Vous vous demandez pourquoi certaines pages de votre site restent invisibles dans les résultats de recherche ?
Le problème vient peut-être de votre budget de crawl (crawl budget en anglais).
Google ne visite pas toutes les pages de votre site à chaque passage, il fait des choix.
Et ces choix dépendent du budget de crawl.
Voici l’idée :
Le budget de crawl correspond au nombre maximal de pages que Googlebot va explorer sur votre site pendant une période donnée.
Pas plus.
Même si vous avez 100 000 pages, il n’ira pas forcément toutes les voir.
Googlebot alloue ses ressources en fonction de deux choses.
D’abord, la capacité de votre serveur à répondre sans ralentir.
Ensuite, l’intérêt perçu de vos pages.
Si Google juge que certaines pages n’apportent pas grand-chose, il les ignore.
Littéralement.
Ne confondez pas budget de crawl et fréquence de crawl.
La fréquence c’est combien de fois une page est revisitée.
Le budget, lui, c’est combien de pages au total Google se donne le droit de consulter pendant un certain temps.
Si vous dépassez ce quota, d’autres pages passeront à la trappe.
Du coup, comment optimiser ce budget ?
Qu’est-ce qui fait que Google va explorer une page plutôt qu’une autre ?
C’est ce qu’on va voir dans ce guide !
Google passe plus souvent sur les sites populaires.
Si beaucoup de sites fiables pointent vers vous, vous envoyez un signal fort.
Vous dites à Google : « Viens plus souvent, je suis intéressant ».
Les backlinks de qualité boostent votre autorité.
Plus vous en avez, plus Google explore de pages.
Ahrefs a montré que 96,55 % des pages sans backlinks n’ont aucun trafic organique.
Votre trafic joue aussi.
Un site qui reçoit beaucoup de visiteurs génère plus d’interactions, donc plus d’intérêt pour Googlebot.
Si vos pages renvoient des erreurs 500 ou 404, Google perd du temps.
Il réduit le nombre de tentatives.
Moins de pages explorées = moins de pages indexées.
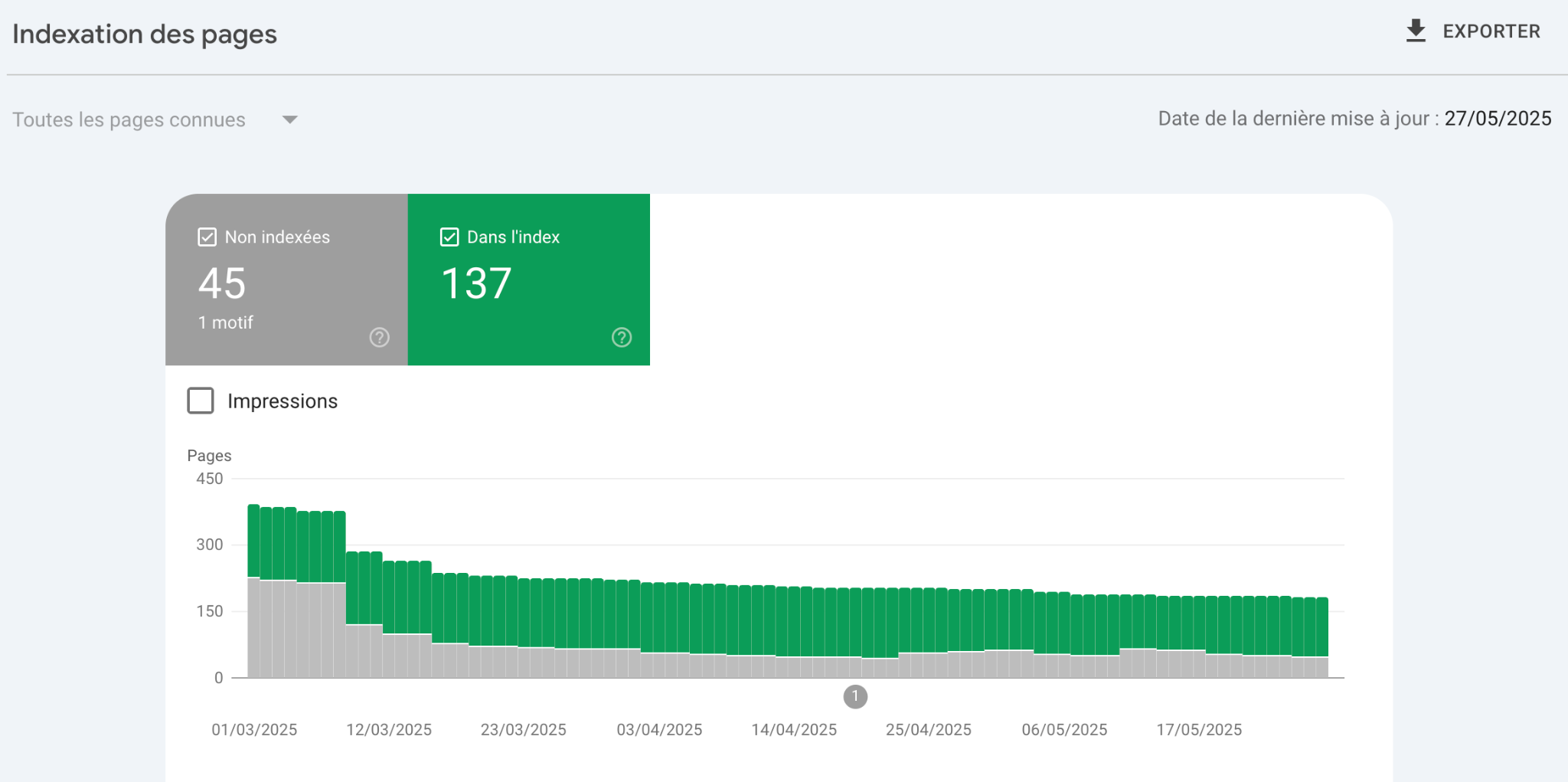
Pour vous aider à monitorer ça, utilisez Google Search Console.
Surveillez les erreurs dans le rapport « Couverture ». Corrigez-les rapidement.
Sinon vous risquez de dilapider votre budget de crawl.
Les redirections infinies, les chaînes de redirection et les pages bloquées font perdre patience à Googlebot.
Il baisse la cadence.
Publiez du contenu original et utile.
Google récompense la valeur ajoutée.
Il revient plus souvent s’il trouve du neuf.
Quand vous mettez à jour vos pages régulièrement, ça se voit.
Le robot adore les pages vivantes.
HubSpot a découvert que les sites qui publient souvent des articles de blog ont 434 % plus de pages indexées.
Chaque clic compte.
Si une page demande 6 clics depuis la page d’accueil, elle devient presque invisible.
Gardez une structure peu profonde.
Faites en sorte que les pages importantes soient accessibles en 3 clics max.
Un bon maillage montre à Google quelles pages vous jugez précieuses.
Il suit les liens internes comme un GPS.
Si votre site rame, Googlebot explore moins de pages.
À chaque milliseconde perdue, votre budget de crawl fond comme neige au soleil.
Google donne la priorité aux sites rapides.
PageSpeed Insights donne des pistes concrètes pour améliorer vos temps de chargement.
Selon une étude de Think with Google, 53 % des visites mobiles quittent un site si le chargement dépasse 3 secondes.
Un site rapide égal plus de pages explorées et donc plus de chances d’apparaître dans les résultats.
Le crawl rate correspond au nombre de requêtes que Googlebot peut faire sur votre site par seconde ou par minute.
C’est une sorte de limite que Google s’impose pour ne pas surcharger vos serveurs.
Si votre hébergement est lent ou instable, Google réduira cette fréquence.
Il protège vos ressources avant même de penser à votre SEO.
Dans Google Search Console, vous pouvez voir ce rythme moyen d’exploration dans l’onglet “Statistiques sur l’exploration”.
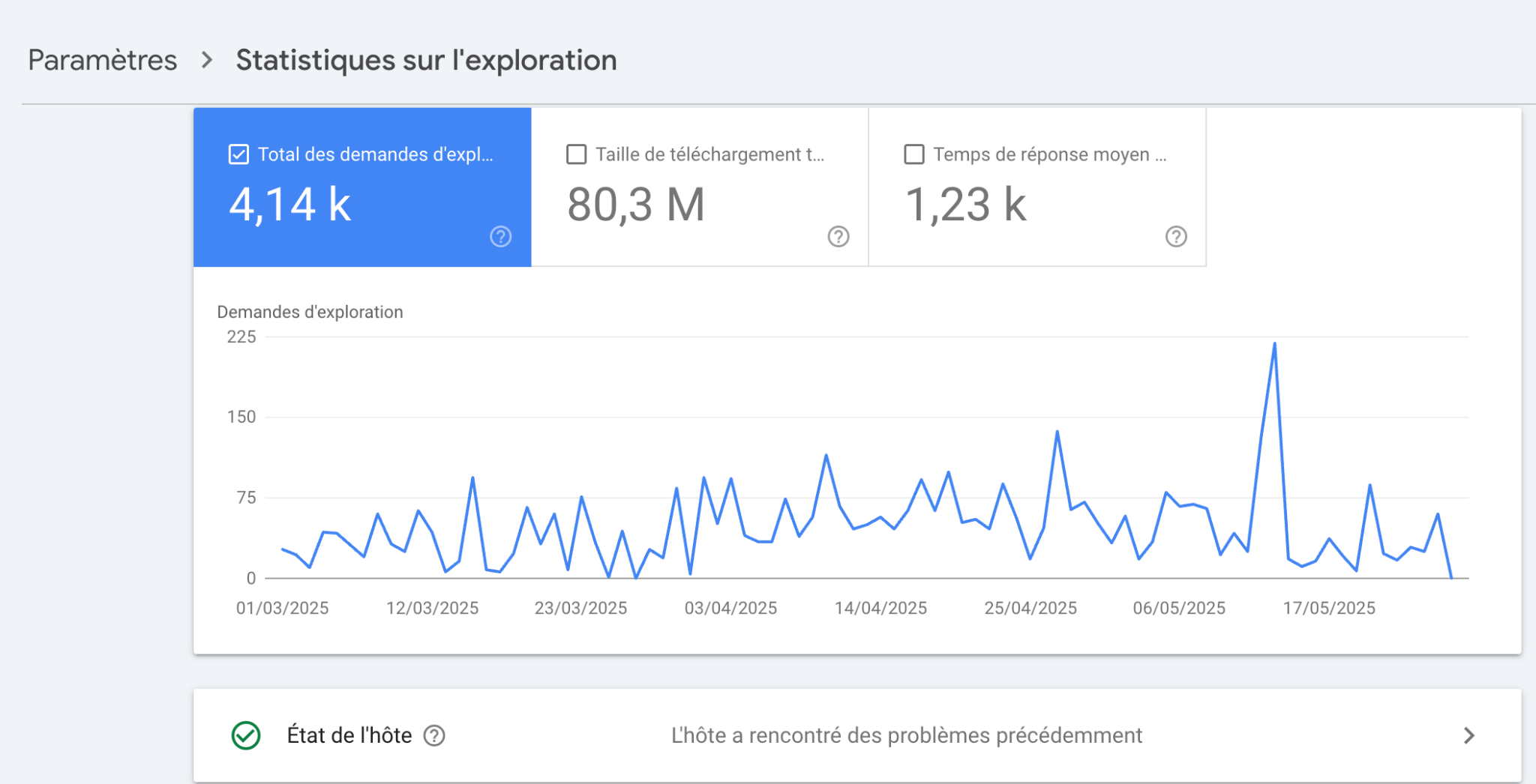
Il détaille aussi le volume quotidien de données téléchargées en Mo, et le temps de réponse moyen.
Le budget de crawl, lui, représente la quantité totale de ressources que Google consacrera à l’exploration de votre site sur une période donnée.
C’est comme si vous donniez à Google un nombre maximum de pages à regarder chaque jour.
La taille du site, la qualité du contenu, la fréquence de mise à jour ou encore les codes 404 influencent tous cette limite globale.
Pas de panique, Google ne fixe pas ce budget au pif.
Il s’adapte.
Sur un site sain avec un bon temps de réponse serveur et peu d’erreurs, il va l’augmenter naturellement.
Ce n’est pas parce que votre crawl rate est élevé que Googlebot explorera davantage de pages.
Disons que le crawl rate permet d’aller vite, mais que le budget limite la distance.
Vous pouvez avoir une Ferrari (vitesse) mais pas assez d’essence (budget) pour visiter toutes les pages souhaitées.
Inversement, si votre site ralentit ou renvoie trop d’erreurs, Google réduira la vitesse d’exploration.
Il préservera ses ressources et les vôtres.
Un mauvais crawl rate empêche Google de scanner vos nouvelles pages rapidement.
Un budget de crawl trop limité fera passer vos pages stratégiques à la trappe.
Résultat, elles n’entrent jamais dans l’index.
Donc elles n’obtiennent aucun trafic organique.
L’erreur ici, c’est de croire que toutes vos pages ont la même chance d’être indexées.
Google trie.
Il gère son temps comme vous gérez une to-do list.
Il se concentre sur ce qui semble prioritaire :
Vous voulez voir les effets directs ?
Analysez les logs de votre serveur.
Vous verrez ce que Googlebot visite, ignore ou abandonne.
En comprenant cette interaction entre rythme et limite, vous pouvez ajuster votre architecture, nettoyer votre contenu et guider efficacement Google jusqu’aux pages qui comptent.
Google visite une page, lit son contenu, puis décide de l’indexer ou non.
C’est un cycle simple : crawl → analyse → indexation.
Mais si Google ne visite pas une page, il ne pourra même pas décider quoi en faire.
Pas de crawl, pas d’index. Donc pas de trafic.
Quand vous gaspillez votre budget sur des pages inutiles comme des filtres, des pages de tri ou des doublons, Google ignore d’autres pages.
Parfois des pages importantes.
Vous publiez un article stratégique ou une landing page ?
Si elle est trop profonde dans la structure ou noyée dans un tas de contenus peu pertinents, Google peut la zapper.
Ce n’est pas une théorie.
Sur les sites de plus de 10 000 pages, c’est une réalité fréquente.
Une page orpheline, c’est une page sans lien entrant depuis votre site.
Google a peu de chances de la découvrir.
Elle reste invisible.
Vous dépensez du temps à la créer mais elle n’existe pas aux yeux du moteur.
Les logs serveurs le prouvent.
Vous pouvez avoir des pages publiées depuis des mois qui n’ont jamais été crawlées une seule fois.
Zéro passage.
Juste parce qu’elles sont isolées du reste.
Vous avez identifié ce type de page sur votre site ?
Demandez-vous comment Google est censé la découvrir.
Quand vous gérez un gros site, Google ne va pas tout crawler d’un coup.
Il va faire des choix.
S’il tombe sur des milliers de pages inutiles, il ignorera sûrement des pages clés.
Ça veut dire moins d’indexation et moins de visibilité.
Un site géant, c’est souvent des millions d’URL, des pages dupliquées, voire des contenus obsolètes qui traînent depuis des années.
Si vous ne faites rien, Googlebot perd son temps là-dessus.
Résultat : il ne voit pas ce que vous voulez vraiment montrer.
Commencez par remettre de l’ordre dans vos contenus
Demandez-vous si chaque page mérite réellement d’être crawlée.
Si une page n’a pas de valeur pour vos visiteurs ou pour le SEO, bloquez son accès via le fichier robots.txt ou la balise noindex.
Ciblez les pages qui performent, celles qui génèrent du trafic, des conversions ou des backlinks.
Ce sont elles que Google doit explorer en priorité.
Réduisez l’empreinte inutile sur votre budget de crawl
Vous avez sûrement des paramètres d’URL qui créent plein de pages similaires.
Ou des filtres dans vos listes produits qui génèrent des centaines d’URL différentes mais identiques.
Ça pollue votre crawl.
Utilisez Google Search Console pour repérer ces URL.
Puis traitez-les : canonicals, gestion des paramètres, blocage si nécessaire.
Moins Google a de pages à explorer, plus il se concentre sur celles qui ont de la valeur.
Faites scanner votre site avec un outil comme Screaming Frog ou Sitebulb.
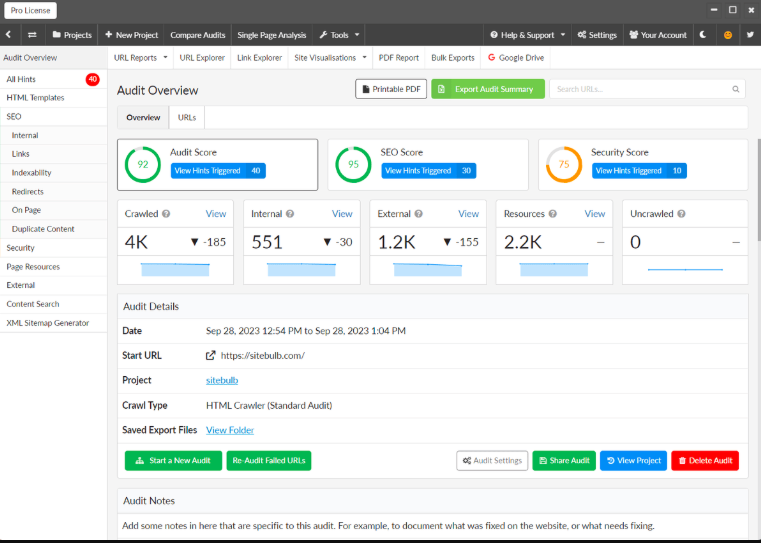
Vous verrez si des pages inactives sont toujours accessibles, si vous avez des chaînes de redirection, des erreurs 404, ou des dizaines de balises title dupliquées.
Mettez en place des routines de maintenance pour garder votre structure propre.
Supprimez les anciennes pages, archivez celles qui sont inutiles ou redirigez-les vers du contenu pertinent.
Vous vous demandez si ça demande du travail ?
Oui.
Mais chaque action de nettoyage libère du budget de crawl pour vos pages les plus stratégiques.
Et ça, Google le remarque très vite.
Google n’aime pas perdre son temps.
Si votre site met trop de temps à répondre, Googlebot ira voir ailleurs.
Littéralement.
Chaque fois que Googlebot explore une page, il mesure la latence, la taille des fichiers et la rapidité du serveur.
Il préfère les sites rapides, stables et bien structurés.
Si le vôtre rame, il réduira la cadence du crawl.
Latency, poids des ressources et délais de réponse
Google suit trois signaux techniques très précis :
Plus ces valeurs explosent, moins le nombre de pages explorées sur une même session de crawl sera important.
Un site lent ralentit la fréquence d’exploration
Google fonctionne en quota.
Chaque site a un budget de crawl défini en nombre de pages et en temps serveur.
Si votre serveur réagit lentement, Googlebot consomme plus de ressources pour chaque page.
Résultat ?
Il écarte de plus en plus de pages à chaque passage.
Les nouvelles pages restent invisibles.
Les anciennes ne sont plus mises à jour.
Et le référencement s’effondre lentement.
Pour fluidifier le crawl, vous devez d’abord optimiser l’expérience utilisateur.
Google l’a clairement dit, les signaux Core Web Vitals comptent aussi pour l’exploration :
Voici quelques optimisations de base mais très impactantes:
Vous voulez que Google crawle plus, plus vite et plus souvent ?
Chaque milliseconde compte.
Vous avez déjà vu des erreurs 404 ou 500 dans votre Search Console ?
C’est mauvais signe pour votre budget de crawl.
Chaque fois que Googlebot tombe sur une erreur, il a l’impression de perdre son temps.
Il va revenir moins souvent.
Il va explorer moins de pages.
Résultat direct : vos pages neuves ou mises à jour peuvent mettre beaucoup plus de temps à être indexées.
Les erreurs les plus fréquentes
Les erreurs que l’on retrouve le plus souvent sont :
Ces statuts HTTP poussent Google à douter de la fiabilité de votre site.
Moins il fait confiance, plus il limite son crawl.
S’il détecte trop de 404 ou de 500, Googlebot commence à ignorer certaines pages de votre site.
Il réduit la fréquence de ses visites.
Il ajuste le crawl rate à la baisse.
En clair, vous gaspillez votre budget de crawl pour des erreurs.
Et les pages qui en valent la peine attendent leur tour.
Ce phénomène s’amplifie sur les grands sites avec beaucoup d’URLs.
Chaque erreur coûte plus cher.
Vous pouvez tout suivre et corriger avec les bons outils
Commencez avec Google Search Console dans l’onglet « Pages », vous verrez toutes les URLs en erreur.
Google indique le type exact d’erreur et depuis quand elle persiste.
Utilisez ensuite Screaming Frog.
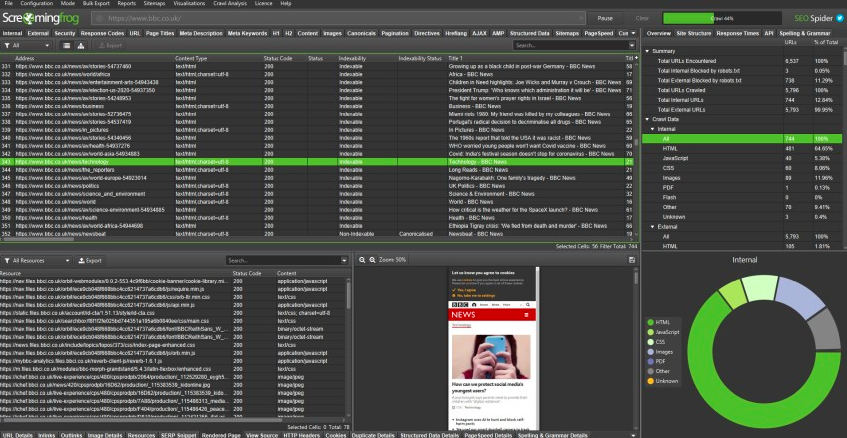
Cet outil vous permet de crawler votre site comme Googlebot le ferait.
Vous verrez rapidement les 404, 500, redirections cassées, boucles, et soft 404.
Corriger les erreurs techniques nettoie le chemin pour Googlebot.
Vous récupérez un meilleur taux d’exploration.
Et vous valorisez chaque visite du robot.
Alors, quelle est la dernière fois que vous avez vérifié vos erreurs serveur ?
Oui je sais… mais il n’est jamais trop tard !
Le fichier robots.txt dit à Googlebot où aller et où ne pas aller.
Il agit comme un panneau de signalisation à l’entrée de votre site.
Quand vous bloquez des sections inutiles, vous libérez de la bande passante pour ce qui compte vraiment.
Pages de test, filtres de recherche, URLs à paramètres… inutile de les laisser se faire crawler encore et encore.
En les désactivant dans le robots.txt, vous évitez le gaspillage.
Si vous bloquez par erreur le CSS ou le JavaScript, Googlebot ne verra pas correctement vos pages.
Et quand on ne voit pas bien, on ne comprend pas bien.
Résultat ?
Mauvaise interprétation de la mise en page, du contenu, voire de l’ergonomie mobile.
Google l’a confirmé : pour bien indexer une page, il doit accéder à tous ses éléments essentiels.
Imaginez que votre site a 20 000 pages.
Mais que seulement 5 000 ont une vraie valeur SEO.
Vous voulez que Google les explore et les indexe en priorité.
La solution : utilisez le fichier robots.txt pour désactiver les explorations à faible valeur.
Résultat ?
Un crawl plus concentré, plus utile.
Faites-le en combinant les directives Disallow avec une bonne optimisation de votre maillage interne.
Vous concentrez ainsi votre budget de crawl sur les pages qui génèrent du trafic.
En pratique, qu’est-ce que vous devriez faire ?
Et posez-vous toujours une question simple : est-ce que cette page mérite vraiment que Google la visite régulièrement ?
Si la réponse est non, ajoutez-la au fichier robots.txt.
Un sitemap XML liste toutes les pages que vous voulez rendre visibles à Google.
C’est un plan du site clair et organisé.
Le moteur l’utilise pour mieux comprendre la structure de votre site dès l’arrivée du robot.
Contrairement à ce qu’on pourrait croire, Google ne découvre pas tout tout seul.
Le sitemap l’aide à trouver des pages profondes ou peu liées en interne.
Il permet aussi d’indiquer la fréquence de mise à jour, la date de modification et la priorité des pages.
Et oui, tout ça part d’un simple fichier XML.
Avec un sitemap bien fait, vous dites à Googlebot où il doit aller en priorité.
Vous choisissez ce qu’il doit explorer d’abord.
Vous poussez en avant vos pages stratégiques.
Plus vous avez de pages, plus ce ciblage devient utile.
Vous ne voulez pas gaspiller votre budget de crawl sur des pages sans valeur.
Utilisez le champ <priority> pour indiquer que certaines pages comptent plus que d’autres.
Google en tient parfois compte même s’il ne le garantit pas.
Dans tous les cas, ça aide à structurer vos intentions.
N’oubliez pas de bien mentionner votre sitemap dans le fichier robots.txt.
Et surtout, envoyez-le dans Google Search Console.
Ne le laissez pas traîner dans un coin du serveur.
Un sitemap à jour garantit que Google voit vos modifications dès qu’elles arrivent.
Vous ajoutez une nouvelle page ?
Vous supprimez une URL ?
Ça doit se voir dans le fichier.
Pas besoin de tout refaire à la main à chaque fois.
Servez-vous d’un CMS avec un plugin de génération automatique.
WordPress, Magento, Prestashop le permettent.
Et pensez à inclure la balise <lastmod>.
Elle montre la date de dernière modification.
Elle donne une info précieuse à Google pour déclencher un nouveau crawl.
Vous gérez un site e-commerce ou média avec beaucoup de renouvellement ?
Segmentez vos sitemaps par typologie : pages produits, articles, catégories.
Ça limite le poids du fichier.
Et pour orienter encore mieux le crawl :
En guidant Google sur le bon chemin, vous économisez du budget de crawl et accélérez l’indexation de ce qui compte vraiment.
Un fichier log serveur enregistre chaque requête HTTP que votre serveur reçoit.
Ça inclut toutes les visites, même celles du Googlebot.
Vous y trouvez :
Ce dernier vous dit si c’est Googlebot, Bingbot ou un utilisateur classique.
Sans ces logs, vous pilotez votre SEO à l’aveugle.
Avec eux, vous voyez comment Google explore votre site, en temps réel.
Les logs vous montrent quand et à quelle fréquence Google explore chaque URL.
Vous voyez si certaines pages sont crawlées tous les jours ou juste une fois par mois.
Vous repérez aussi les heures où Googlebot est le plus actif.
Ce pic correspond souvent aux moments où votre site est le plus disponible, donc rapide.
Une analyse bien faite vous révèle aussi les types de contenus que Google préfère.
Par exemple, des pages produits, des articles ou des filtres de recherche.
Vous remarquez que Googlebot passe trop de temps sur des pages peu utiles ?
Comme des pages de tri ou de pagination ?
Ou au contraire, qu’il ignore des sections clés comme des pages de catégorie optimisées SEO ?
Le log vous le dit clairement.
Vous ajustez ensuite vos liens internes, vos fichiers robots.txt ou votre stratégie de maillage pour corriger le tir.
Avec ces outils, vous visualisez les zones efficaces et manquantes du crawl :
Vous passez d’une approche théorique à une stratégie basée sur des données concrètes.
Alors, prêt à écouter ce que votre serveur a à vous dire ?
Googlebot n’aime pas perdre son temps.
Quand il tombe sur plusieurs pages identiques ou très similaires, il gaspille son énergie à crawler du contenu inutile.
Résultat direct : vos vraies pages stratégiques attendent leur tour.
Google passe à côté, car il croit avoir déjà tout vu.
D’abord, vous perdez du budget de crawl.
Chaque passage sur une page copiée, c’est une autre page ignorée.
Ensuite, vous diluez votre autorité.
Google ne sait plus quelle version mérite d’être bien positionnée.
Tout le monde y perd.
Vous risquez aussi de créer de la confusion chez l’algorithme.
Il passe du temps à choisir entre deux versions au lieu d’explorer des pages uniques.
Vous pouvez commencer avec des outils comme Screaming Frog, Sitebulb ou Google Search Console.
Observez les patterns d’URL.
La pagination, les sessions, les filtres peuvent générer des doublons à la chaîne.
Utilisez aussi les logs serveur pour voir si Googlebot revient sans arrêt sur les mêmes structures d’URL sans intérêt.
Intégrez des balises canoniques sur toutes les pages dupliquées, elles indiquent clairement à Google la version principale.
Gérer vos paramètres d’URL depuis Google Search Console et filtrez les valeurs qui créent plusieurs versions inutiles de la même page.
Limitez la pagination excessive car chaque page de catégorie avec des listes infinies peut multiplier le contenu similaire.
Posez-vous une question simple : est-ce que cette page apporte quelque chose que les autres ne disent pas déjà ?
Si la réponse est non, c’est sûrement une duplication.
Et ça vous coûte du crawl que vous pourriez mieux investir ailleurs.
Google aime ce qui bouge.
Si vous mettez du contenu à jour régulièrement, Googlebot viendra plus souvent.
Il scanne plus fréquemment les pages qui évoluent.
Et ça, ça fait clairement une différence sur votre performance SEO.
Plus une page change, plus elle attire Googlebot.
Ce n’est pas une intuition, c’est ce que montre l’analyse des logs serveur sur des sites à fort trafic.
Google suit un modèle d’apprentissage.
Il détecte la fréquence normale de mise à jour.
Si vous l’augmentez, il s’adapte.
Google reconnaît les sites bien entretenus.
Vous n’avez pas besoin de publier tous les jours.
Mais si vous publiez tous les mardis, tenez ce rythme.
Mettez à jour vos pages piliers tous les 3 ou 6 mois.
Rafraîchissez les données, actualisez les exemples, ajustez les liens.
La régularité donne des signaux de confiance.
Mettez aussi à jour vos pages qui performent déjà.
Vous n’avez pas besoin de tout réécrire.
Corrigez les petites erreurs.
Ajoutez des chiffres récents.
Supprimez les infos obsolètes.
Dans la Search Console, ouvrez une URL du site.
Regardez la « Dernière date d’exploration ».
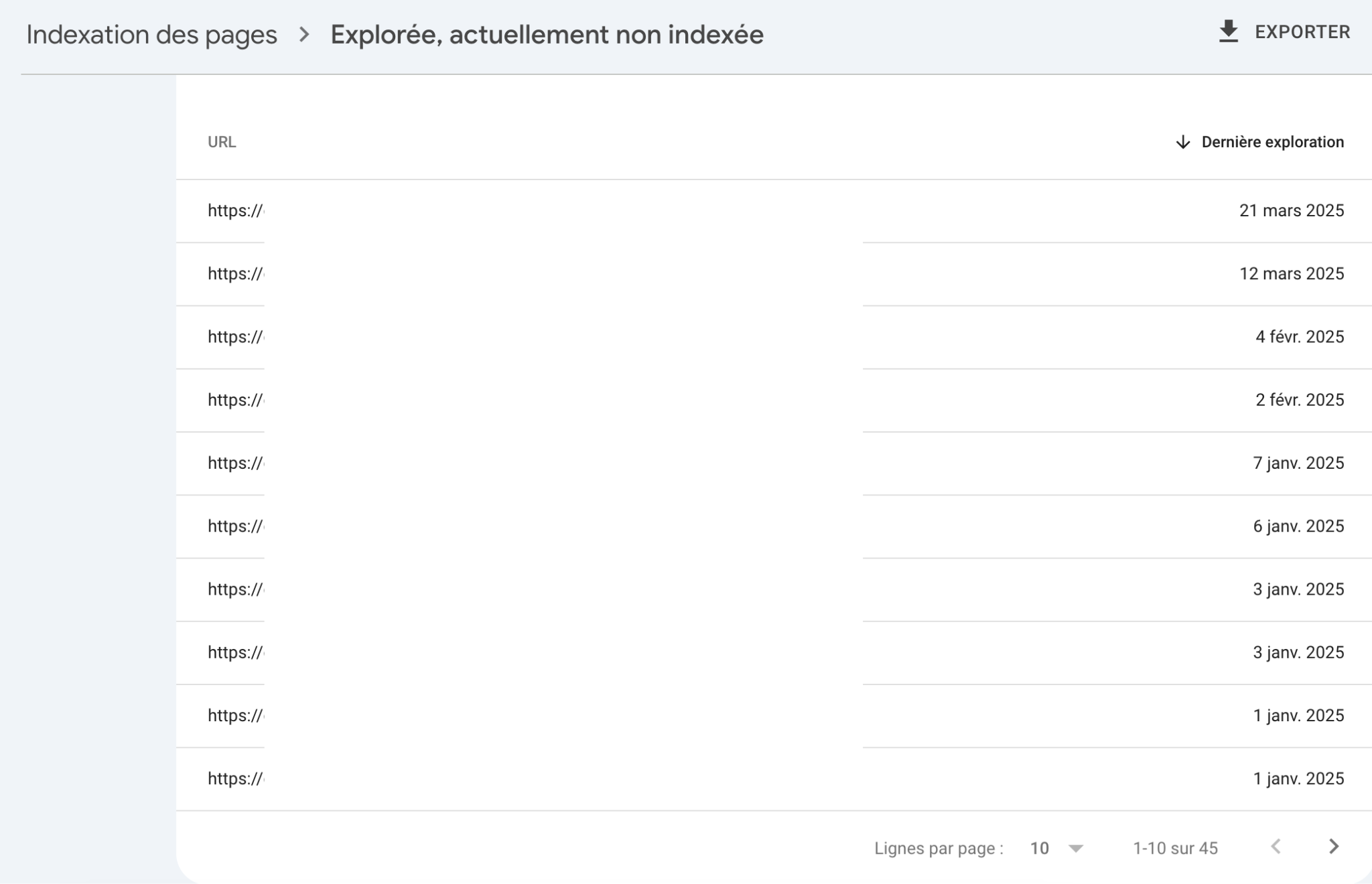
Vous verrez à quand remonte la dernière visite du robot de Google.
Vous dépistez direct les pages oubliées.
Celles qui ne sont pas mises à jour depuis des années n’attirent plus Googlebot.
Identifiez les contenus qui stagnent.
S’ils ont du potentiel, relancez-les.
Ajoutez du texte, repensez les méta données, changez l’intro.
Et surveillez la date de crawl.
Si elle change dans les jours qui suivent, c’est gagné.
Vous avez relancé la machine.
Vous voulez une preuve rapide que vos efforts paient ?
Comparez l’évolution du trafic organique sur 30 jours après la mise à jour.
Un pic dans les impressions = Google a bien capté le signal.
Google ne peut pas tout explorer.
Vous devez donc lui montrer ce qui compte vraiment.
Commencez par repérer les pages qui génèrent le plus de valeur.
Par valeur, pensez à celles qui attirent du trafic, qui convertissent ou qui reçoivent des backlinks de qualité.
Vous avez du mal à trancher ?
Servez-vous de Google Analytics ou de Search Console.
Regardez les pages qui performent en SEO.
Repérez celles qui rapportent des ventes ou des leads.
Étudiez celles qui reçoivent des liens.
Donnez une logique claire à votre site.
Plus votre structure est cohérente, plus Google comprend vite où aller.
Organisez vos pages par catégories.
Placez les pages les plus stratégiques en haut de votre arborescence.
Les pages profondes prennent plus de temps à explorer.
Et souvent, Google les ignore.
Regroupez les contenus proches dans une même thématique.
Créez des silos.
Chaque silo pousse les pages les plus fortes vers le haut.
Vous facilitez la vie des bots en même temps que celle des visiteurs.
Le sitemap XML vous aide à guider Google.
Ajoutez-y la balise priority.
Cette balise signale quelles pages méritent plus d’attention.
Par exemple, fixez une priorité à 1 pour votre page d’accueil ou vos pages produits stratégiques.
Donnez 0.5 à des pages secondaires.
Voilà une manière directe d’influencer le crawl.
Attention, cette balise ne donne pas d’ordre absolu.
Google reste libre de suivre ses propres règles.
Mais si tout est cohérent (popularité de la page, liens internes, mises à jour), il respectera la hiérarchie que vous indiquez.
Si vous ne l’utilisez pas encore, c’est le moment de tester l’impact sur l’exploration.
Vous pourriez découvrir des surprises intéressantes dans vos logs.
Google ne découvre pas vos pages par magie.
Il suit les liens, tout simplement.
Un bon maillage interne aide les robots à mieux naviguer sur votre site.
Ça signifie qu’ils gaspillent moins de budget de crawl et atteignent plus facilement les pages que vous voulez référencer.
Vous facilitez leur travail, ils explorent plus intelligemment.
Vos pages les plus visitées ont du poids.
Utilisez-les comme des autoroutes pour diriger les robots vers des pages plus profondes.
Pas besoin de sur-optimiser.
Il suffit de penser logique.
Cette stratégie dilue l’autorité de façon plus équilibrée et dope la visibilité des pages négligées.
Certaines pages piègent les robots sans qu’on le voie venir.
On les appelle les “trap pages”. D’autres multiplient les redirections jusqu’à créer des boucles.
Résultat : gaspillage pur de budget de crawl.
Vous gardez le contrôle sur la route des robots. Et vous maximisez ce qu’ils découvrent.
Si la réponse dépasse 3, vous avez du travail.
Testez votre arborescence, repartez de vos pages les plus fortes et tirez un fil vers celles que Google oublie trop souvent.
Un maillage sans logique, c’est comme un GPS sans signal.
Vous perdez du monde en route, y compris les robots.
Google suit les deux types de redirection, mais il ne les traite pas de la même façon.
Une redirection 301 dit clairement que l’ancienne URL est remplacée par la nouvelle.
Google transfère l’autorité de l’URL et met à jour l’index plus vite.
Une 302 signale un changement temporaire.
Google garde l’ancienne URL dans l’index plus longtemps.
Résultat : il continue de la crawler inutilement.
Si vous utilisez des 302 partout sur un site migré, Google va perdre un temps fou à explorer d’anciennes adresses.
Vous gaspillez du budget de crawl sur des pages qui ne servent plus à rien.
Une chaîne de redirection, c’est quand une URL redirige vers une autre qui redirige encore ailleurs, comme : A → B → C → D.
Chaque clic de redirection demande un appel serveur supplémentaire.
Googlebot devra suivre toutes ces étapes pour arriver à l’URL finale.
Résultat : la plupart des pages situées au bout de ces chaînes reçoivent moins de crawl.
Certaines sont même ignorées.
Pire encore, une boucle empêche Googlebot d’arriver quelque part.
Comme quand A redirige vers B qui renvoie vers A.
Google se perd et arrête l’exploration.
La page disparaît de l’index.
Ces cas bouffent du crawl sans produire de valeur.
À grande échelle, ils plombent l’indexation du site entier.
Commencez simplement : testez vos redirections avec Screaming Frog ou Sitebulb.
Activez le mode « list » et entrez les URLs suspicieuses.
Ahrefs et Semrush signalent aussi les chaînes dans leurs audits.
Repérez les cas où plus de 3 redirections s’enchaînent.
Allez dans la Google Search Console, section “Crawl stats”.
Un pic dans les pages redirigées indique un souci.
Corrigez les chaînes en redirigeant directement A vers D.
Supprimez les 302 si la redirection est permanente.
Et vérifiez qu’aucune page ne forme une boucle.
Moins il y a de redirections inutiles, plus Googlebot explore les vraies pages utiles.
Vous avez vu comment le budget de crawl influence la façon dont Google explore votre site.
Chaque action que vous mettez en place peut améliorer ou limiter cette exploration.
Si vous gérez un gros site, vous devez absolument savoir quelles pages Googlebot visite, combien de fois, et pourquoi ça coince parfois.
Utilisez vos logs serveur.
Analysez vos fichiers sitemap.
Nettoyez votre maillage.
Supprimez les erreurs et les redirections en cascade.
Posez-vous une question simple : est-ce que Google passe son temps à crawler les bonnes pages ?
Si la réponse est “non” ou “je ne sais pas”, alors agissez maintenant.
Commencez par ces trois actions :
Si vous êtes consultant SEO, ne laissez pas vos recommandations dormir dans un fichier Excel.
Priorisez.
Suivez les modifications.
Revenez dans 3 mois et mesurez les effets.
Plus votre site grandit, plus vous devez surveiller ce budget comme un comptable veille sur ses centimes.
Alors, prêt à reprendre le contrôle du crawl de votre site ?
Formation SEO et stratégies de référencement
naturel avancées

Laisser un commentaire