.
Pour un audit SEO technique, c’est une vérification de base que vous devez faire page par page.
Vous identifiez les pages bloquées par erreur, mais aussi les pages stratégiques mises de côté sans raison.
Vous gagnez un temps fou si vous listez d’abord les pages essentielles de votre entonnoir de conversion et que vous les testez une par une.
Gérer un site multilingue peut rapidement devenir un casse-tête.
Surtout quand il s’agit d’aider Google à comprendre qui doit voir quoi.
Le fichier robots.txt peut vous simplifier la vie. Mais mal utilisé, il peut aussi vous pénaliser.
Vous avez des sections spécifiques pour chaque langue ou zone géographique comme /fr/, /en/ ou /de/ ?
Vous pouvez contrôler ce que les robots explorent grâce à quelques lignes dans votre robots.txt.
Par exemple, si vous avez une version anglaise uniquement destinée aux États-Unis, vous pouvez bloquer son exploration dans d’autres contextes.
Ça évite que Google indexe des versions non pertinentes dans les SERP locales.
Mais pensez toujours à accompagner ça d’une bonne stratégie hreflang.
Google peut voir vos différentes versions linguistiques comme du contenu dupliqué si les signaux sont mal envoyés.
Robots.txt n’est pas là pour régler ça.
Il ne fait que bloquer ou autoriser l’accès.
Ne redirigez jamais automatiquement tous les utilisateurs vers une langue en fonction de leur IP.
Googlebot vient souvent des USA.
Si vous le redirigez vers /en/ même s’il explore /fr/, vous perdez en visibilité.
Utilisez l’attribut hreflang dans les balises HTML ou les en-têtes HTTP.
Ne comptez pas sur le robots.txt pour gérer la duplication.
Imaginons votre site utilise une structure par répertoire :
Vous ne souhaitez pas que les moteurs accèdent à une version de test de votre version allemande à l’adresse /de-test/ ?
Ajoutez ça :
Vous réduisez les erreurs d’indexation et vous évitez d’envoyer de mauvais signaux à Google.
Combinez ça avec un sitemap clair et vous poserez les bases d’un bon SEO international.
Google n’explore pas tout.
Il donne à chaque site un quota.
C’est ce qu’on appelle le crawl budget.
Si vous gérez un gros site avec des milliers d’URL, alors vous devez absolument l’optimiser.
Google définit le crawl budget comme le volume d’URL que son robot va explorer sur votre site sur une période donnée.
Ce volume dépend de deux facteurs :
Selon Google, un site moyen a assez de budget pour toutes ses pages.
Mais pour un site e-commerce ou un média avec des milliers de pages, c’est une autre histoire.
Là, Google doit faire des choix.
Et vous pouvez l’aider avec un robots.txt bien pensé.
Les pages qui n’apportent rien côté SEO doivent sortir du radar des robots.
En bloquant leur exploration, vous libérez du budget pour les pages vraiment utiles.
Voici ce que vous pouvez exclure avec la directive Disallow :
En ciblant ces zones, vous évitez à Google de gaspiller du temps sur des pages temporaires ou peu stratégiques.
Quand Google arrête de visiter les pages secondaires, il passe plus de temps sur les pages clés.
Résultat : un meilleur taux d’indexation et une fréquence de crawl plus élevée sur les pages qui génèrent du trafic.
C’est comme dégager une route pour une ambulance.
Vous facilitez l’accès aux pages qui comptent vraiment.
Vous voulez aller plus loin ?
Analysez vos logs serveur.
Identifiez les URL trop visitées par Googlebot et sans valeur pour le SEO.
Puis bloquez-les dans un fichier robots.txt mis à jour.
Chaque ligne que vous ajoutez doit avoir une raison précise.
Vous guidez Google avec clarté.
Prenez une heure.
Listez les types de pages qui génèrent peu ou pas de trafic organique.
Posez-vous cette question : est-ce que Google a besoin de les explorer une par une ?
Si la réponse est non, vous savez ce qu’il vous reste à faire.
Pour plus de facilité, pensez à utiliser un outil d’audit de site comme Semrush, qui vous communiquera tous les points à corriger.
Robots.txt et meta robots n’agissent pas au même niveau.
Le fichier robots.txt joue sur le serveur.
Il dit aux robots ce qu’ils peuvent explorer ou non avant même qu’ils ne voient le contenu.
Le meta robots agit à l’intérieur de chaque page.
Il donne des ordres précis une fois que la page est atteinte.
Du coup, si vous bloquez une page dans le robots.txt, les moteurs ne pourront pas accéder au code de cette page, y compris sa balise meta robots.
À l’inverse, si vous laissez l’accès mais que la balise contient un noindex, alors la page sera vue mais pas indexée.
Vous pouvez jouer sur les deux tableaux pour guider Google étape par étape.
Par exemple, laissez Googlebot accéder à certaines pages via le robots.txt puis contrôlez leur indexation ou leur affichage avec les meta robots.
C’est utile quand vous gérez beaucoup d’URLs en e-commerce ou avec des paramètres filtrants.
Vous laissez le robot explorer pour découvrir la structure du site, mais vous l’empêchez d’indexer des doublons grâce à noindex, follow.
Le fichier robots.txt ne vous aidera pas si vous voulez gérer l’apparence d’une page dans Google.
Vous avez besoin des directives meta robots pour ça :
Posez-vous ces questions simples : voulez-vous limiter le crawl, l’indexation ou juste ce qui s’affiche ?
Votre boutique en ligne bouge tout le temps.
Des fiches produits arrivent.
D’autres expirent.
Les filtres se multiplient.
En clair, votre contenu change sans arrêt.
Si vous ne mettez pas votre fichier robots.txt à jour en temps réel, les moteurs vont crawler n’importe quoi.
Et vous allez griller votre budget de crawl en explorations inutiles.
Vous pouvez ajouter une logique dynamique à votre robots.txt.
Par exemple, dès qu’un produit passe en rupture et disparaît du catalogue, un script peut automatiquement ajouter son URL dans le fichier.
Dès que le produit revient, le script retire la ligne.
Pas besoin d’intervention manuelle.
Vous gardez votre SEO sous contrôle, même à grande échelle.
Vous utilisez Shopify, Prestashop ou Magento ?
Tous permettent d’intégrer des modules ou scripts pour modifier automatiquement le contenu du robots.txt.
Côté serveur, ajoutez une couche d’automatisation via un fichier PHP ou Node.js qui rédige votre robots.txt en temps réel.
Il peut se baser sur une base de données, l’état du stock ou la date d’expiration des fiches produits.
Les filtres de recherche comme ?couleur=bleu ou ?taille=XL génèrent des centaines d’URL.
Google les explore toutes… sauf si vous les bloquez.
En ajoutant une règle comme Disallow: /*?*, vous interdisez l’accès à toutes les URL avec des paramètres.
Vous pouvez faire plus fin avec Disallow: /*?tri=* pour ne bloquer que certains filtres.
Dans le cas des produits expirés, vous pouvez même créer une règle dynamique comme :
Disallow: /produits/chaussures-basket-airmax-2022 si le produit n’est plus en stock.
Votre script vérifie l’état du stock chaque nuit et adapte le robots.txt automatiquement.
Pas d’oublis.
Pas de frustration pour les robots.
Pas de perte de crawl.
Vous devez vous demander :
Prenez une minute pour identifier ces réponses. Elles valent de l’or pour votre budget de crawl.
Vous testez une nouvelle version de votre site ?
Évitez qu’elle se retrouve indexée par Google en 2 clics en bloquant l’exploration avec un fichier robots.txt.
Les robots des moteurs n’attendent pas votre feu vert.
Ils explorent tout ce qui est public, y compris votre environnement de staging.
Et ce contenu peut apparaître dans les résultats de recherche.
Pas vraiment l’effet recherché sur une version non finale du site, non ?
Voici la directive à utiliser pour les bloquer complètement :
User-agent: *
Disallow: /
Ce blocage empêche tous les robots d’accéder à n’importe quelle page.
C’est la méthode la plus simple et la plus efficace en phase de dev.
Pas besoin d’un mot de passe ni de config serveur compliquée.
Mais attention après le déploiement.
Si vous copiez l’environnement de staging vers la prod, vous copiez souvent aussi ce fichier robots.txt.
Résultat : même en production, Google reste bloqué.
Votre nouveau site ne s’indexe pas et la visibilité tombe à zéro.
Alors pensez toujours à supprimer ou modifier cette directive avant le lancement officiel.
Vous voulez éviter cet oubli classique ?
Programmez un avertissement dans votre outil de CI/CD.
Ou placez une vérification automatique avant chaque mise en ligne.
Et si vous travaillez avec une équipe, assurez-vous que tout le monde connaît cette consigne.
Un détail de ce genre peut ruiner des mois de travail.
Vous protégez votre staging mais gardez le contrôle.
Vous préparez une refonte, une migration ou un gros déploiement ?
Plutôt que de désindexer tout votre site, bloquez simplement l’exploration le temps d’intervenir.
Votre fichier robots.txt peut suspendre l’accès des robots sans perturber votre positionnement dans les résultats.
Le noindex dit à Google de retirer une page de son index.
Pas génial si vous revenez en ligne le lendemain.
Vous risquez de devoir reconstruire toute votre visibilité.
Mauvais plan.
A contrario, bloquer l’exploration via robots.txt coupe temporairement l’accès des robots sans toucher à l’indexation.
Google garde une trace de vos pages.
Modifiez votre fichier robots.txt pour stopper les bots sans supprimer vos pages des résultats :
Cette règle dit à tous les moteurs de recherche de ne plus explorer aucune page.
Simple et efficace.
Dès que votre site est de nouveau opérationnel, supprimez la règle Disallow: /.
Ne laissez pas Google bloqué plus longtemps que prévu.
Pour accélérer le retour à la normale, utilisez l’outil d’inspection d’URL dans Google Search Console. Cliquez simplement sur « Tester l’URL active ».
Il vous aidera à forcer le recrawl des pages clés.
Pas plus de 48 heures.
Au-delà, Google commence à ignorer votre site.
Et là, le retour peut prendre plusieurs semaines.
Posez-vous cette question : avez-vous défini un rappel pour retirer la limitation ?
Si ce n’est pas déjà fait, faites-le maintenant.
Le fichier robots.txt peut bloquer l’accès à tout un site.
Il peut aussi booster votre SEO s’il est bien configuré.
Vous savez maintenant comment écrire ses directives.
Comment les tester.
Comment les ajuster pour des cas spécifiques comme l’international, l’e-commerce ou les environnements de staging.
Auditez-le régulièrement.
Faites-le à chaque refonte.
À chaque changement d’architecture.
Utilisez Google Search Console.
Inspectez vos URL.
Corrigez vite si un bot se retrouve bloqué là où il ne faut pas.
Votre robots.txt raconte une histoire aux moteurs, il doit rester cohérent, à jour, lisible par les bots et sans contradiction avec vos balises meta.
Vous avez déjà eu une galère à cause de votre fichier robots.txt ?
Partagez vos expériences.
Formation SEO et stratégies de référencement
naturel avancées

Laisser un commentaire